In this blog, we will analyze the automatic forecasting for time series demand projections, focusing on key techniques, challenges, and best practices. There are multiple methods to predict future demand for an item, and this becomes complex when dealing with thousands of items, each requiring a different forecasting technique due to their unique demand patterns. Some items have stable demand, others trend upwards or downwards, and some exhibit seasonality. Selecting the right method for each item can be overwhelming. Here, we’ll explore how automatic forecasting simplifies this process.
Automatic forecasting becomes fundamental in managing large-scale demand projections. With thousands of items, manually selecting a forecasting method for each is impractical. Automatic forecasting uses software to make these decisions, ensuring accuracy and efficiency in the forecasting process. It’s importance lies in its ability to handle complex, large-scale forecasting needs efficiently. It eliminates the need for manual selection, saving time and reducing errors. This approach is particularly beneficial in environments with diverse demand patterns, where each item may require a different forecasting method.
Key Considerations for Effective Forecasting
- Challenges of Manual Forecasting:
- Infeasibility: Manually choosing forecasting methods for thousands of items is unmanageable.
- Inconsistency: Human error can lead to inconsistent and inaccurate forecasts.
- Criteria for Method Selection:
- Error Measurement: The primary criterion for selecting a forecasting method is the typical forecast error, defined as the difference between predicted and actual values. This error is averaged over the forecast horizon (e.g., monthly forecasts over a year).
- Holdout Analysis: This technique simulates the process of waiting for a year to elapse by hiding some historical data, making forecasts, and then revealing the hidden data to compute errors. This helps in choosing the best method in real-time.
- Forecasting Tournament:
- Method Comparison: Different methods compete to forecast each item, with the method producing the lowest average error winning.
- Parameter Tuning: Each method is tested with various parameters to find the optimal settings. For example, simple exponential smoothing may be tried with different weighting factors.
The Algorithms Behind Effective Automatic Forecasting
Automatic forecasting is highly computational but feasible with modern technology. The process involves:
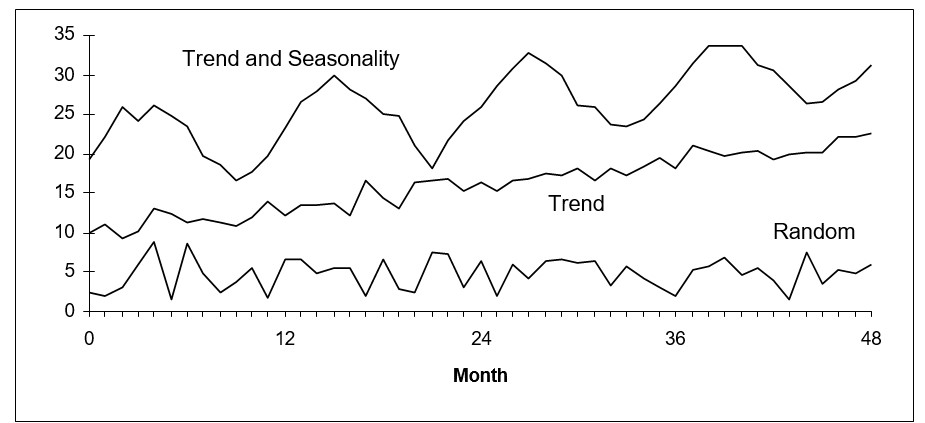
- Data Segmentation: Dividing historical data into segments helps manage and leverage different aspects of historical data for more accurate forecasting. For instance, for a product with seasonal demand, data might be segmented by seasons to capture season-specific trends and patterns. This segmentation allows forecasters to make and test forecasts more effectively.
- Repeated Simulations: Using sliding simulations involves repeatedly testing and refining forecasts over different periods. This method validates the accuracy of forecasting methods by applying them to different segments of data. An example is the sliding window method, where a fixed-size window moves across the time series data, generating forecasts for each position to evaluate performance.
- Parameter Optimization: Parameter optimization involves trying multiple variants of each forecasting method to find the best-performing one. By adjusting parameters, such as the smoothing factor in exponential smoothing methods or the number of past observations in ARIMA models, forecasters can fine-tune models to improve performance.
For instance, in our software, we allow various forecasting methods to compete for the best performance on a given item. Knowledge of Automatic forecasting immediately carries over to Simple Moving Average, linear moving average, Single Exponential Smoothing, Double Exponential Smoothing, Winters’ Exponential Smoothing, and Promo forecasting. This competition ensures that the most suitable method is selected based on empirical evidence, not subjective judgment. The tournament winner is the closest method to predicting new data values from old. Accuracy is measured by average absolute error (that is, the average error, ignoring any minus signs). The average is computed over a set of forecasts, each using a portion of the data, in a process known as sliding simulation, which we have explained previously in a previous blog.
Methods used in Automatic forecasting
Normally, there are six extrapolative forecasting methods competing in the Automatic forecasting tournament:
- Simple moving average
- Linear moving average
- Single exponential smoothing
- Double exponential smoothing
- Additive version of Winters’ exponential smoothing
- Multiplicative version of Winters’ exponential smoothing
The latter two methods are appropriate for seasonal series; however, they are automatically excluded from the tournament if there are fewer than two full seasonal cycles of data (for example, fewer than 24 periods of monthly data or eight periods of quarterly data). These six classical, smoothing-based methods have proven themselves to be easy to understand, easy to compute and accurate. You can exclude any of these methods from the tournament if you have a preference for some of the competitors and not others.
Automatic forecasting for time series data is essential for managing large-scale demand projections efficiently and accurately. Businesses can achieve better forecast accuracy and streamline their planning processes by automating the selection of forecasting methods and utilizing techniques like holdout analysis and forecasting tournaments. Embracing these advanced forecasting techniques ensures that businesses stay ahead in dynamic market environments, making informed decisions based on reliable data projections.