
To test software solutions via a series of empirical competition can be a considerable option. For forecasting / demand planning, a traditional “hold out” test in which 2014-2018 data are provided to software vendors and 2019 is held out for later comparison against forecasts provided by competing vendors. The company then measures forecast error and bias. This approach is advocated nearly universally for assessing forecast accuracy. It’s a good way to assess monthly or weekly forecast accuracy, but it is minimally useful if you have a different objective: Optimizing inventory.
In our last blog, we discussed how to pick a targeted service level. We indicated that just because you set a target (or a system recommends a target) doesn’t mean you’ll actually achieve the target. The right way to measure accuracy if you are interested in optimizing stock levels is to focus on the accuracy of the service level projection. This will account for both lead time demand and safety stock.
Setting a target service level is a strategic decision about inventory risk management. Inventory software does the tactical work by computing reorder points (a.k.a. mins) meant to achieve a user-defined target or that will achieve a system-calculated optimal target. But if the software uses the wrong demand model, the achieved service level will miss the target, sometimes significantly. The result of this error will be either shortages or inventory bloat, depending on the direction of the miss.
 Forecasting is a means to an end. The end is to optimize inventory levels. Because demand is uncertain, companies that need to provide even moderate service levels must stock more than the forecast, often much more. But doesn’t low forecast error mean lower safety stock? The better my forecasts, the lower my inventory? Yes, true. But what matters when determining the required inventory are both accurate forecasts of the most likely demand and accurate estimates of the variability around the most likely demand.
Forecasting is a means to an end. The end is to optimize inventory levels. Because demand is uncertain, companies that need to provide even moderate service levels must stock more than the forecast, often much more. But doesn’t low forecast error mean lower safety stock? The better my forecasts, the lower my inventory? Yes, true. But what matters when determining the required inventory are both accurate forecasts of the most likely demand and accurate estimates of the variability around the most likely demand.
Especially with long tailed, intermittent demand, traditional forecast accuracy assessments over a conventional 12 month forecast horizon miss the point three ways.
– First, the relevant time scale for inventory optimization is the replenishment lead time, which is usually much shorter than 12 months. Demand during lead times measured in days or weeks has volatility that gets averaged out over long forecast horizons. This is bad because factoring in the effect of volatility is essential to calculation of optimal reorder points.
– Second, forecast accuracy assessed over a multi-month forecast horizon focuses on the typical error in a typical month within the horizon. In contrast, inventory optimization requires a focus on cumulative demand, not period-by-period demand.
– Third, and most important is that forecast error metrics are focused on the middle of the demand distribution, aiming to estimate the most likely demand. But setting reorder points involves estimating high percentiles of the cumulative demand distribution over a lead time. Estimating the middle a bit better but having no clue about, say, the 95th percentile, is not helpful.
Consider this hypothetical example. If Vendor A forecasts 20 units with 110% error and Vendor B forecasts 22 units with 105% error, then Vendor B has an advantage in the forecasting game. But if you want a high service level and the demand is intermittent, you’ll have to stock a lot more than 20 or 22 units. Let’s assume you select Vendor B’s technology to plan stocking levels. You then notice that when planning reorder points to achieve a 95% service level, you often fall short – way more often that the expected 5% of the time. You come to realize that Vendor B’s approach completely underestimates the safety stock required to achieve the target service target. Focusing on vendors’ forecast error isn’t going to help. You will come to wish that you had verified Vendor A and B’s service level accuracy. Now you are stuck arbitrarily adjusting Vendor B’s service level targets to compensate for the shortfall.
So what’s needed in vendor competitions is assessment of their systems’ abilities to accurately forecast the inventory required to meet a given service level over an item’s replenishment lead time. Narrowly focusing on measuring forecast error is not appropriate if the mission is managing inventory. This is especially true for long tail items with intermittent demand or items that have medium to high volume but don’t have a demand distribution that looks like the classic “bell shaped curve” (Normal distribution).
