In this article, we will review the “suggested orders” functionality in Epicor BisTrack, explain its limitations, and summarize how Smart Inventory Planning & Optimization (Smart IP&O) can help reduce inventory & minimize stock-outs by accurately assessing the tradeoffs between stockout risks and inventory costs.
Automating Replenishment in Epicor BisTrack
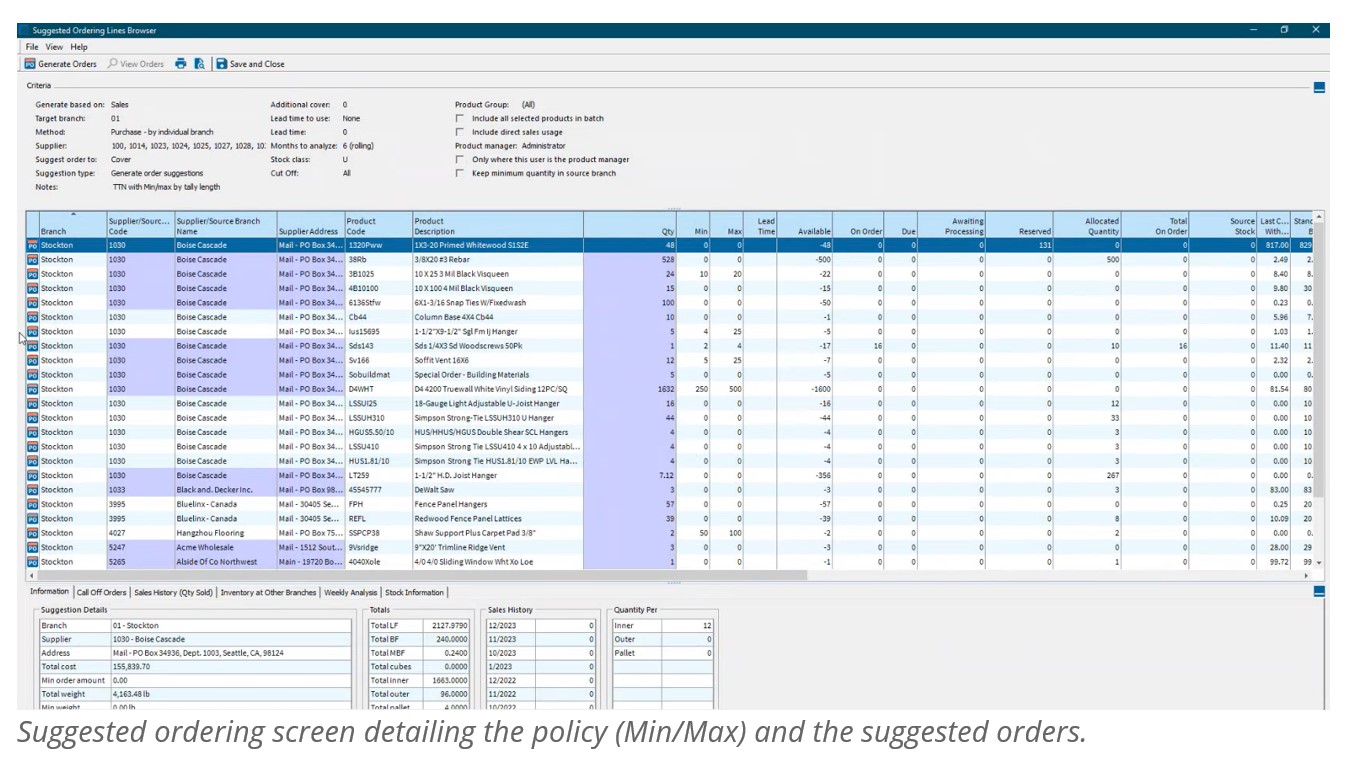
Epicor BisTrack’s “Suggested Ordering” can manage replenishment by suggesting what to order and when via reorder point-based policies such as min-max and/or manually specified weeks of supply. BisTrack contains some basic functionality to compute these parameters based on average usage or sales, supplier lead time, and/or user-defined seasonal adjustments. Alternatively, reorder points can be specified completely manually. BisTrack will then present the user with a list of suggested orders by reconciling incoming supply, current on hand, outgoing demand, and stocking policies.
