In this blog, we will explore how organizations can achieve exceptional efficiency and accuracy with AI-driven inventory optimization. Traditional inventory management methods often fall short due to their reactive nature and reliance on manual processes. Maintaining optimal inventory levels is fundamental for meeting customer demand while minimizing costs. The introduction of AI-driven inventory optimization can significantly reduce the burden of manual processes, providing relief to supply chain managers from tedious tasks. With AI, we can predict demand more accurately, reduce excess stock, avoid stockouts, and ultimately improve our organization’s bottom line. Let’s explore how this approach not only boosts sales and operational efficiency but also elevates customer satisfaction by ensuring products are always available when needed.
Insights for Improved Decision-Making in Inventory Management
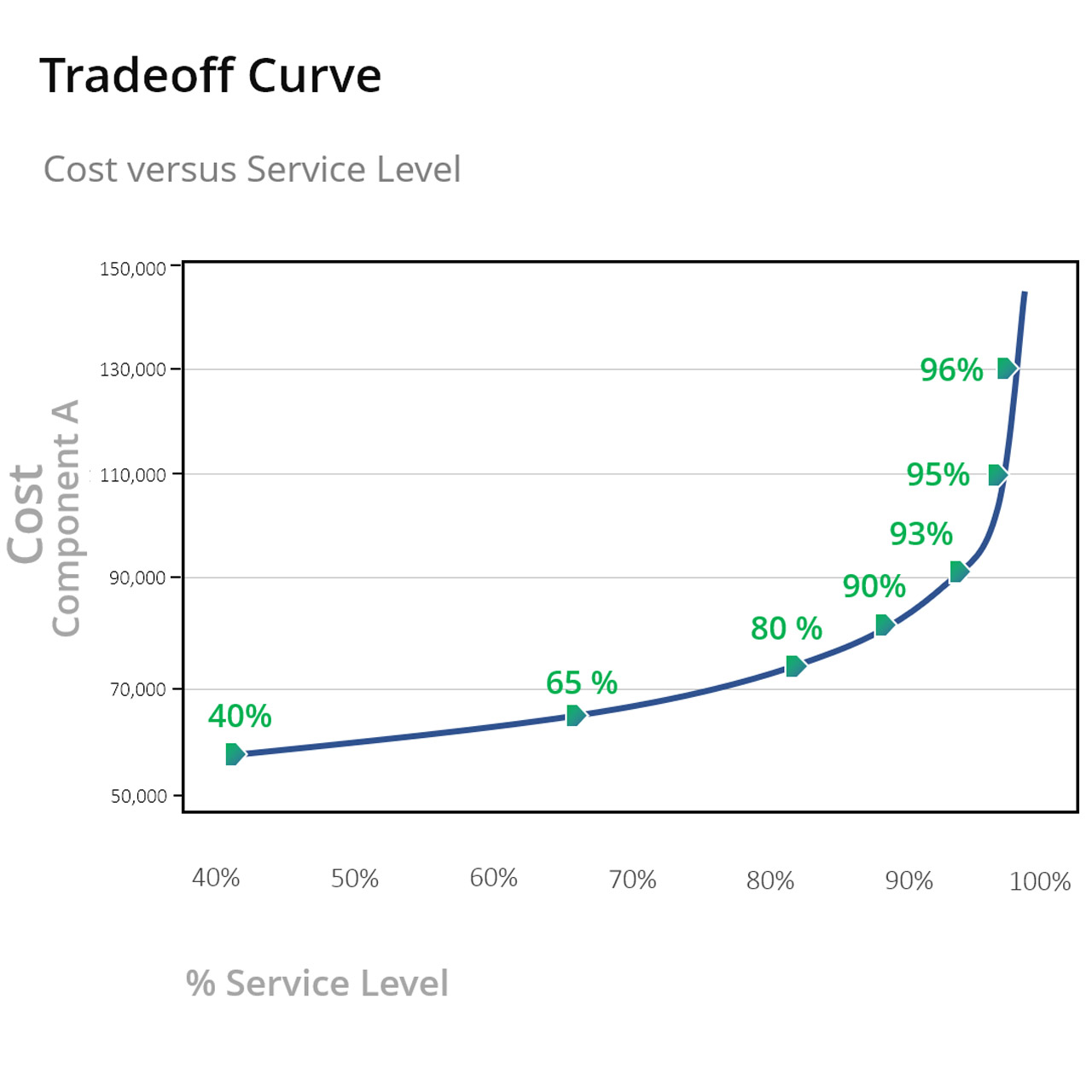
- Enhanced Forecast Accuracy Advanced Machine Learning algorithms analyze historical data to identify patterns that humans might miss. Techniques like clustering, regime change detection, anomaly detection, and regression analysis provide deep insights into data. Measuring forecast error is essential for refining forecast models; for example, techniques like Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE) help quantify the accuracy of forecasts. Businesses can improve accuracy by continuously monitoring and adjusting forecasts based on these error metrics. As the Demand Planner at a Hardware Retailer stated, “With the improvements to our forecasts and inventory planning that Smart Software enabled, we have been able to reduce safety stock by 20% while also reducing stock-outs by 35%.”
- Real-Time Data Analysis State-of-the-art systems can process vast amounts of data in real time, allowing businesses to adjust their inventory levels dynamically based on current demand trends and market conditions. Anomaly detection algorithms can automatically identify and correct sudden spikes or drops in demand, ensuring that the forecasts remain accurate. A notable success story comes from Smart IP&O, which enabled one company to reduce inventory by 20% while maintaining service levels by continuously analyzing real-time data and adjusting forecasts accordingly. FedEx Tech’s Manager of Materials highlighted, “Whatever the request, we need to meet our next-day service commitment – Smart enables us to risk adjust our inventory to be sure we have the products and parts on hand to achieve the service levels our customers require.”
