Forecast-based inventory management, or MRP (Material Requirements Planning) logic, is a forward-planning methodology for managing inventory. This method ensures that businesses can meet demand without overstocking, which ties up capital, or understocking, which can lead to lost sales and dissatisfied customers.
By anticipating demand and adjusting inventory levels accordingly, this approach helps maintain the right balance between having enough stock to meet customer needs and minimizing excess inventory costs. Businesses can optimize operations, reduce waste, and improve customer satisfaction by predicting future needs. Let’s break down how this works.
Core Concepts of Forecast-Based Inventory Management
Inventory Dynamics Models: Inventory dynamics models are fundamental to understanding and managing inventory levels. The simplest model, known as the “sawtooth” model, demonstrates inventory levels decreasing with demand and replenishing just in time. However, real-world scenarios often require more sophisticated models. By incorporating stochastic elements and variability, such as Monte Carlo simulations, businesses can account for random fluctuations in demand and lead time, providing a more realistic forecast of inventory levels.
IP&O platform enhances inventory dynamics modeling through advanced data analytics and simulation capabilities. By leveraging AI and machine learning algorithms, our IP&O platform can predict demand patterns more accurately, adjusting models in real time based on the latest data. This leads to more precise inventory levels, reducing the risk of stockouts and overstocking.
Determining Order Quantity and Timing: Effective inventory management requires knowing when and how much to order. This involves forecasting future demand and calculating the lead time for replenishing stock. By predicting when inventory will hit safety stock levels, businesses can plan their orders to ensure continuous supply.
Our latest tools excel at optimizing order quantities and timing by utilizing predictive analytics and AI. These systems can analyze vast amounts of data, including historical sales and market trends. By doing so, they provide more accurate demand forecasts and optimize reorder points, ensuring inventory is replenished just in time without excess.
Calculating Lead Time: Lead time is the period from placing an order to receiving the stock. It varies based on the availability of components. For example, if a product is assembled from multiple components, the lead time will be determined by the component with the longest lead time.