How Epicor BisTrack “Suggested Ordering” Works
To get a list of suggested orders, users specify the methods behind the suggestions, including locations for which to place orders and how to determine the inventory policies that govern when a suggestion is made and in what quantity.
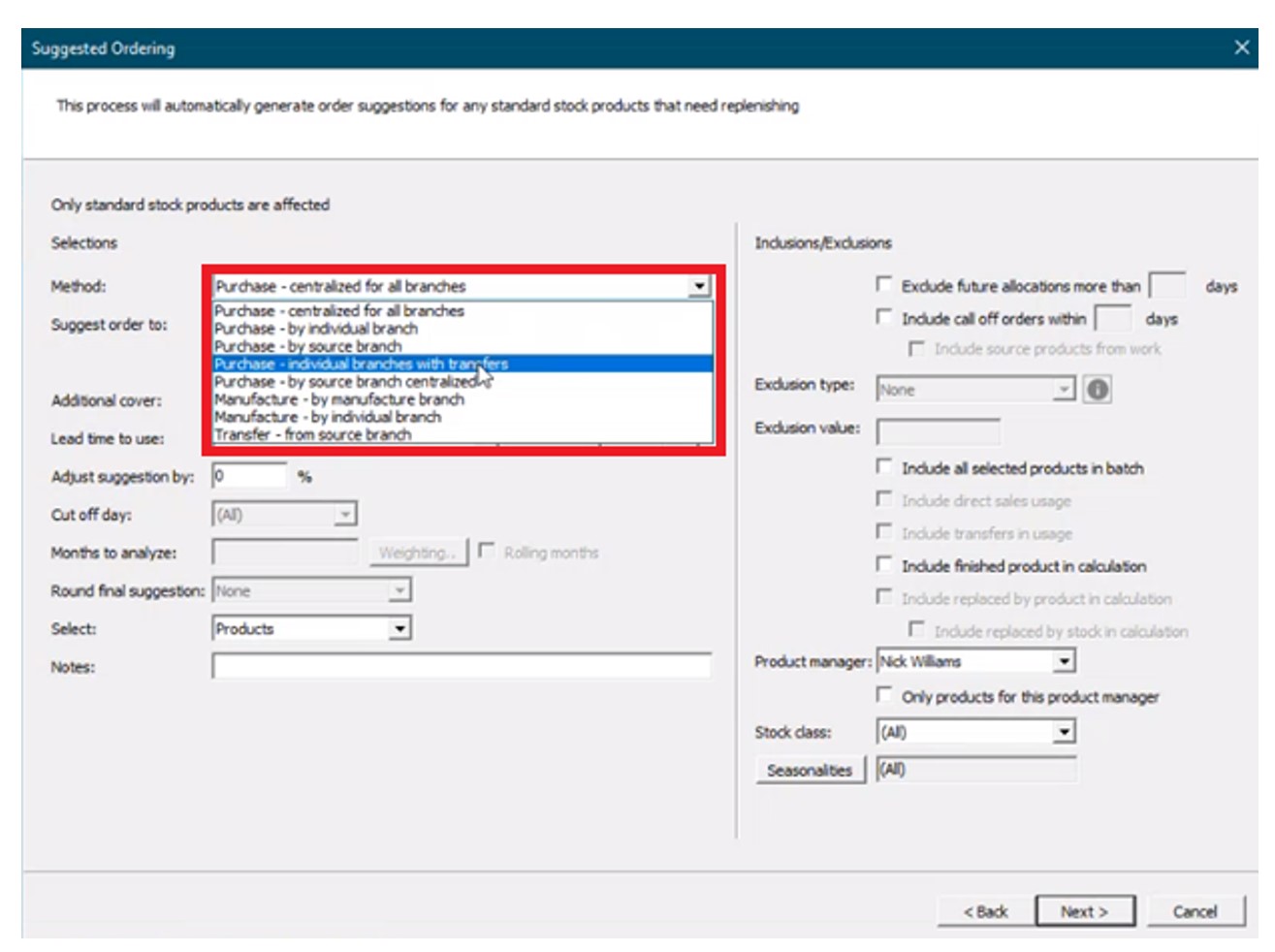
First, the “method” field is specified from the following options to determine what kind of suggestion is generated and for which location(s):
Purchase – Generate purchase order recommendations.
