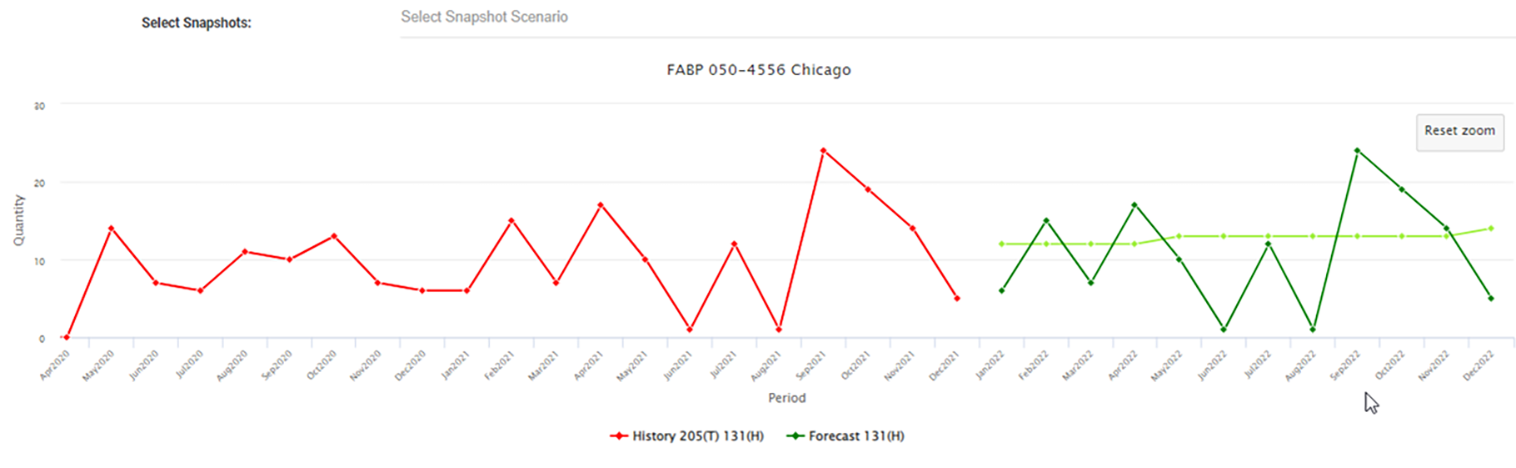
Soms slaat een statistische prognose gewoon nergens op. Elke voorspeller is er geweest. Ze kunnen dubbel controleren of de gegevens correct zijn ingevoerd of de modelinstellingen bekijken, maar ze blijven zich afvragen waarom de voorspelling er zo anders uitziet dan de vraaggeschiedenis. Wanneer de incidentele voorspelling nergens op slaat, kan dit het vertrouwen in het hele statistische prognoseproces aantasten.
Deze blog zal een leek helpen begrijpen wat de slimme statistische modellen zijn en hoe ze automatisch worden gekozen. Er wordt ingegaan op hoe die keuze soms mislukt, hoe u kunt weten of dat zo is en wat u kunt doen om ervoor te zorgen dat de prognoses altijd gerechtvaardigd kunnen worden. Het is belangrijk om te weten wat u kunt verwachten en hoe u de uitzonderingen kunt opvangen, zodat u kunt vertrouwen op uw prognosesysteem.
Hoe methoden automatisch worden gekozen
De criteria om automatisch één statistische methode uit een set te kiezen, zijn gebaseerd op welke methode het dichtst bij het correct voorspellen van de achtergehouden geschiedenis kwam. De eerdere geschiedenis wordt aan elke methode doorgegeven en het resultaat wordt vergeleken met de werkelijke waarden om de methode te vinden die er het dichtst bij in de buurt kwam. Die automatisch gekozen methode krijgt dan alle geschiedenis om de voorspelling te produceren. Bekijk deze blog voor meer informatie over de modelselectie https://smartcorp.com/uncategorized/statistical-forecasting-how-automatic-method-selection-works/
Voor de meeste tijdreeksen kan dit proces trends, seizoensgebondenheid en gemiddeld volume nauwkeurig vastleggen. Maar soms komt een gekozen methode wiskundig het dichtst in de buurt van het voorspellen van de achtergehouden geschiedenis, maar projecteert deze niet op een logische manier. Dat betekent dat de door het systeem geselecteerde methode niet de beste is en voor sommigen "moeilijk te voorspellen"
Moeilijk te voorspellen items
Moeilijk te voorspellen items kunnen grote, onvoorspelbare pieken in de vraag hebben, of meestal geen vraag maar willekeurige onregelmatige pieken, of ongebruikelijke recente activiteit. Ruis in de gegevens dwaalt soms willekeurig omhoog of omlaag, en de geautomatiseerde best-pick-methode kan een op hol geslagen trend of een nulpunt voorspellen. Het zal het slechter doen dan gezond verstand en in een klein percentage van een redelijk gevarieerde groep items. U moet deze gevallen dus identificeren en reageren door de prognose te negeren of de invoer van de prognose te wijzigen.