The remainder of this blog explains how to test the accuracy of software’s service level calculations, so you can monitor the risk of missing your service level targets. We recommend this accuracy test over traditional “forecast versus actuals” tests because it provides much more insight into how reorder point recommendations will influence inventory levels and customer service.

Office staff are analyzing The Right Forecast Accuracy Metric for Inventory Planning
Service Level Defined
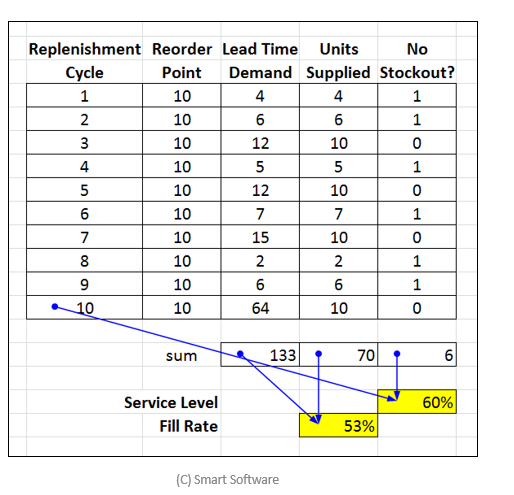
Consider a single inventory item. When inventory drops to or below the reorder point, a replenishment order is generated. This starts a period of risk that lasts as long as the replenishment lead time. During the period of risk, there might be enough incoming demands to create backorders or lost sales. The service level is the probability that there are no backorders or stockouts during the replenishment lead time. Critical items might be given very high target service levels, say 99%, whereas other items might have more relaxed targets, such as 75%. Whatever the target service level, it is best to hit that target.
Calculating Service Level
The service level for an individual item can only be estimated by repeated comparison of observed lead time demand against the calculated reorder point. These estimates take a lot of time: at least dozens of lead times. But fleet-wise service level can be estimated using data compiled over a single lead time.
Let’s do an example. Suppose you have demand histories for 1,000 items over 365 days and that (for simplicity) all items have 45-day lead times. For each item, follow these steps to estimate the fleet-wise achieved service level:
Step 1: Step aside (“hold out”) the most recent 45 days of demand (or however many days is closest to your typical lead times). Compute their sum, which is the most recent value of the actual lead time demand. This is the ground truth to be used to estimate the achieved service level.
Step 2: Use the prior 320 days of demand history to forecast the required inventory to hit a range of service level targets, say 90%, 95%, 97%, and 99%.
Step 3: Check whether the observed lead time demand is less than or equal to the reorder point. If it is, count this as a win; otherwise, count it as a loss. For instance, if the reorder point is 15 units but the most recent lead time demand is 10 units, then this is a win, since the reorder point is high enough to cover a lead time demand of 10 without any shortage. However, if the most recent lead time demand is 18 units, there would be a stockout, and 3 units would either be backordered or counted as lost sales.
Step 4: Working across all items, and all service level targets, tally the percentage of tests for each service level target that resulted in a win. This is the achieved service level. If the target was 90% and 853 of the 1,000 units record a win, then the achieved service level is 85.3%.
Example
Consider a real-world example. The data are daily demand histories of 590 medical supply items used in an internationally famous clinic. For simplicity, we assume each item has a lead time of 45 days. We evaluate target service levels of 70%, 90%, 95% and 99%.
We compare two demand models. The “Normal” model assumes that daily demand has a Normal (“bell-shaped”) distribution. This is the classic assumption used in most introductory textbooks on inventory control and in many software products. Classic though it may be, it is often an inappropriate model of demand for spare parts or supplies. The “Probability Forecast” model takes explicit account of the intermittent nature of demand.
Exhibit 1 shows the results. Column J shows the actual demand over the final 45 observations. The computed reorder points for the Advanced Model are shown in columns L-O. The computed reorder points for the Normal model are not displayed. Columns Q-T and V-Y hold the results of the tests for whether the reorder points were high enough to handle the lead time demands in column J.