- Improved Supply Chain Efficiency Intelligent technology platforms can optimize the entire supply chain, from procurement to distribution, by predicting lead times and optimizing order quantities. This reduces the risk of overstocking and understocking. For instance, using forecast-based inventory management, Smart Software helped a manufacturer streamline its supply chain, reducing lead times by 15% and enhancing overall efficiency. The VP of Operations at Procon Pump stated, “One of the things I like about this new tool… is that I can evaluate the consequences of inventory stocking decisions before I implement them.”
- Enhanced Decision-Making AI provides actionable insights and recommendations, enabling managers to make informed decisions. This includes identifying slow-moving items, forecasting future demand, and optimizing stock levels. Regression analysis, for example, can relate sales to external variables like seasonality or economic indicators, providing a deeper understanding of demand drivers. One of Smart Software’s clients reported a significant improvement in decision-making processes, resulting in a 30% increase in service levels while reducing excess inventory by 15%. “Smart IP&O enabled us to model demand at each stocking location and, using service level-driven planning, determine how much to stock to achieve the service level we require,” noted the Purchasing Manager at Seneca Companies.
- Cost Reduction By optimizing inventory levels, businesses can reduce holding costs and minimize losses from obsolete or expired products. AI-driven systems also reduce the need for manual inventory checks, saving time and labor costs. A recent case study shows how implementing Inventory Planning & Optimization (IP&O) was accomplished within 90 days of project start. Over the ensuing six months, IP&O enabled the adjustment of stocking parameters for several thousand items, resulting in inventory reductions of $9.0 million while sustaining target service levels.
By leveraging advanced algorithms and real-time data analysis, businesses can maintain optimal inventory levels and enhance their overall supply chain performance. Inventory Planning & Optimization (IP&O) is a powerful tool that can help your organization achieve these goals. Incorporating state-of-the-art inventory optimization into your organization can lead to significant improvements in efficiency, cost reduction, and customer satisfaction.