Physicists like my Smart Software co-founder, Dr. Nelson Hartunian, tell us civilians that everything is different when we drill down to the tiniest level of the world. Physics at the quantum level is quite weird – not at all like what we experience in our usual macroscopic life. Among the oddities are “superposition”, “entanglement”, and “quantum foam.” Weird as these phenomena are, I cannot help seeing analogs in the supposedly different world of supply chain management.
Consider quantum superposition. Briefly, superposition means any quantum entity can be in two states at once. Schrödinger’s cat is the most famous illustration of this idea. But how many of you readers are also in a state of superposition? Don’t you find yourself being a manager of a team yet a member of your supervisor’s team, a trouble-shooter yet also a forecasting expert or an inventory optimizer and…? And doesn’t all this make you sometimes feel, like that cat, that you are simultaneously both dead and alive? Modern software can ease some of this burden by automating the tasks of demand planning and inventory optimization. The rest is up to you.
A second quantum analog is entanglement. Briefly, entanglement is the linkage between two elements of a system. They can be light years apart, yet changing one part of an entangled system will instantaneously change the other part. This bugged Albert Einstein, who derided it as “spooky action as a distance.” In our regular world, demand planning and inventory optimization are entangled, since the process of inventory optimization sits on top of the process of demand forecasting. Modern software links the two in an efficient interface.
Finally, the quantum foam – one of my favorite ideas. As I understand it, quantum foam is a substitute for empty space: there is no empty space, rather a constant bubbling of “vacuum energy” accompanied by a flux of “virtual particles” being born out of nothing and then disappearing back into nothing. In the supply chain world, the analogs of virtual particles are customer orders. Often it seems that they pop up with no warning out of thin air, and sometimes they disappear by cancellation in an equally random and mysterious process. This kind of demand fluctuation is the basis for all the theory of inventory control. Modern software therefore begins with probability models of customer demand. Those models then have implications for such tangible quantities as safety stocks, reorder points, and order quantities.
Does it really help demand planners and inventory managers to think about these ideas from quantum physics? Well, it’s a bit of fun to see the analogies to our regular world of work. And they do remind us of more macroscopic matters: the basic concepts of the need to deal with more than one task simultaneously, the linkage between forecasting and inventory management, and randomness as the fundamental feature of the supply chain.

Related Posts

How Are We Doing? KPI’s and KPP’s
Dealing with the day-to-day of inventory management can keep you busy. But you know you have to get your head up now and then to see where you’re heading. For that, your inventory software should show you metrics – and not just one, but a full set of metrics or KPI’s – Key Performance Indicators.

What is Inventory Planning? A Brief Dictionary of Inventory-Related Terms
People involved in the supply chain are likely to have questions about various inventory terms and methods used in their jobs. This note may help by explaining these terms and showing how they relate.

