
In a previous post, I discussed one of the thornier problems demand planners sometimes face: working with product demand data characterized by what statisticians call skewness — a situation that can necessitate costly inventory investments. This sort of problematic data is found in several different scenarios. In at least one, the combination of intermittent demand and very effective sales promotions, the problem lends itself to an effective solution.
Reviewing terms, recall that “service level” is the probability of not stocking out while waiting for a replenishment order to arrive, while “fill rate” is the percentage of demand that is satisfied immediately from stock. In my previous post, “The Scourge of Skewness”, I pointed out that a certain type of demand distribution, having a “long right tail”, will lead to fill rates that can be much lower than service levels. I also pointed out that sometimes the only way to improve the fill rate is to increase the target service level to an unusually high level, which can be expensive.
In this post, I’ll look at solving the problem in one special case: skewness resulting from effective sales promotions mixed with “intermittent demand”. Intermittent demand has a large proportion of zero values, with nonzero values mixed in at random. Successful sales promotions, obviously positive, have a downside: they can confuse the “demand signal” with spikes in your demand history, and can undermine forecasts and bias safety stock calculations. When intermittent demand and effective sales promotions are the source of your data’s skewness, methods exist to work around the problem to achieve both higher fill rates and more accurate demand forecasts.
How Promotions Increase Skewness
Successful promotions abruptly increase item demand. This creates anomalies, or “outliers”, which contribute to forming a skewed distribution. Knowing when promotions occurred in the past, we can adjust an item’s record of past demand. We produce an alternate demand history as if there had been no promotions, by replacing the outliers with values more representative of the “natural” level of demand. These adjustments reduce demand skewness. Reduced skewness can lead to significant reductions in both expected forecasts and safety stocks, which add together to form reorder points.
Successful promotions are likely to be repeated. When that happens, the promotion effects can be added in to demand forecasts to increase their accuracy. The effect of future promotions on inventory management will be to increase the risk of stockouts, so a sensible response is to work at the operational level to build up temporary supply, in a quantity keyed to the estimated impact of prior promotions on the effected items.
Using Event Modeling to Improve Demand Forecasting
It’s possible to model the impact of like events, and apply this to planned events in the future. Doing so can improve your forecast in two big ways: by projecting the demand jolt you expect from a planned event; and rationalizing the spikes in the past that were caused by events, making your baseline activity more visible and more accurately forecastable. We do a lot of this in SmartForecasts, so allow me to use our experience there to show you what I mean.
Event Modeling entails the following steps:
• Automatically estimating the impact of previous promotions (which is a useful result in itself).
• Adjusting historical demand to statistically remove the effect of promotions.
• Creating promotion-free forecasts.
• Revising the forecasts for any future time periods in which promotions are planned.
We call this this type of analysis “Promo forecasting”. We use the word “promotions” to describe what you do yourself to improve your results. We use “events” to describe what the world does to you, usually to your detriment; examples include strikes, power outages, warehouse fires and other unlucky happenings.
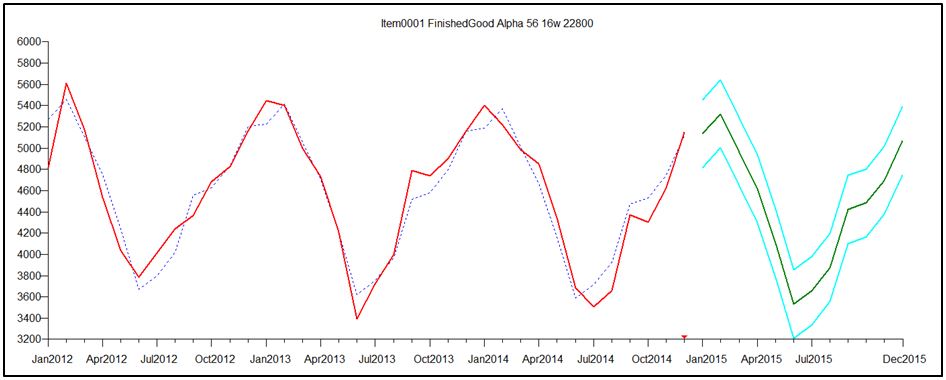
To understand how Event Modeling can help you cope with skewness when doing demand forecasting for high-volume items, consider Figures 1-3.