The final results (yellow cells) show a clear difference between the Normal and Probability (Advanced) demand models. Both did a good job of hitting the 70% service level target, but estimating higher service levels is a more delicate calculation, and the Probability model does a much better job. For instance, the Normal model’s supposed 99% service level turned out to be only 94.4%, while the Probability model hit the target with a 98.5% achieved service level.
Implications
Utilizing the more accurate method achieved the targeted service level, while the less accurate method did not. If the less accurate method is used then real and costly business decisions will be made on the false assumption that a higher service level will be achieved. For example, if a Service Level Agreement (SLA) is based on these results and a 99% service level is committed to, the supplier would actually be five times more likely to stock out than planned (service level promised = 99% or 1% stockout risk vs. service level achieved = 94.5% or 5.5% stock out risk)! This means financial penalties will be incurred five times more often than expected.
Suppose that planners knew the target service level would not be met but were stuck using an inaccurate model. They would still need a way to increase inventory and achieve the desired level of service. What might they choose to do? We have observed situations where the planner enters a higher service level target than needed in order to “trick” the system into delivering the required service level. In the above example, the Normal model needed to have a 99.99% service level entered before it could achieve a target service level of 99%. This change resulted in achieving a 99% service but more than doubled the inventory investment when compared to the Advanced model.
Implementing a Service Level Accuracy Test
At Smart Software, we’ve encouraged many of our customers to conduct the test of service level accuracy as a way for them to assess our and other vendors’ claims during the software selection process. Missing the service level target has extremely costly implications resulting in substantial over stocks or under stocks. So, test service level accuracy before deploying a solution to identify situations when the modeling fails. Don’t assume that you will achieve the service level you decide to target (or that the system recommends). To request an Excel spreadsheet that serves as a template for a service level accuracy test, email your contact information to info@smartcorp.com and enter “Accuracy Template” in the subject line.

Related Posts

Managing Spare Parts Inventory: Best Practices
In this blog, we’ll explore several effective strategies for managing spare parts inventory, emphasizing the importance of optimizing stock levels, maintaining service levels, and using smart tools to aid in decision-making. Managing spare parts inventory is a critical component for businesses that depend on equipment uptime and service reliability. Unlike regular inventory items, spare parts often have unpredictable demand patterns, making them more challenging to manage effectively. An efficient spare parts inventory management system helps prevent stockouts that can lead to operational downtime and costly delays while also avoiding overstocking that unnecessarily ties up capital and increases holding costs.

12 Causes of Overstocking and Practical Solutions
Managing inventory effectively is critical for maintaining a healthy balance sheet and ensuring that resources are optimally allocated. Here is an in-depth exploration of the main causes of overstocking, their implications, and possible solutions.

FAQ: Mastering Smart IP&O for Better Inventory Management.
Effective supply chain and inventory management are essential for achieving operational efficiency and customer satisfaction. This blog provides clear and concise answers to some basic and other common questions from our Smart IP&O customers, offering practical insights to overcome typical challenges and enhance your inventory management practices. Focusing on these key areas, we help you transform complex inventory issues into strategic, manageable actions that reduce costs and improve overall performance with Smart IP&O.