- Centralized for all branches – Generates suggestions for a single location that buys for all other locations.
- By individual branch – Generates suggestions for multiple locations (vendors would ship directly to each branch).
- By source branch – Generates suggestions for a source branch that will transfer material to branches that it services (“hub and spoke”).
- Individual branches with transfers – Generates suggestions for an individual branch that will transfer material to branches that it services (“hub and spoke”, where the “hub” does not need to be a source branch).
Manufacture – Generate work order suggestions for manufactured goods.
- By manufacture branch.
- By individual branch.
Transfer from source branch – Generate transfer suggestions from a given branch to other branches.
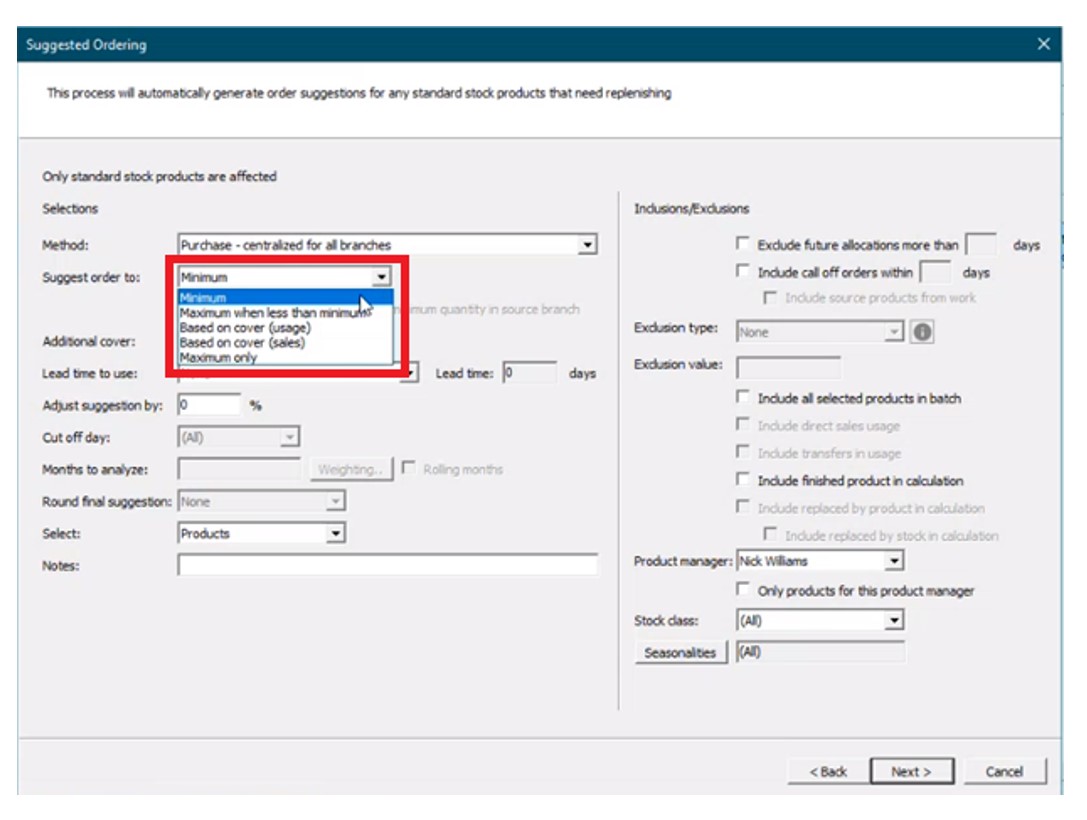
Next, the “suggest order to” is specified from the following options:
- Minimum – Suggests orders “up to” the minimum on hand quantity (“min”). For any item where supply is less than the min, BisTrack will suggest an order suggestion to replenish up to this quantity.
- Maximum when less than min – Suggests orders “up to” a maximum on-hand quantity when the minimum on-hand quantity is breached (e.g. a min-max inventory policy).
- Based on cover (usage) – Suggests orders based on coverage for a user-defined number of weeks of supply with respect to a specified lead time. Given internal usage as demand, BisTrack will recommend orders where supply is less than the desired coverage to cover the difference.