Figure 1 shows that this item’s demand pattern is clearly seasonal, and the forecast is both seasonal and “tight”, meaning that the forecast uncertainty interval (“margin of error”, shown in cyan lines) is very narrow.

Figure 2 shows an alternative history in which a promotion in June 2014 reversed the usual seasonal low associated with June sales. This demand pattern was forecasted using the Automatic forecasting tournament in SmartForecasts, as in Figure 1. This time, the promotion scrambled the seasonal pattern enough to create an inappropriate non-seasonal forecast, and one that has a much larger margin of error.

Finally, Figure 3 shows how Promo forecasting handles the same promoted scenario, retaining a seasonal forecast and building into the forecast an estimate of the effect of a planned repeat promotion in 2015.
The Case of Intermittent Demand
In Figure 1, the item was a high-volume finished good and the task was demand forecasting. Promo modeling is also useful when dealing with the task of setting safety stocks and reorder points for items with intermittent demand, whether the items are finished goods, components or spare parts. Intermittent demand very often has a skewed distribution that makes it difficult to achieve high item availability with a small investment in inventory.
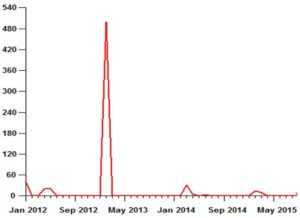
Figure 4 illustrates the problem that a successful promotion can accidentally create for inventory management. If such a spike arises from the natural, un-promoted demand, then the only way to maintain high fill rates is to provide safety stocks large enough to cope with these random surges. In this case, the big spike in demand of 500 units in February 2013 was the result of a one-time promotion.
Taking Account of Promotions to Improve Inventory Management
Unwittingly treating the spike in the example above as part of the natural demand variability results in a poor fill rate. To achieve a target service level of, say, 95% with a lead time of one month would require a reorder point of 38 units, computed as the sum of an expected forecast over the one month replenishment lead time of 21 units supplemented by a safety stock of 17 units. This investment would result in a disappointing fill rate of only 36%.
However, recognizing that the spike is a one-time promotion and replacing the 500 units with 0 obviously would make a big difference. The reorder point would drop from 38 units to 31 (the sum of an expected demand of 7 units and a safety stock of 24 units) and the fill rate would increase to 94%.
Of course, it is not ok to just throw out inconvenient demand spikes whenever they make life uncomfortable; there has to be a valid “business story” behind the adjustment of historical demand. If the spike is the result of a data processing error, then by all means, fix it. If the spike coincides with a promotion, then replacing the spike with, say, the median demand (often zero, as in this example) will result in a much more sustainable inventory investment that still meets aggressive performance targets. Future promotions of the same type on the same item will require some extra effort to prepare for the temporary surge in demand, but the recommended reorder point will be correct in the long run.
Thomas Willemain, PhD, co-founded Smart Software and currently serves as Senior Vice President for Research. Dr. Willemain also serves as Professor Emeritus of Industrial and Systems Engineering at Rensselear Polytechnic Institute and as a member of the research staff at the Center for Computing Sciences, Institute for Defense Analyses.

Related Posts

Forecast-Based Inventory Management for Better Planning
Forecast-based inventory management, or MRP (Material Requirements Planning) logic, is a forward-planning method that helps businesses meet demand without overstocking or understocking. By anticipating demand and adjusting inventory levels, it maintains a balance between meeting customer needs and minimizing excess inventory costs. This approach optimizes operations, reduces waste, and enhances customer satisfaction.

Future-Proofing Utilities: Advanced Analytics for Supply Chain Optimization
Utilities in the electrical, natural gas, urban water, and telecommunications fields are all asset-intensive and reliant on physical infrastructure that must be properly maintained, updated, and upgraded over time. Maximizing asset uptime and the reliability of physical infrastructure demands effective inventory management, spare parts forecasting, and supplier management. A utility that executes these processes effectively will outperform its peers, provide better returns for its investors and higher service levels for its customers, while reducing its environmental impact.

