True or false: The forecast doesn’t matter to spare parts inventory management.
At first glance, this statement seems obviously false. After all, forecasts are crucial for planning stock levels, right?
It depends on what you mean by a “forecast”. If you mean an old-school single-number forecast (“demand for item CX218b will be 3 units next week and 6 units the week after”), then no. If you broaden the meaning of forecast to include a probability distribution taking account of uncertainties in both demand and supply, then yes.
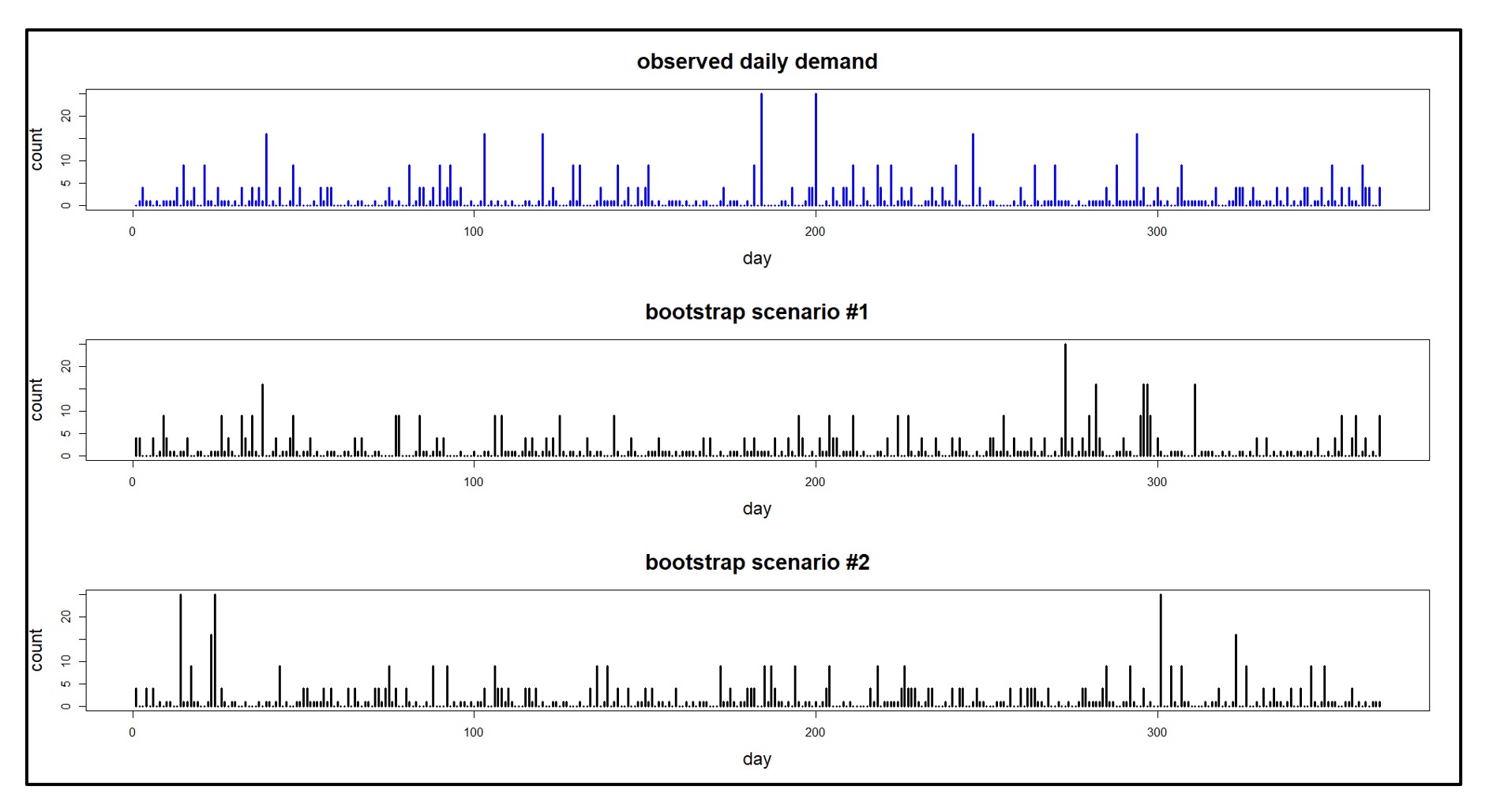
The key reality is that many items, especially spare and service parts, have unpredictable, intermittent demand. (Supplier lead times can also be erratic, especially when parts are sourced from a backlogged OEM.) We have observed that while manufacturers and distributors typically experience intermittent demand on just 20% or more of their items the percentage grows to 80%+ for MRO based businesses. This means historical data often show periods of zero demand interspersed with random periods of non-zero demand. Sometimes, these non-zero demands are as low as 1 or 2 units, while at other times, they unexpectedly spike to quantities several times larger than their average.