- Based on over (sales) – Suggests orders based on coverage for a user-defined number of weeks of supply with respect to a specified lead time. Given sales orders as demand, BisTrack will recommend orders where supply is less than the desired coverage to cover the difference.
- Maximum only – Suggests orders “up to” a maximum on-hand quantity where supply is less than this max.
Finally, if allowing BisTrack to determine the reorder thresholds, users can specify additional inventory coverage as buffer stock, lead times, how many months of historical demand to consider, and can also manually define period-by-period weighting schemes to approximate seasonality. The user will be handed a list of suggested orders based on the defined criteria. A buyer can then generate POs for suppliers with the click of a button.
Limitations
Rule-of-thumb Methods
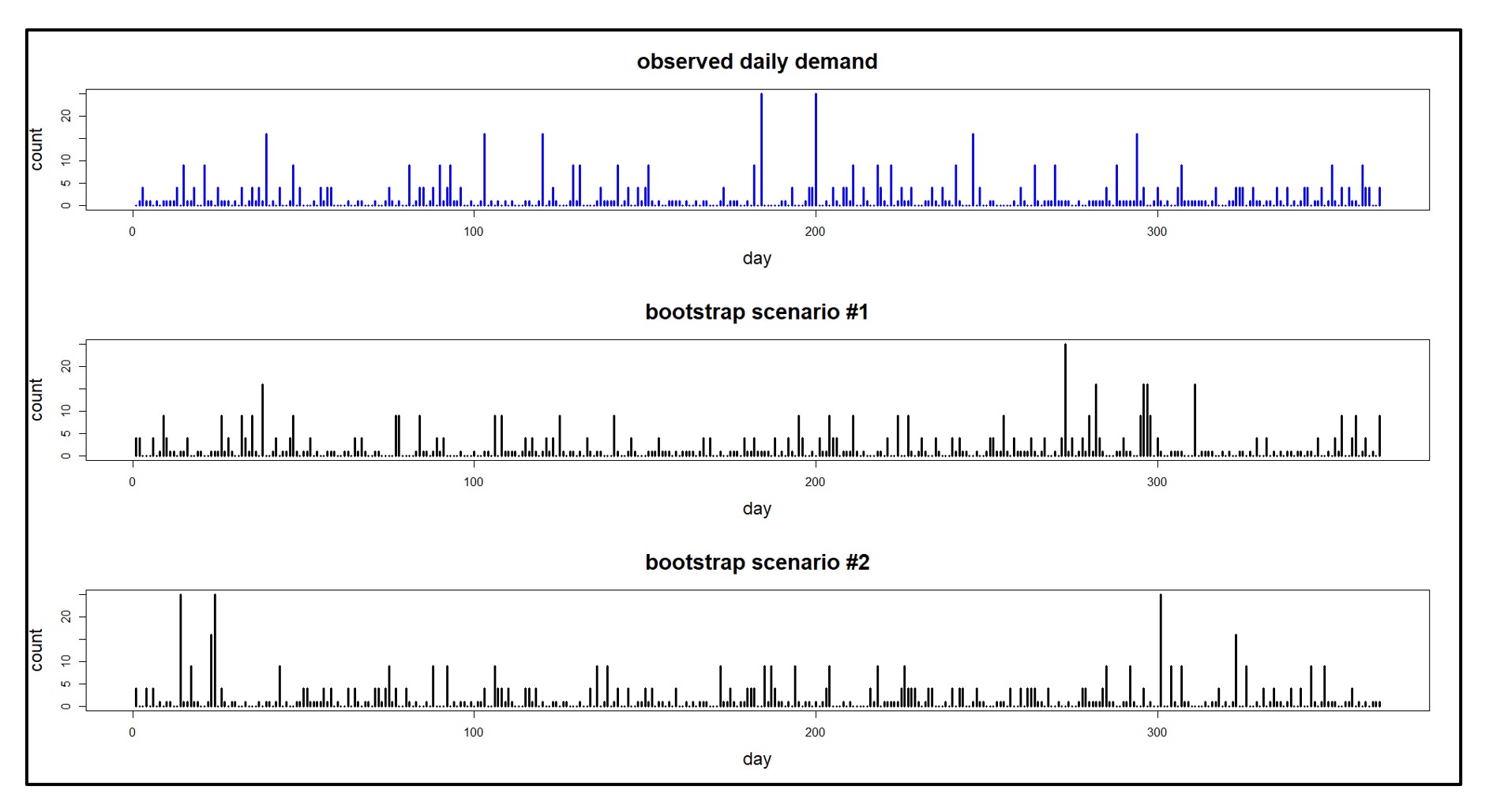
While BisTrack enables organizations to generate reorder points automatically, these methods rely on simple averages that do not capture seasonality, trends, or the volatility in an item’s demand. Averages will always lag behind these patterns and are unable to pick up on trends. Consider a highly seasonal product like a snow shovel—if we take an average of Summer/Fall demand as we approach the Winter season instead of looking ahead, then the recommendations will be based on the slower periods instead of anticipating upcoming demand. Even if we consider an entire years’ worth of history or more, the recommendations will overcompensate during the slower months and underestimate the busy season without manual intervention.