Leveraging Epicor Kinetic Planning BOMs with Smart IP&O to Forecast Accurately
In this blog, we explore how leveraging Epicor Kinetic Planning BOMs with Smart IP&O can transform your approach to forecasting in a highly configurable manufacturing environment. Discover how Smart, a cutting-edge AI-driven demand planning and inventory optimization solution, can simplify the complexities of predicting finished goods demand, especially when dealing with interchangeable components. Learn how Planning BOMs and advanced forecasting techniques enable businesses to anticipate customer needs more accurately, ensuring operational efficiency and staying ahead in a competitive market.
Recent Posts
 Forecast-Based Inventory Management for Better PlanningForecast-based inventory management, or MRP (Material Requirements Planning) logic, is a forward-planning method that helps businesses meet demand without overstocking or understocking. By anticipating demand and adjusting inventory levels, it maintains a balance between meeting customer needs and minimizing excess inventory costs. This approach optimizes operations, reduces waste, and enhances customer satisfaction. […]
Forecast-Based Inventory Management for Better PlanningForecast-based inventory management, or MRP (Material Requirements Planning) logic, is a forward-planning method that helps businesses meet demand without overstocking or understocking. By anticipating demand and adjusting inventory levels, it maintains a balance between meeting customer needs and minimizing excess inventory costs. This approach optimizes operations, reduces waste, and enhances customer satisfaction. […] Make AI-Driven Inventory Optimization an Ally for Your OrganizationIn this blog, we will explore how organizations can achieve exceptional efficiency and accuracy with AI-driven inventory optimization. Traditional inventory management methods often fall short due to their reactive nature and reliance on manual processes. Maintaining optimal inventory levels is fundamental for meeting customer demand while minimizing costs. The introduction of AI-driven inventory optimization can significantly reduce the burden of manual processes, providing relief to supply chain managers from tedious tasks. […]
Make AI-Driven Inventory Optimization an Ally for Your OrganizationIn this blog, we will explore how organizations can achieve exceptional efficiency and accuracy with AI-driven inventory optimization. Traditional inventory management methods often fall short due to their reactive nature and reliance on manual processes. Maintaining optimal inventory levels is fundamental for meeting customer demand while minimizing costs. The introduction of AI-driven inventory optimization can significantly reduce the burden of manual processes, providing relief to supply chain managers from tedious tasks. […] The Importance of Clear Service Level Definitions in Inventory ManagementInventory optimization software that supports what-if analysis will expose the tradeoff of stockouts vs. excess costs of varying service level targets. But first it is important to identify how “service levels” is interpreted, measured, and reported. This will avoid miscommunication and the false sense of security that can develop when less stringent definitions are used. Clearly defining how service level is calculated puts all stakeholders on the same page. This facilitates better decision-making. […]
The Importance of Clear Service Level Definitions in Inventory ManagementInventory optimization software that supports what-if analysis will expose the tradeoff of stockouts vs. excess costs of varying service level targets. But first it is important to identify how “service levels” is interpreted, measured, and reported. This will avoid miscommunication and the false sense of security that can develop when less stringent definitions are used. Clearly defining how service level is calculated puts all stakeholders on the same page. This facilitates better decision-making. […] Future-Proofing Utilities: Advanced Analytics for Supply Chain OptimizationUtilities in the electrical, natural gas, urban water, and telecommunications fields are all asset-intensive and reliant on physical infrastructure that must be properly maintained, updated, and upgraded over time. Maximizing asset uptime and the reliability of physical infrastructure demands effective inventory management, spare parts forecasting, and supplier management. A utility that executes these processes effectively will outperform its peers, provide better returns for its investors and higher service levels for its customers, while reducing its environmental impact. […]
Future-Proofing Utilities: Advanced Analytics for Supply Chain OptimizationUtilities in the electrical, natural gas, urban water, and telecommunications fields are all asset-intensive and reliant on physical infrastructure that must be properly maintained, updated, and upgraded over time. Maximizing asset uptime and the reliability of physical infrastructure demands effective inventory management, spare parts forecasting, and supplier management. A utility that executes these processes effectively will outperform its peers, provide better returns for its investors and higher service levels for its customers, while reducing its environmental impact. […] The Cost of Spreadsheet PlanningCompanies that depend on spreadsheets for demand planning, forecasting, and inventory management are often constrained by the spreadsheet’s inherent limitations. This post examines the drawbacks of traditional inventory management approaches caused by spreadsheets and their associated costs, contrasting these with the significant benefits gained from embracing state-of-the-art planning technologies. […]
The Cost of Spreadsheet PlanningCompanies that depend on spreadsheets for demand planning, forecasting, and inventory management are often constrained by the spreadsheet’s inherent limitations. This post examines the drawbacks of traditional inventory management approaches caused by spreadsheets and their associated costs, contrasting these with the significant benefits gained from embracing state-of-the-art planning technologies. […]

