People new to the jobs of “demand planner” or “supply planner” are likely to have questions about the various forecasting terms and methods used in their jobs. This note may help by explaining these terms and showing how they relate.
Demand Planning
Demand planning is about how much of what you have to sell will go out the door in the future, e.g., how many what-nots you will sell next quarter. Here are six methodologies often used in demand planning.
- Statistical Forecasting
- These methods use demand history to forecast future values. The two most common methods are curve fitting and data smoothing.
- Curve fitting matches a simple mathematical function, like the equation for a straight line (y= a +b∙t) or an interest-rate type curve (y=a∙bt), to the demand history. Then it extends that line or curve forward in time as the forecast.
- In contrast, data smoothing does not result in an equation. Instead it sweeps through the demand history, averaging values along the way, to create a smoother version of the history. These methods are called exponential smoothing and moving average. In the simplest case (i.e., in the absence of trend or seasonality, for which variants exist), the goal is to estimate the current average level of demand and use that as the forecast.
- These methods produce “point forecasts”, which are single-number estimates for each future time period (e.g., “Sales in March will be 218 units”). Sometimes they come with estimates of potential forecast error bolted on using separate models of demand variability (“Sales in March will be 218 ± 120 units”).
- Probabilistic Forecasting
- This approach keys on the randomness of demand and works hard to estimate forecast uncertainty. It regards forecasting less as an exercise in cranking out specific numbers and more as an exercise in risk management.
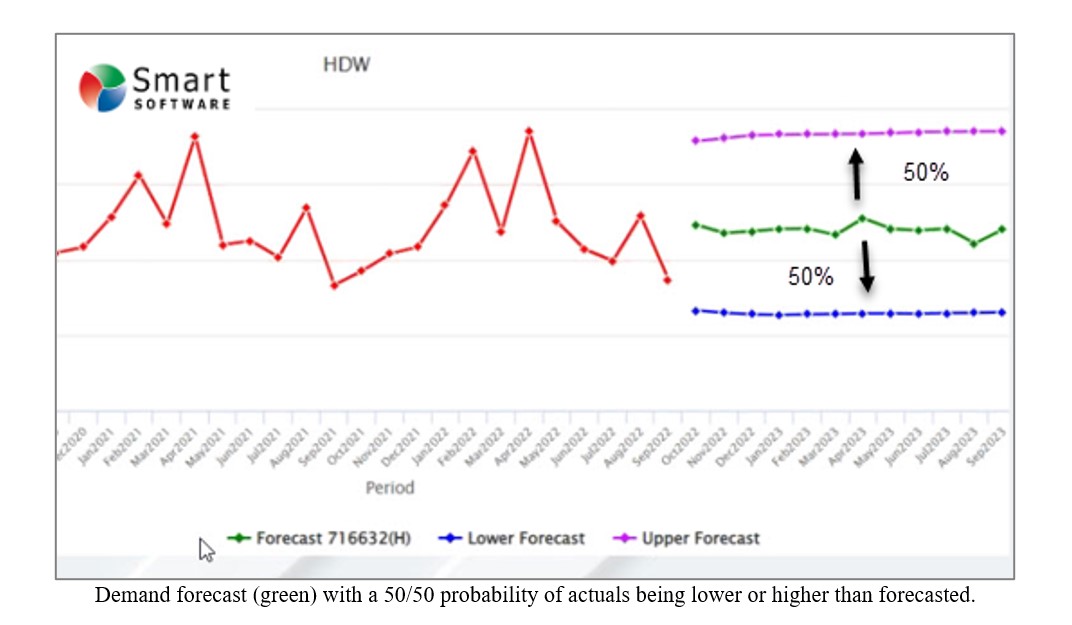
- It explicitly models the variability in demand and uses that to present results in the form of large numbers of scenarios constructed to show the full range of possible demand sequences. These are especially useful in tactical supply planning tasks, such as setting reorder points and order quantities.