Smart AI-driven solutions enhance lead time calculation by integrating with supply chain management systems. These systems track supplier performance, and historical lead times, to provide more accurate lead time estimates. Additionally, smart technologies can alert businesses to potential delays, allowing for proactive adjustments to inventory plans.
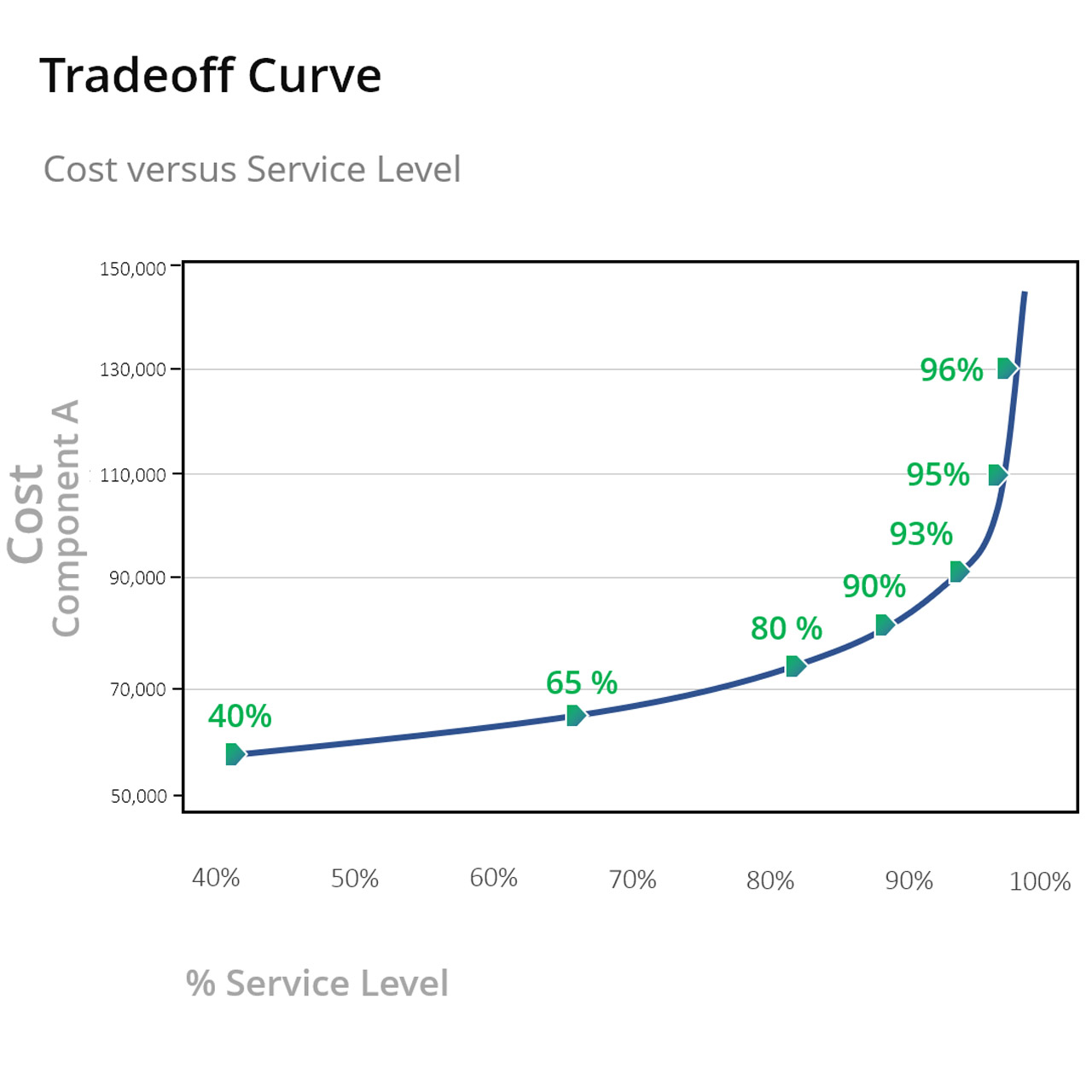
Safety Stock Calculation: Safety stock acts as a buffer to protect against variability in demand and supply. Calculating safety stock involves analyzing demand variability and setting a stock level that covers most potential scenarios, thus minimizing the risk of stockouts.
IP&O technology significantly improves safety stock calculation through advanced analytics. By continuously monitoring demand patterns and supply chain variables, smart systems can dynamically adjust safety stock levels. Machine learning algorithms can predict demand spikes or drops and adjust safety stock accordingly, ensuring optimal inventory levels while minimizing holding costs.
The Importance of Accurate Forecasting in Inventory Management
Accurate forecasting is key for minimizing forecast errors, which can lead to excess inventory or stockouts. Techniques such as utilizing historical data, enhancing data inputs, and applying advanced forecasting methods help achieve better accuracy. Forecast errors can have significant financial implications: over-forecasting results in excess inventory while under-forecasting leads to missed sales opportunities. Managing these errors through systematic tracking and adjusting forecasting methods is crucial for maintaining optimal inventory levels.
Safety stock ensures that businesses meet customer needs even if actual demand deviates from the forecast. This cushion protects against unforeseen demand spikes or delays in replenishment. Accurate forecasting, effective error management, and strategic use of safety stock enhance forecast-based inventory management. Companies can understand inventory dynamics, determine the right order quantities and timing, calculate accurate lead times, and set appropriate safety stock levels.
Using state-of-the-art technology like IP&O provides significant advantages by offering real-time data insights, predictive analytics, and adaptive models. This leads to more efficient inventory management, reduced costs, and improved customer satisfaction. Overall, IP&O empowers businesses to plan better and respond swiftly to market changes, ensuring they maintain the right inventory balance to meet customer needs without incurring unnecessary costs.