Hoe de uitzonderingen te vinden
De beste werkwijze is om de voorspelde items te filteren of te sorteren om de items te identificeren waarvan de som van de prognose voor het volgende jaar aanzienlijk afwijkt van de overeenkomstige geschiedenis van vorig jaar. De prognosesom kan veel lager zijn dan de historie of andersom. Gebruik de meegeleverde statistieken om deze items te identificeren; vervolgens kunt u ervoor kiezen om overschrijvingen toe te passen op de prognose of de prognose-instellingen te wijzigen.
Hoe de uitzonderingen op te lossen
Wanneer de voorspelling vreemd lijkt, zal een middelingsmethode, zoals Single Exponential Smoothing of zelfs een eenvoudig gemiddelde met behulp van Freestyle, vaak een redelijkere voorspelling opleveren. Als de trend mogelijk geldig is, kunt u alleen seizoensmethoden verwijderen om een onjuist seizoensresultaat te voorkomen. Of doe het tegenovergestelde en gebruik alleen seizoensmethoden als seizoensgebondenheid wordt verwacht maar niet was geprojecteerd in de standaardprognose. U kunt de wat-als-functies gebruiken om een onbeperkt aantal prognoses te maken, te evalueren en te vergelijken en de instellingen verder te verfijnen totdat u vertrouwd bent met de prognose.
Het opschonen van de geschiedenis, met of zonder wijziging van de automatische methodeselectie, is ook effectief bij het produceren van redelijke voorspellingen. U kunt prognoseparameters insluiten om de hoeveelheid geschiedenis die wordt gebruikt om die items te voorspellen of het aantal perioden dat aan het algoritme is doorgegeven, te verminderen, zodat eerdere, verouderde geschiedenis niet langer in aanmerking wordt genomen. U kunt pieken of dalen in de vraaggeschiedenis bewerken die bekende afwijkingen zijn, zodat ze de uitkomst niet beïnvloeden. U kunt ook samenwerken met het Smart-team om automatische detectie en verwijdering van uitschieters te implementeren, zodat gegevens voordat ze worden voorspeld al zijn opgeschoond van deze afwijkingen.
Als de vraag echt intermitterend is, wordt het bijna onmogelijk om "nauwkeurig" per periode te voorspellen. Als een level-loading-gemiddelde niet acceptabel is, kan het effectief zijn om het artikel af te handelen door een voorraadbeleid in te stellen met een doorlooptijdprognose. U kunt er ook voor kiezen om 'hetzelfde als vorig jaar'-modellen te gebruiken die, hoewel ze niet gevoelig zijn voor nauwkeurigheid, algemeen worden geaccepteerd door het bedrijf gezien de alternatieve prognoses.
Ten slotte, als het item zo recent is geïntroduceerd dat de algoritmen niet genoeg input hebben om nauwkeurig te voorspellen, is een eenvoudige gemiddelde of handmatige voorspelling wellicht het beste. U kunt nieuwe items identificeren door te filteren op het aantal historische perioden.
Handmatige selectie van methoden
Zodra u rijen hebt geïdentificeerd waar de prognose niet logisch is voor het menselijk oog, kunt u een kleinere subset van alle methoden kiezen om de prognoserun toe te laten en te vergelijken met de geschiedenis. Met Smart kunt u een beperkte set methoden gebruiken voor slechts één prognoserun of de beperkte set insluiten om te gebruiken voor alle prognoseruns in de toekomst. Verschillende methoden zullen de geschiedenis op verschillende manieren in de toekomst projecteren. Als u een idee heeft van hoe elk werkt, kunt u kiezen welke u wilt toestaan.
Vertrouw op uw prognosetool
Hoe meer u Slimme periode-over-periode gebruikt om uw beslissingen over hoe te voorspellen en welke historische gegevens u in overweging moet nemen, vast te leggen, hoe minder vaak u uitzonderingen zult tegenkomen, zoals beschreven in deze blog. Het invoeren van prognoseparameters is een beheersbare taak wanneer u begint met kritieke items of items met een hoge impact. Zelfs als u geen handmatige beslissingen over prognosemethoden insluit, wordt de prognose elke periode opnieuw uitgevoerd met nieuwe gegevens. Dus een item met een oneven resultaat vandaag kan in de loop van de tijd gemakkelijk voorspelbaar worden.