- Causal Forecasting
- Statistical forecasting models use as inputs only the past demand history of the item in question. They regard the up-and-down wiggles in the demand plot as the end result of myriad unnamed factors (interest rates, the price of tea in China, phases of the moon, whatever). Causal forecasting explicitly identifies one or more influences (interest rates, advertising spend, competitors’ prices, …) that could plausibly influence sales. Then it builds an equation relating the numerical values of these “drivers” or “causal factors” to item sales. The equation’s coefficients are estimated by “regression analysis”.
- Judgemental Forecasting
- Golden Gut. Despite the general availability of gobs of data, some companies pay little attention to the numbers and give greater weight to the subjective judgements of an executive deemed to have a “Golden Gut”, which allows him or her to use “gut feel” to predict what future demand will be. If that person has great experience, has spent a career actually looking at the numbers, and is not prone to wishful thinking or other forms of cognitive bias, the Golden Gut can be a cheap, fast way to plan. But there is good evidence from studies of companies run this way that relying on the Golden Gut is risky.
- Group Consensus. More common is a process that uses a periodic meeting to create a group consensus forecast. The group will have access to shared objective data and forecasts, but members will also have knowledge of factors that may not be measured well or at all, such as consumer sentiment or the stories relayed by sales reps. It is helpful to have a shared, objective starting point for these discussions consisting of some sort of objective statistical analysis. Then the group can consider adjusting the statistical forecast. This process anchors the forecast in objective reality but exploits all the other information available outside the forecasting database.
- Scenario Generation. Sometimes several people will meet and discuss “strategic what-if” questions. “What if we lose our Australian customers?” “What if our new product roll-out is delayed by six months?” “What if our sales manager for the mid-west jumps to a competitor?” These bigger-picture questions can have implications for item-specific forecasts and might be added to any group-consensus forecasting meeting.
- New product forecasting
- New products, by definition, have no sales history to support statistical, probability, or causal forecasting. Subjective forecasting methods can always be used here, but these often rely on a dangerous ratio of hopes to facts. Fortunately, there is at least partial support for objective forecasting in the form of curve fitting.
- A graph of the cumulative sales of an item often describes some sort of “S-curve”, i.e., a graph that starts at zero, builds up, then levels off to a final lifetime total sales. The curve gets its name because it looks like a letter S somehow smeared and stretched to the right. Now there are an infinite number of S-curves, so forecasters typically pick an equation and subjectively specify some key parameter values, like when sales will hit 25%, 50% and 75% of total lifetime sales and what that final level will be. This is also overtly subjective, but it produces detailed period-by-period forecasts that can be updated as experience builds up. Finally, S-curves are sometimes shaped to match the known history of a similar, predecessor product (“Sales for our last gizmo looked like this, so let’s use that as a template.”).
Supply Planning
Demand planning feeds into supply planning by predicting future sales (e.g., for finished goods) or usage (e.g., for spare parts). Then it is up to supply planning to make sure the items in question will be available to sell or to use.
- Dependent demand
- Dependent demand is demand that can be determined by its relationship to demand for another item. For instance, a bill of materials may show that a little red wagon consists of a body, a pull bar, four wheels, two axles, and various fasteners to keep the wheels on the axles and connect the pull bar to the body. So if you hope to sell 10 little red wagons, you’d better make 10, which means you need 10×2 = 20 axles, 10×4 = 40 wheels, etc. Dependent demand governs raw materials purchasing, component and subsystems purchasing, even personnel hiring (10 wagons need one high-school kid to put them together over a 1 hour shift).
- If you have multiple products with partially overlapping bills of materials, you have a choice of two forecasting approaches. Suppose you sell not only little red wagons but little blue baby carriages and that both use the same axles. To predict the number of axles you need you could (1) predict the dependent demand for axles from each product and add the forecasts or (2) observe the total demand history for axles as its own time series and forecast that separately. Which works better is an empirical question that can be tested.