Recent Posts
 Managing Spare Parts Inventory: Best PracticesIn this blog, we’ll explore several effective strategies for managing spare parts inventory, emphasizing the importance of optimizing stock levels, maintaining service levels, and using smart tools to aid in decision-making. Managing spare parts inventory is a critical component for businesses that depend on equipment uptime and service reliability. Unlike regular inventory items, spare parts often have unpredictable demand patterns, making them more challenging to manage effectively. An efficient spare parts inventory management system helps prevent stockouts that can lead to operational downtime and costly delays while also avoiding overstocking that unnecessarily ties up capital and increases holding costs. […]
Managing Spare Parts Inventory: Best PracticesIn this blog, we’ll explore several effective strategies for managing spare parts inventory, emphasizing the importance of optimizing stock levels, maintaining service levels, and using smart tools to aid in decision-making. Managing spare parts inventory is a critical component for businesses that depend on equipment uptime and service reliability. Unlike regular inventory items, spare parts often have unpredictable demand patterns, making them more challenging to manage effectively. An efficient spare parts inventory management system helps prevent stockouts that can lead to operational downtime and costly delays while also avoiding overstocking that unnecessarily ties up capital and increases holding costs. […] 5 Ways to Improve Supply Chain Decision SpeedThe promise of a digital supply chain has transformed how businesses operate. At its core, it can make rapid, data-driven decisions while ensuring quality and efficiency throughout operations. However, it's not just about having access to more data. Organizations need the right tools and platforms to turn that data into actionable insights. This is where decision-making becomes critical, especially in a landscape where new digital supply chain solutions and AI-driven platforms can support you in streamlining many processes within the decision matrix. […]
5 Ways to Improve Supply Chain Decision SpeedThe promise of a digital supply chain has transformed how businesses operate. At its core, it can make rapid, data-driven decisions while ensuring quality and efficiency throughout operations. However, it's not just about having access to more data. Organizations need the right tools and platforms to turn that data into actionable insights. This is where decision-making becomes critical, especially in a landscape where new digital supply chain solutions and AI-driven platforms can support you in streamlining many processes within the decision matrix. […] 12 Causes of Overstocking and Practical SolutionsManaging inventory effectively is critical for maintaining a healthy balance sheet and ensuring that resources are optimally allocated. Here is an in-depth exploration of the main causes of overstocking, their implications, and possible solutions. […]
12 Causes of Overstocking and Practical SolutionsManaging inventory effectively is critical for maintaining a healthy balance sheet and ensuring that resources are optimally allocated. Here is an in-depth exploration of the main causes of overstocking, their implications, and possible solutions. […] FAQ: Mastering Smart IP&O for Better Inventory Management.Effective supply chain and inventory management are essential for achieving operational efficiency and customer satisfaction. This blog provides clear and concise answers to some basic and other common questions from our Smart IP&O customers, offering practical insights to overcome typical challenges and enhance your inventory management practices. Focusing on these key areas, we help you transform complex inventory issues into strategic, manageable actions that reduce costs and improve overall performance with Smart IP&O. […]
FAQ: Mastering Smart IP&O for Better Inventory Management.Effective supply chain and inventory management are essential for achieving operational efficiency and customer satisfaction. This blog provides clear and concise answers to some basic and other common questions from our Smart IP&O customers, offering practical insights to overcome typical challenges and enhance your inventory management practices. Focusing on these key areas, we help you transform complex inventory issues into strategic, manageable actions that reduce costs and improve overall performance with Smart IP&O. […] 7 Key Demand Planning Trends Shaping the FutureDemand planning goes beyond simply forecasting product needs; it's about ensuring your business meets customer demands with precision, efficiency, and cost-effectiveness. Latest demand planning technology addresses key challenges like forecast accuracy, inventory management, and market responsiveness. In this blog, we will introduce critical demand planning trends, including data-driven insights, probabilistic forecasting, consensus planning, predictive analytics, scenario modeling, real-time visibility, and multilevel forecasting. These trends will help you stay ahead of the curve, optimize your supply chain, reduce costs, and enhance customer satisfaction, positioning your business for long-term success. […]