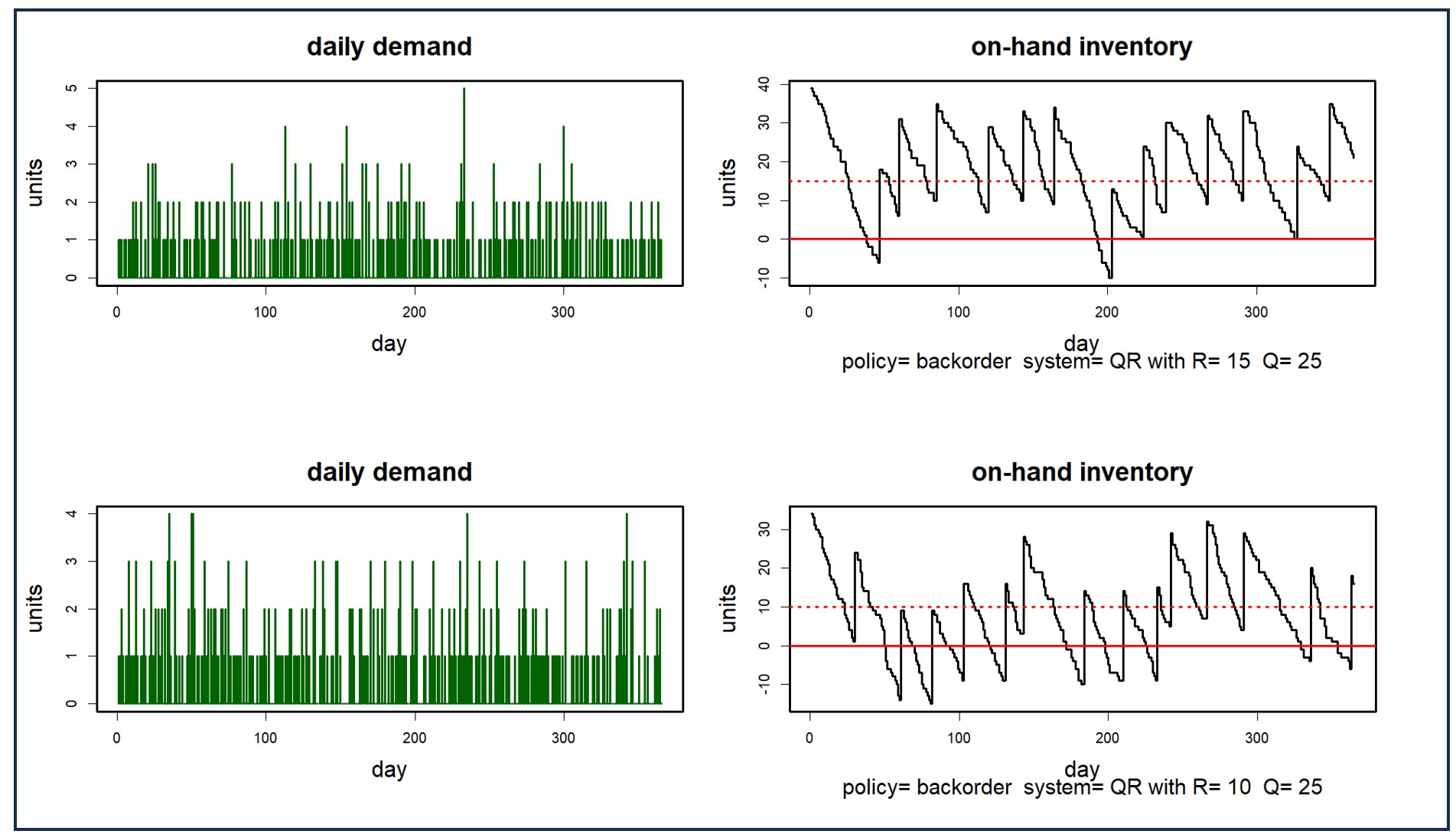
Rule of thumb methods also fail when used to buffer against supply and demand variability. For example, the average demand over the lead time might be 20 units. However, a planner would often want to stock more than 20 units to avoid stocking out if lead times are longer than expected or demand is higher than the average. BisTrack allows users to specify the reorder points based on multiples of the averages. However, because the multiples don’t account for the level of predictability and variability in the demand, you’ll always overstock predictable items and understock unpredictable ones. Read this article to learn more about why multiples of the average fail when it comes to developing the right reorder point.