Inventory Optimization for Manufacturers, Distributors, and MRO
- Future-Proofing Utilities: Advanced Analytics for Supply Chain OptimizationUtilities in the electrical, natural gas, urban water, and telecommunications fields are all asset-intensive and reliant on physical infrastructure that must be properly maintained, updated, and upgraded over time. Maximizing asset uptime and the reliability of physical infrastructure demands effective inventory management, spare parts forecasting, and supplier management. A utility that executes these processes effectively will outperform its peers, provide better returns for its investors and higher service levels for its customers, while reducing its environmental impact. […]
 Centering Act: Spare Parts Timing, Pricing, and ReliabilityIn this article, we'll walk you through the process of crafting a spare parts inventory plan that prioritizes availability metrics such as service levels and fill rates while ensuring cost efficiency. We'll focus on an approach to inventory planning called Service Level-Driven Inventory Optimization. Next, we'll discuss how to determine what parts you should include in your inventory and those that might not be necessary. Lastly, we'll explore ways to enhance your service-level-driven inventory plan consistently. […]
Centering Act: Spare Parts Timing, Pricing, and ReliabilityIn this article, we'll walk you through the process of crafting a spare parts inventory plan that prioritizes availability metrics such as service levels and fill rates while ensuring cost efficiency. We'll focus on an approach to inventory planning called Service Level-Driven Inventory Optimization. Next, we'll discuss how to determine what parts you should include in your inventory and those that might not be necessary. Lastly, we'll explore ways to enhance your service-level-driven inventory plan consistently. […] Why MRO Businesses Need Add-on Service Parts Planning & Inventory SoftwareMRO organizations exist in a wide range of industries, including public transit, electrical utilities, wastewater, hydro power, aviation, and mining. To get their work done, MRO professionals use Enterprise Asset Management (EAM) and Enterprise Resource Planning (ERP) systems. These systems are designed to do a lot of jobs. Given their features, cost, and extensive implementation requirements, there is an assumption that EAM and ERP systems can do it all. In this post, we summarize the need for add-on software that addresses specialized analytics for inventory optimization, forecasting, and service parts planning. […]
Why MRO Businesses Need Add-on Service Parts Planning & Inventory SoftwareMRO organizations exist in a wide range of industries, including public transit, electrical utilities, wastewater, hydro power, aviation, and mining. To get their work done, MRO professionals use Enterprise Asset Management (EAM) and Enterprise Resource Planning (ERP) systems. These systems are designed to do a lot of jobs. Given their features, cost, and extensive implementation requirements, there is an assumption that EAM and ERP systems can do it all. In this post, we summarize the need for add-on software that addresses specialized analytics for inventory optimization, forecasting, and service parts planning. […] 5 Steps to Improve the Financial Impact of Spare Parts PlanningIn today’s competitive business landscape, companies are constantly seeking ways to improve their operational efficiency and drive increased revenue. Optimizing service parts management is an often-overlooked aspect that can have a significant financial impact. Companies can improve overall efficiency and generate significant financial returns by effectively managing spare parts inventory. This article will explore the economic implications of optimized service parts management and how investing in Inventory Optimization and Demand Planning Software can provide a competitive advantage. […]
5 Steps to Improve the Financial Impact of Spare Parts PlanningIn today’s competitive business landscape, companies are constantly seeking ways to improve their operational efficiency and drive increased revenue. Optimizing service parts management is an often-overlooked aspect that can have a significant financial impact. Companies can improve overall efficiency and generate significant financial returns by effectively managing spare parts inventory. This article will explore the economic implications of optimized service parts management and how investing in Inventory Optimization and Demand Planning Software can provide a competitive advantage. […]