This isn’t like the kind of data usually faced by your peer “demand planners” in retail, consumer products, and food and beverage. Those folks usually deal with larger quantities having proportionately less randomness. And they can surf on prediction-enhancing features like trends and stable seasonal patterns. Instead, spare parts usage is much more random, throwing a monkey wrench into the planning process, even in the minority of cases in which there are detectable seasonal variations.
In the realm of intermittent demand, the best forecast available will significantly deviate from the actual demand. Unlike consumer products with medium to high volume and frequency, a service part’s forecast can miss the mark by hundreds of percentage points. A forecast of one or two units, on average, will always miss when the actual demand is zero. Even with advanced business intelligence or machine learning algorithms, the error in forecasting the non-zero demands will still be substantial.
Perhaps because of the difficulty of statistical forecasting in the inventory domain, inventory planning in practice often relies on intuition and planner knowledge. Unfortunately, this approach doesn’t scale across tens of thousands of parts. Intuition just cannot cope with the full range of demand and lead time possibilities, let alone accurately estimate the probability of each possible scenario. Even if your company has one or two exceptional intuitive forecasters, personnel retirements and product line reorganizations mean that intuitive forecasting can’t be relied on going forward.
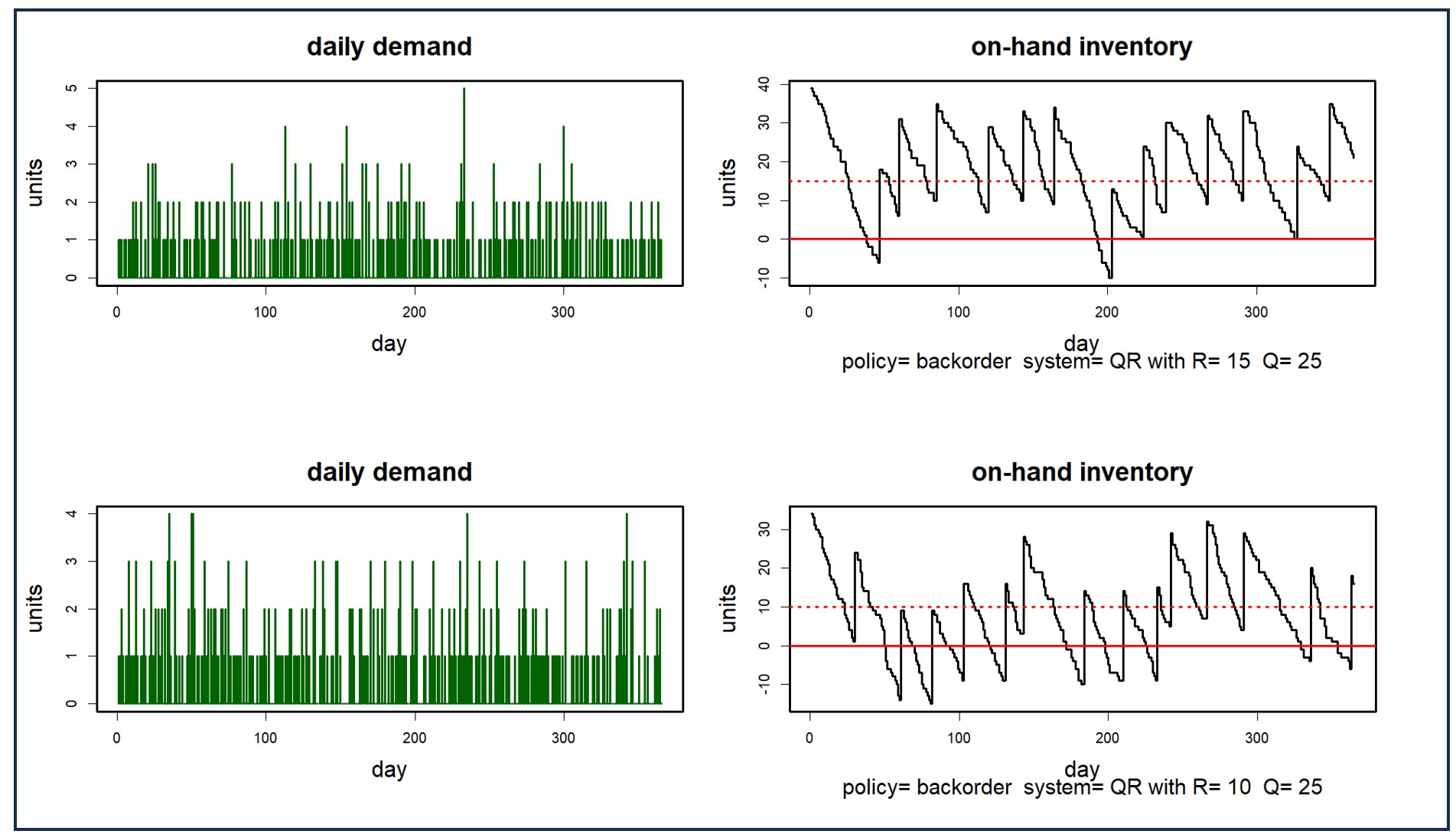
The solution lies in shifting focus from traditional forecasts to predicting probabilities for each potential demand and lead time scenario. This shift transforms the conversation from an unrealistic “one number plan” to a range of numbers with associated probabilities. By predicting probabilities for each demand and lead time possibility, you can better align stock levels with the risk tolerance for each group of parts.
Software that generates demand and lead time scenarios, repeating this process tens of thousands of times, can accurately simulate how current stocking policies will perform against these policies. If the performance in the simulation falls short and you are predicted to stock out more often than you are comfortable with or you are left with excess inventory, conducting what-if scenarios allows adjustments to policies. You can then predict how these revised policies will fare against random demands and lead times. You can conduct this process iteratively and refine it with each new what-if scenario or lean on system prescribed policies that optimally strike a balance between risk and costs.