7 Key Demand Planning Trends Shaping the FutureDemand planning goes beyond simply forecasting product needs; it's about ensuring your business meets customer demands with precision, efficiency, and cost-effectiveness. Latest demand planning technology addresses key challenges like forecast accuracy, inventory management, and market responsiveness. In this blog, we will introduce critical demand planning trends, including data-driven insights, probabilistic forecasting, consensus planning, predictive analytics, scenario modeling, real-time visibility, and multilevel forecasting. These trends will help you stay ahead of the curve, optimize your supply chain, reduce costs, and enhance customer satisfaction, positioning your business for long-term success. […]

Inventory Optimization for Manufacturers, Distributors, and MRO
- Managing Spare Parts Inventory: Best PracticesIn this blog, we’ll explore several effective strategies for managing spare parts inventory, emphasizing the importance of optimizing stock levels, maintaining service levels, and using smart tools to aid in decision-making. Managing spare parts inventory is a critical component for businesses that depend on equipment uptime and service reliability. Unlike regular inventory items, spare parts often have unpredictable demand patterns, making them more challenging to manage effectively. An efficient spare parts inventory management system helps prevent stockouts that can lead to operational downtime and costly delays while also avoiding overstocking that unnecessarily ties up capital and increases holding costs. […]
 Innovating the OEM Aftermarket with AI-Driven Inventory OptimizationThe aftermarket sector provides OEMs with a decisive advantage by offering a steady revenue stream and fostering customer loyalty through the reliable and timely delivery of service parts. However, managing inventory and forecasting demand in the aftermarket is fraught with challenges, including unpredictable demand patterns, vast product ranges, and the necessity for quick turnarounds. Traditional methods often fall short due to the complexity and variability of demand in the aftermarket. The latest technologies can analyze large datasets to predict future demand more accurately and optimize inventory levels, leading to better service and lower costs. […]
Innovating the OEM Aftermarket with AI-Driven Inventory OptimizationThe aftermarket sector provides OEMs with a decisive advantage by offering a steady revenue stream and fostering customer loyalty through the reliable and timely delivery of service parts. However, managing inventory and forecasting demand in the aftermarket is fraught with challenges, including unpredictable demand patterns, vast product ranges, and the necessity for quick turnarounds. Traditional methods often fall short due to the complexity and variability of demand in the aftermarket. The latest technologies can analyze large datasets to predict future demand more accurately and optimize inventory levels, leading to better service and lower costs. […] Future-Proofing Utilities: Advanced Analytics for Supply Chain OptimizationUtilities in the electrical, natural gas, urban water, and telecommunications fields are all asset-intensive and reliant on physical infrastructure that must be properly maintained, updated, and upgraded over time. Maximizing asset uptime and the reliability of physical infrastructure demands effective inventory management, spare parts forecasting, and supplier management. A utility that executes these processes effectively will outperform its peers, provide better returns for its investors and higher service levels for its customers, while reducing its environmental impact. […]
Future-Proofing Utilities: Advanced Analytics for Supply Chain OptimizationUtilities in the electrical, natural gas, urban water, and telecommunications fields are all asset-intensive and reliant on physical infrastructure that must be properly maintained, updated, and upgraded over time. Maximizing asset uptime and the reliability of physical infrastructure demands effective inventory management, spare parts forecasting, and supplier management. A utility that executes these processes effectively will outperform its peers, provide better returns for its investors and higher service levels for its customers, while reducing its environmental impact. […] Centering Act: Spare Parts Timing, Pricing, and ReliabilityIn this article, we'll walk you through the process of crafting a spare parts inventory plan that prioritizes availability metrics such as service levels and fill rates while ensuring cost efficiency. We'll focus on an approach to inventory planning called Service Level-Driven Inventory Optimization. Next, we'll discuss how to determine what parts you should include in your inventory and those that might not be necessary. Lastly, we'll explore ways to enhance your service-level-driven inventory plan consistently. […]
Centering Act: Spare Parts Timing, Pricing, and ReliabilityIn this article, we'll walk you through the process of crafting a spare parts inventory plan that prioritizes availability metrics such as service levels and fill rates while ensuring cost efficiency. We'll focus on an approach to inventory planning called Service Level-Driven Inventory Optimization. Next, we'll discuss how to determine what parts you should include in your inventory and those that might not be necessary. Lastly, we'll explore ways to enhance your service-level-driven inventory plan consistently. […]