Manual Entry
Speaking of seasonality referenced earlier, BisTrack does allow the user to approximate it through the use of manually entered “weights” for each period. This forces the user to have to decide what that seasonal pattern looks like—for every item. Even beyond that, the user must dictate how many extra weeks of supply to carry to buffer against stockouts, and must specify what lead time to plan around. Is 2 weeks extra supply enough? Is 3 enough? Or is that too much? There is no way to know without guessing, and what makes sense for one item might not be the right approach for all items.
Intermittent Demand
Many BisTrack customers may consider certain items “unforecastable” because of the intermittent or “lumpy” nature of their demand. In other words, items that are characterized by sporadic demand, large spikes in demand, and periods of little or no demand at all. Traditional methods—and rule-of-thumb approaches especially—won’t work for these kinds of items. For example, 2 extra weeks of supply for a highly predictable, stable item might be way too much; for an item with highly volatile demand, this same rule might not be enough. Without a reliable way to objectively assess this volatility for each item, buyers are left guessing when to buy and how much.
Reverting to Spreadsheets
The reality is most BisTrack users tend to do the bulk of their planning off-line, in Excel. Spreadsheets aren’t purpose-built for forecasting and inventory optimization. Users will often bake in user-defined rule of thumb methods that often do more harm than good. Once calculated, users must input the information back into BisTrack manually. The time consuming nature of the process leads companies to infrequently compute their inventory policies – Many months and on occasion years go by in between mass updates leading to a “set it and forget it” reactive approach, where the only time a buyer/planner reviews inventory policy is at the time of order. When policies are reviewed after the order point is already breached, it is too late. When the order point is deemed too high, manual interrogation is required to review history, calculate forecasts, assess buffer positions, and to recalibrate. The sheer volume of orders means that buyers will just release orders rather than take the painstaking time to review everything, leading to significant excess stock. If the reorder point is too low, it’s already too late. An expedite may now be required, driving up costs, assuming the customer doesn’t simply go elsewhere.
Epicor is Smarter
Epicor has partnered with Smart Software and offers Smart IP&O as a cross platform add-on to its ERP solutions including BisTrack, a speciality ERP for the Lumber, hardware, and building material industry. The Smart IP&O solution comes complete with a bidirectional integration to BisTrack. This enables Epicor customers to leverage built-for-purpose best of breed inventory optimization applications. With Epicor Smart IP&O you can generate forecasts that capture trend and seasonality without manual configurations. You will be able to automatically recalibrate inventory policies using field proven, cutting-edge statistical and probabilistic models that were engineered to accurately plan for intermittent demand. Safety stocks will accurately account for demand and supply variability, business conditions, and priorities. You can leverage service level driven planning so you have just enough stock or turn on optimization methods that prescribe the most profitable stocking policies and service levels that consider the real cost of carrying inventory. You can support commodity buys with accurate demand forecasting over longer horizons, and run “what-if” scenarios to assess alternative strategies before execution of the plan.
Smart IP&O customers routinely realize 7 figure annual returns from reduced expedites, increased sales, and less excess stock, all the while gaining a competitive edge by differentiating themselves on improved customer service. To see a recorded webinar hosted by the Epicor Users Group that profiles Smart’s Demand Planning and Inventory Optimization platform, please register here.