So, if you are planning service and spare parts inventories, stop worrying about predicting demand the way traditional retail and CPG demand planners do it. Focus instead on how your stocking policies will withstand the randomness of the future, adjusting them based on your risk tolerance. To do this, you’ll need the right set of decision support software, and this is how Smart Software can help.
Spare Parts Planning Software solutions
Smart IP&O’s service parts forecasting software uses a unique empirical probabilistic forecasting approach that is engineered for intermittent demand. For consumable spare parts, our patented and APICS award winning method rapidly generates tens of thousands of demand scenarios without relying on the assumptions about the nature of demand distributions implicit in traditional forecasting methods. The result is highly accurate estimates of safety stock, reorder points, and service levels, which leads to higher service levels and lower inventory costs. For repairable spare parts, Smart’s Repair and Return Module accurately simulates the processes of part breakdown and repair. It predicts downtime, service levels, and inventory costs associated with the current rotating spare parts pool. Planners will know how many spares to stock to achieve short- and long-term service level requirements and, in operational settings, whether to wait for repairs to be completed and returned to service or to purchase additional service spares from suppliers, avoiding unnecessary buying and equipment downtime.
Contact us to learn more how this functionality has helped our customers in the MRO, Field Service, Utility, Mining, and Public Transportation sectors to optimize their inventory. You can also download the Whitepaper here.
White Paper: What you Need to know about Forecasting and Planning Service Parts
This paper describes Smart Software’s patented methodology for forecasting demand, safety stocks, and reorder points on items such as service parts and components with intermittent demand, and provides several examples of customer success.