- Inventory management
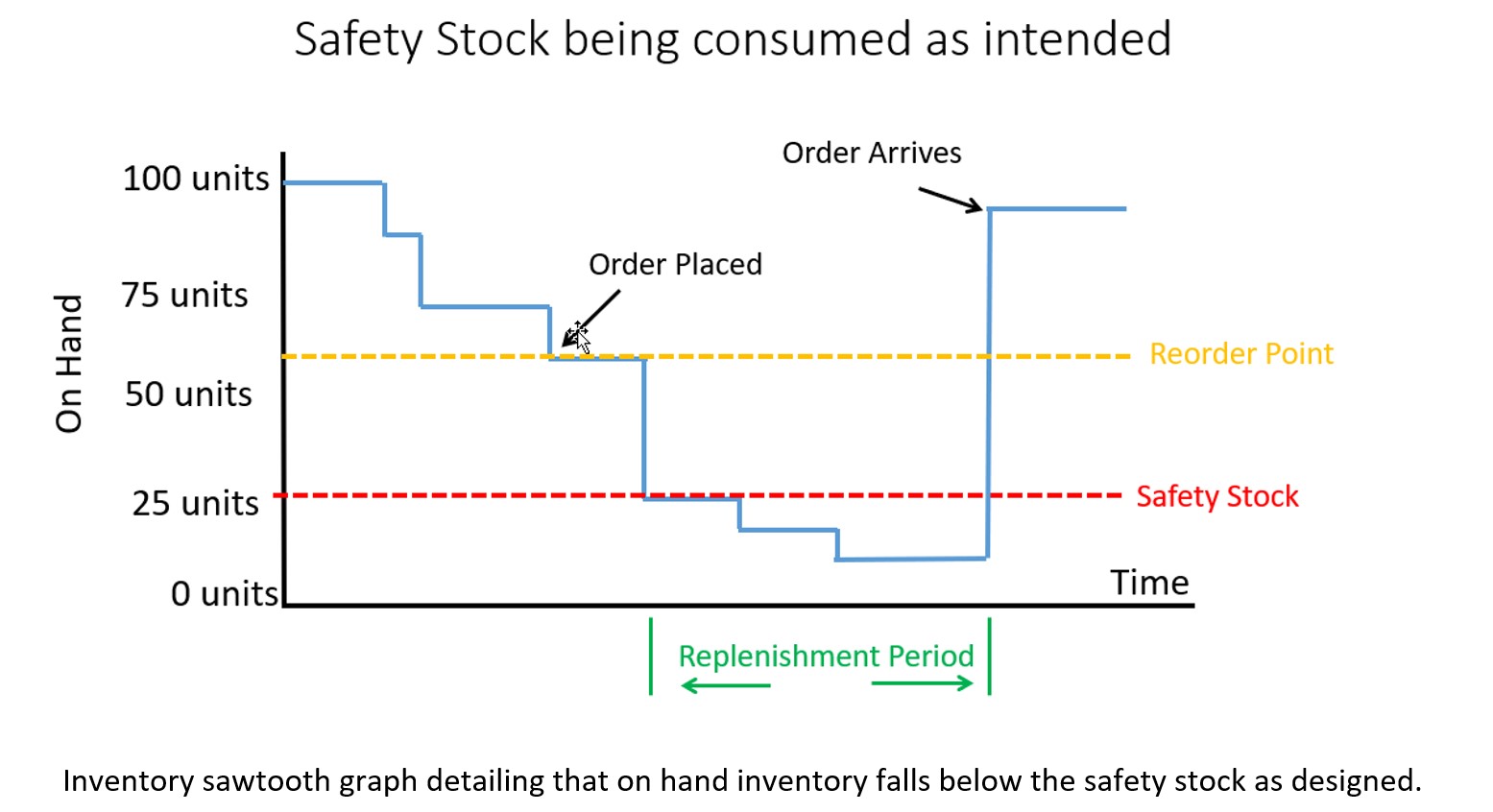
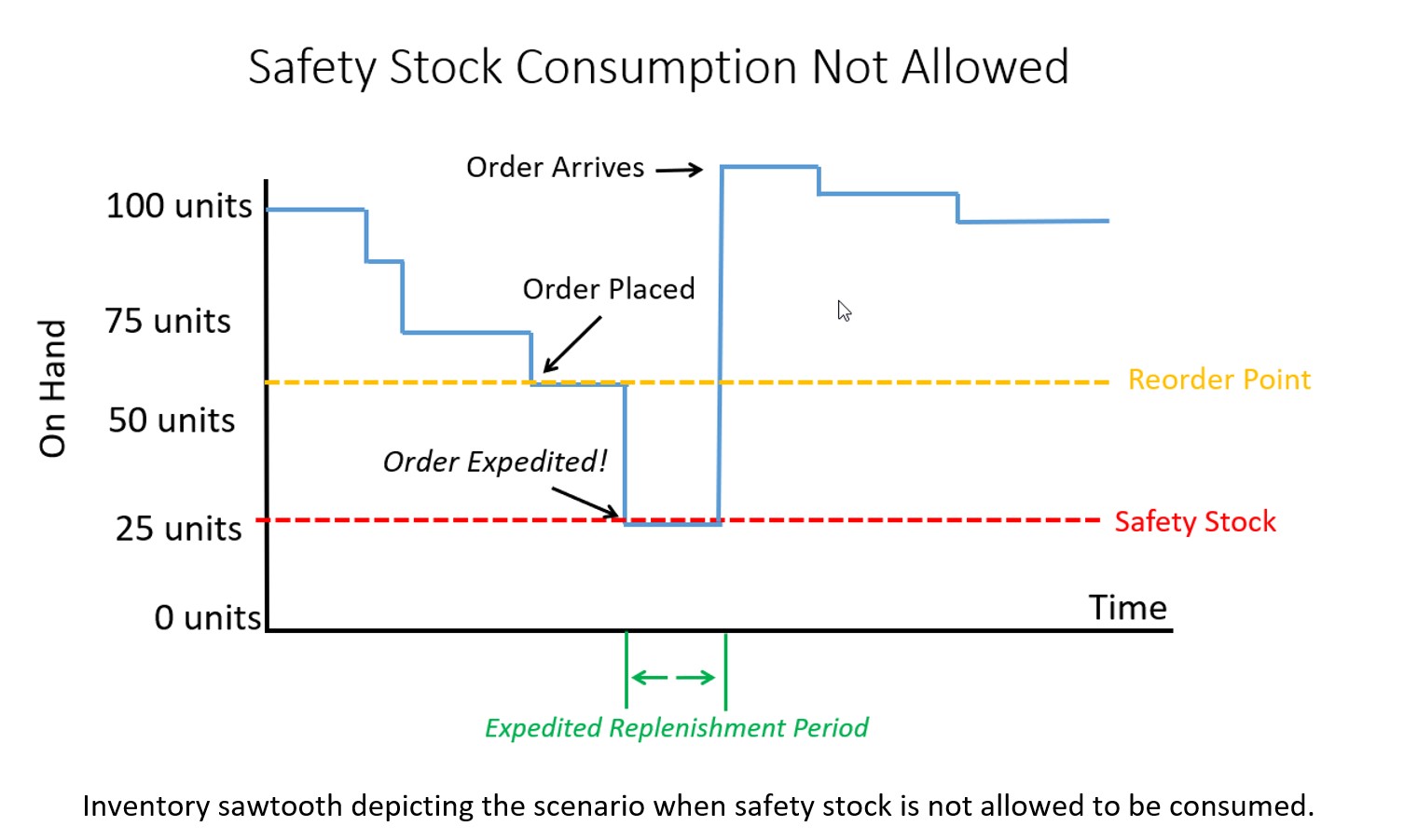
- Inventory management entails many different tasks. These include setting inventory control parameters such as reorder points and order quantities, reacting to contingencies such as stockouts and order expediting, setting staffing levels, and selecting suppliers.
- Forecasting plays a role in the first three. The number of replenishment orders that will be made in a year for each product determines how many people are needed to cut PO’s. The number and severity of stockouts in a year determines the number of contingencies that must be handled. The number of PO’s and stockouts in a year will be random but be governed by the choices of inventory control parameters. The implications of any such choices can be modeled by inventory simulations. These simulations will be driven by detailed demand scenarios generated by probabilistic forecasts.