Confused about AI and Machine Learning?
Are you confused about what is AI and what is machine learning? Are you unsure why knowing more will help you with your job in inventory planning? Don’t despair. You’ll be ok, and we’ll show you how some of whatever-it-is can be useful.
Recent Posts
 Managing Spare Parts Inventory: Best PracticesIn this blog, we’ll explore several effective strategies for managing spare parts inventory, emphasizing the importance of optimizing stock levels, maintaining service levels, and using smart tools to aid in decision-making. Managing spare parts inventory is a critical component for businesses that depend on equipment uptime and service reliability. Unlike regular inventory items, spare parts often have unpredictable demand patterns, making them more challenging to manage effectively. An efficient spare parts inventory management system helps prevent stockouts that can lead to operational downtime and costly delays while also avoiding overstocking that unnecessarily ties up capital and increases holding costs. […]
Managing Spare Parts Inventory: Best PracticesIn this blog, we’ll explore several effective strategies for managing spare parts inventory, emphasizing the importance of optimizing stock levels, maintaining service levels, and using smart tools to aid in decision-making. Managing spare parts inventory is a critical component for businesses that depend on equipment uptime and service reliability. Unlike regular inventory items, spare parts often have unpredictable demand patterns, making them more challenging to manage effectively. An efficient spare parts inventory management system helps prevent stockouts that can lead to operational downtime and costly delays while also avoiding overstocking that unnecessarily ties up capital and increases holding costs. […] 5 Ways to Improve Supply Chain Decision SpeedThe promise of a digital supply chain has transformed how businesses operate. At its core, it can make rapid, data-driven decisions while ensuring quality and efficiency throughout operations. However, it's not just about having access to more data. Organizations need the right tools and platforms to turn that data into actionable insights. This is where decision-making becomes critical, especially in a landscape where new digital supply chain solutions and AI-driven platforms can support you in streamlining many processes within the decision matrix. […]
5 Ways to Improve Supply Chain Decision SpeedThe promise of a digital supply chain has transformed how businesses operate. At its core, it can make rapid, data-driven decisions while ensuring quality and efficiency throughout operations. However, it's not just about having access to more data. Organizations need the right tools and platforms to turn that data into actionable insights. This is where decision-making becomes critical, especially in a landscape where new digital supply chain solutions and AI-driven platforms can support you in streamlining many processes within the decision matrix. […] 12 Causes of Overstocking and Practical SolutionsManaging inventory effectively is critical for maintaining a healthy balance sheet and ensuring that resources are optimally allocated. Here is an in-depth exploration of the main causes of overstocking, their implications, and possible solutions. […]
12 Causes of Overstocking and Practical SolutionsManaging inventory effectively is critical for maintaining a healthy balance sheet and ensuring that resources are optimally allocated. Here is an in-depth exploration of the main causes of overstocking, their implications, and possible solutions. […] FAQ: Mastering Smart IP&O for Better Inventory Management.Effective supply chain and inventory management are essential for achieving operational efficiency and customer satisfaction. This blog provides clear and concise answers to some basic and other common questions from our Smart IP&O customers, offering practical insights to overcome typical challenges and enhance your inventory management practices. Focusing on these key areas, we help you transform complex inventory issues into strategic, manageable actions that reduce costs and improve overall performance with Smart IP&O. […]
FAQ: Mastering Smart IP&O for Better Inventory Management.Effective supply chain and inventory management are essential for achieving operational efficiency and customer satisfaction. This blog provides clear and concise answers to some basic and other common questions from our Smart IP&O customers, offering practical insights to overcome typical challenges and enhance your inventory management practices. Focusing on these key areas, we help you transform complex inventory issues into strategic, manageable actions that reduce costs and improve overall performance with Smart IP&O. […] 7 Key Demand Planning Trends Shaping the FutureDemand planning goes beyond simply forecasting product needs; it's about ensuring your business meets customer demands with precision, efficiency, and cost-effectiveness. Latest demand planning technology addresses key challenges like forecast accuracy, inventory management, and market responsiveness. In this blog, we will introduce critical demand planning trends, including data-driven insights, probabilistic forecasting, consensus planning, predictive analytics, scenario modeling, real-time visibility, and multilevel forecasting. These trends will help you stay ahead of the curve, optimize your supply chain, reduce costs, and enhance customer satisfaction, positioning your business for long-term success. […]
7 Key Demand Planning Trends Shaping the FutureDemand planning goes beyond simply forecasting product needs; it's about ensuring your business meets customer demands with precision, efficiency, and cost-effectiveness. Latest demand planning technology addresses key challenges like forecast accuracy, inventory management, and market responsiveness. In this blog, we will introduce critical demand planning trends, including data-driven insights, probabilistic forecasting, consensus planning, predictive analytics, scenario modeling, real-time visibility, and multilevel forecasting. These trends will help you stay ahead of the curve, optimize your supply chain, reduce costs, and enhance customer satisfaction, positioning your business for long-term success. […]

