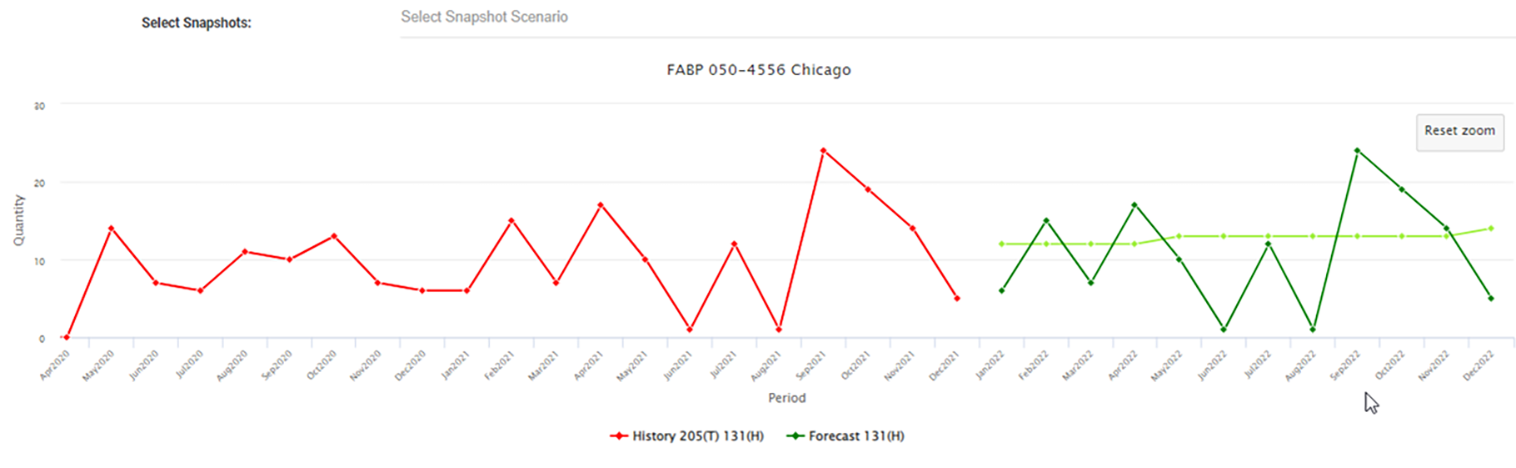
Sometimes a statistical forecast just doesn’t make sense. Every forecaster has been there. They may double-check that the data was input correctly or review the model settings but are still left scratching their head over why the forecast looks very unlike the demand history. When the occasional forecast doesn’t make sense, it can erode confidence in the entire statistical forecasting process.
This blog will help a layman understand what the Smart statistical models are and how they are chosen automatically. It will address how that choice sometimes fails, how you can know if it did, and what you can do to ensure that the forecasts can always be justified. It’s important to know to expect, and how to catch the exceptions so you can rely on your forecasting system.
How methods are chosen automatically
The criteria to automatically choose one statistical method out of a set is based on which method came closest to correctly predicting held-out history. Earlier history is passed to each method and the result is compared to actuals to find the one that came closest overall. That automatically chosen method is then fed all the history to produce the forecast. Check out this blog to learn more about the model selection https://smartcorp.com/uncategorized/statistical-forecasting-how-automatic-method-selection-works/
For most time series, this process can capture trends, seasonality, and average volume accurately. But sometimes a chosen method comes mathematically closest to predicting the held-out history but doesn’t project it forward in a way that makes sense. That means the system selected method isn’t best and for some “hard to forecast”
Hard to forecast items
Hard to forecast items may have large, unpredictable spikes in demand, or typically no demand but random irregular blips, or unusual recent activity. Noise in the data sometimes randomly wanders up or down, and the automated best-pick method might forecast a runaway trend or a grind into zero. It will do worse than common sense and in a small percentage of any reasonably varied group of items. So, you will need to identify these cases and respond by overriding the forecast or changing the forecast inputs.
How to find the exceptions
Best practice is to filter or sort the forecasted items to identify those where the sum of the forecast over the next year is significantly different than the corresponding history last year. The forecast sum may be much lower than the history or vice versa. Use supplied metrics to identify these items; then you can choose to apply overrides to the forecast or modify the forecast settings.
How to fix the exceptions
Often when the forecast seems odd, an averaging method, like Single Exponential Smoothing or even a simple average using Freestyle, will produce a more reasonable forecast. If trend is possibly valid, you can remove only seasonal methods to avoid a falsely seasonal result. Or do the opposite and use only seasonal methods if seasonality is expected but wasn’t projected in the default forecast. You can use the what-if features to create any number of forecasts, evaluate & compare, and continue to fine tune the settings until you are comfortable with the forecast.
Cleaning the history, with or without changing the automatic method selection, is also effective at producing reasonable forecasts. You can embed forecast parameters to reduce the amount of history used to forecast those items or the number of periods passed into the algorithm so earlier, outdated history is no longer considered. You can edit spikes or drops in the demand history that are known anomalies so they don’t influence the outcome. You can also work with the Smart team to implement automatic outlier detection and removal so that data prior to being forecasted is already cleansed of these anomalies.
If the demand is truly intermittent, it is going to be nearly impossible to forecast “accurately” per period. If a level-loading average is not acceptable, handling the item by setting inventory policy with a lead time forecast can be effective. Alternatively, you may choose to use “same as last year” models which while not prone to accuracy will be generally accepted by the business given the alternatives forecasts.
Finally, if the item was introduced so recently that the algorithms do not have enough input to accurately forecast, a simple average or manual forecast may be best. You can identify new items by filtering on the number of historical periods.
Manual selection of methods
Once you have identified rows where the forecast doesn’t make sense to the human eye, you can choose a smaller subset of all methods to allow into the forecast run and compare to history. Smart will allow you to use a restricted set of methods just for one forecast run or embed the restricted set to use for all forecast runs going forward. Different methods will project the history into the future in different ways. Having a sense of how each works will help you choose which to allow.
Rely on your forecasting tool
The more you use Smart period over period to embed your decisions about how to forecast and what historical data to consider, the less often you will face exceptions as described in this blog. Entering forecast parameters is a manageable task when starting with critical or high impact items. Even if you don’t embed any manual decisions on forecast methods, the forecast re-runs every period with new data. So, an item with an odd result today can become easily forecastable in time.