Inventory Optimization for Manufacturers, Distributors, and MRO
- Managing Spare Parts Inventory: Best PracticesIn this blog, we’ll explore several effective strategies for managing spare parts inventory, emphasizing the importance of optimizing stock levels, maintaining service levels, and using smart tools to aid in decision-making. Managing spare parts inventory is a critical component for businesses that depend on equipment uptime and service reliability. Unlike regular inventory items, spare parts often have unpredictable demand patterns, making them more challenging to manage effectively. An efficient spare parts inventory management system helps prevent stockouts that can lead to operational downtime and costly delays while also avoiding overstocking that unnecessarily ties up capital and increases holding costs. […]
 Innovating the OEM Aftermarket with AI-Driven Inventory OptimizationThe aftermarket sector provides OEMs with a decisive advantage by offering a steady revenue stream and fostering customer loyalty through the reliable and timely delivery of service parts. However, managing inventory and forecasting demand in the aftermarket is fraught with challenges, including unpredictable demand patterns, vast product ranges, and the necessity for quick turnarounds. Traditional methods often fall short due to the complexity and variability of demand in the aftermarket. The latest technologies can analyze large datasets to predict future demand more accurately and optimize inventory levels, leading to better service and lower costs. […]
Innovating the OEM Aftermarket with AI-Driven Inventory OptimizationThe aftermarket sector provides OEMs with a decisive advantage by offering a steady revenue stream and fostering customer loyalty through the reliable and timely delivery of service parts. However, managing inventory and forecasting demand in the aftermarket is fraught with challenges, including unpredictable demand patterns, vast product ranges, and the necessity for quick turnarounds. Traditional methods often fall short due to the complexity and variability of demand in the aftermarket. The latest technologies can analyze large datasets to predict future demand more accurately and optimize inventory levels, leading to better service and lower costs. […] Future-Proofing Utilities: Advanced Analytics for Supply Chain OptimizationUtilities in the electrical, natural gas, urban water, and telecommunications fields are all asset-intensive and reliant on physical infrastructure that must be properly maintained, updated, and upgraded over time. Maximizing asset uptime and the reliability of physical infrastructure demands effective inventory management, spare parts forecasting, and supplier management. A utility that executes these processes effectively will outperform its peers, provide better returns for its investors and higher service levels for its customers, while reducing its environmental impact. […]
Future-Proofing Utilities: Advanced Analytics for Supply Chain OptimizationUtilities in the electrical, natural gas, urban water, and telecommunications fields are all asset-intensive and reliant on physical infrastructure that must be properly maintained, updated, and upgraded over time. Maximizing asset uptime and the reliability of physical infrastructure demands effective inventory management, spare parts forecasting, and supplier management. A utility that executes these processes effectively will outperform its peers, provide better returns for its investors and higher service levels for its customers, while reducing its environmental impact. […] Centering Act: Spare Parts Timing, Pricing, and ReliabilityIn this article, we'll walk you through the process of crafting a spare parts inventory plan that prioritizes availability metrics such as service levels and fill rates while ensuring cost efficiency. We'll focus on an approach to inventory planning called Service Level-Driven Inventory Optimization. Next, we'll discuss how to determine what parts you should include in your inventory and those that might not be necessary. Lastly, we'll explore ways to enhance your service-level-driven inventory plan consistently. […]
Centering Act: Spare Parts Timing, Pricing, and ReliabilityIn this article, we'll walk you through the process of crafting a spare parts inventory plan that prioritizes availability metrics such as service levels and fill rates while ensuring cost efficiency. We'll focus on an approach to inventory planning called Service Level-Driven Inventory Optimization. Next, we'll discuss how to determine what parts you should include in your inventory and those that might not be necessary. Lastly, we'll explore ways to enhance your service-level-driven inventory plan consistently. […]
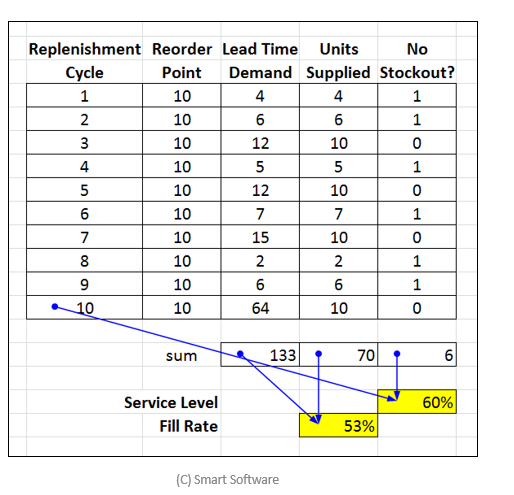 Forecasting is a means to an end. The end is to optimize inventory levels. Because demand is uncertain, companies that need to provide even moderate service levels must stock more than the forecast, often much more. But doesn’t low forecast error mean lower safety stock? The better my forecasts, the lower my inventory? Yes, true. But what matters when determining the required inventory are both accurate forecasts of the most likely demand and accurate estimates of the variability around the most likely demand.
Forecasting is a means to an end. The end is to optimize inventory levels. Because demand is uncertain, companies that need to provide even moderate service levels must stock more than the forecast, often much more. But doesn’t low forecast error mean lower safety stock? The better my forecasts, the lower my inventory? Yes, true. But what matters when determining the required inventory are both accurate forecasts of the most likely demand and accurate estimates of the variability around the most likely demand.


