In almost every business and industry, decision-makers need reliable forecasts of critical variables, such as sales, revenues, product demand, inventory levels, market share, expenses, and industry trends.
Many kinds of people make these forecasts. Some are sophisticated technical analysts, such as business economists and statisticians. Many others regard forecasting as an important part of their overall work: general managers, production planners, inventory control specialists, financial analysts, strategic planners, market researchers, and product and sales managers. Still, others seldom think of themselves as forecasters but often have to make forecasts on an intuitive, judgmental basis.
Because of the way we designed Smart Demand Planner, it has something to offer all types of forecasters. This design grows out of several observations about the forecasting process. Because we designed Smart Demand Planner with these observations in mind, we believe it has a style and content uniquely suited for turning your browser into an effective forecasting and planning tool:
Forecasting is an art that requires a mix of professional judgment and objective, statistical analysis.
It is often effective to begin with an objective statistical forecast that automatically accounts for trends, seasonality, and other patterns. Then, apply adjustments or forecast overrides based on your business judgment. Smart Demand Planner makes it easy to execute graphical and tabular adjustments to statistical forecasts.
The forecasting process is usually iterative.
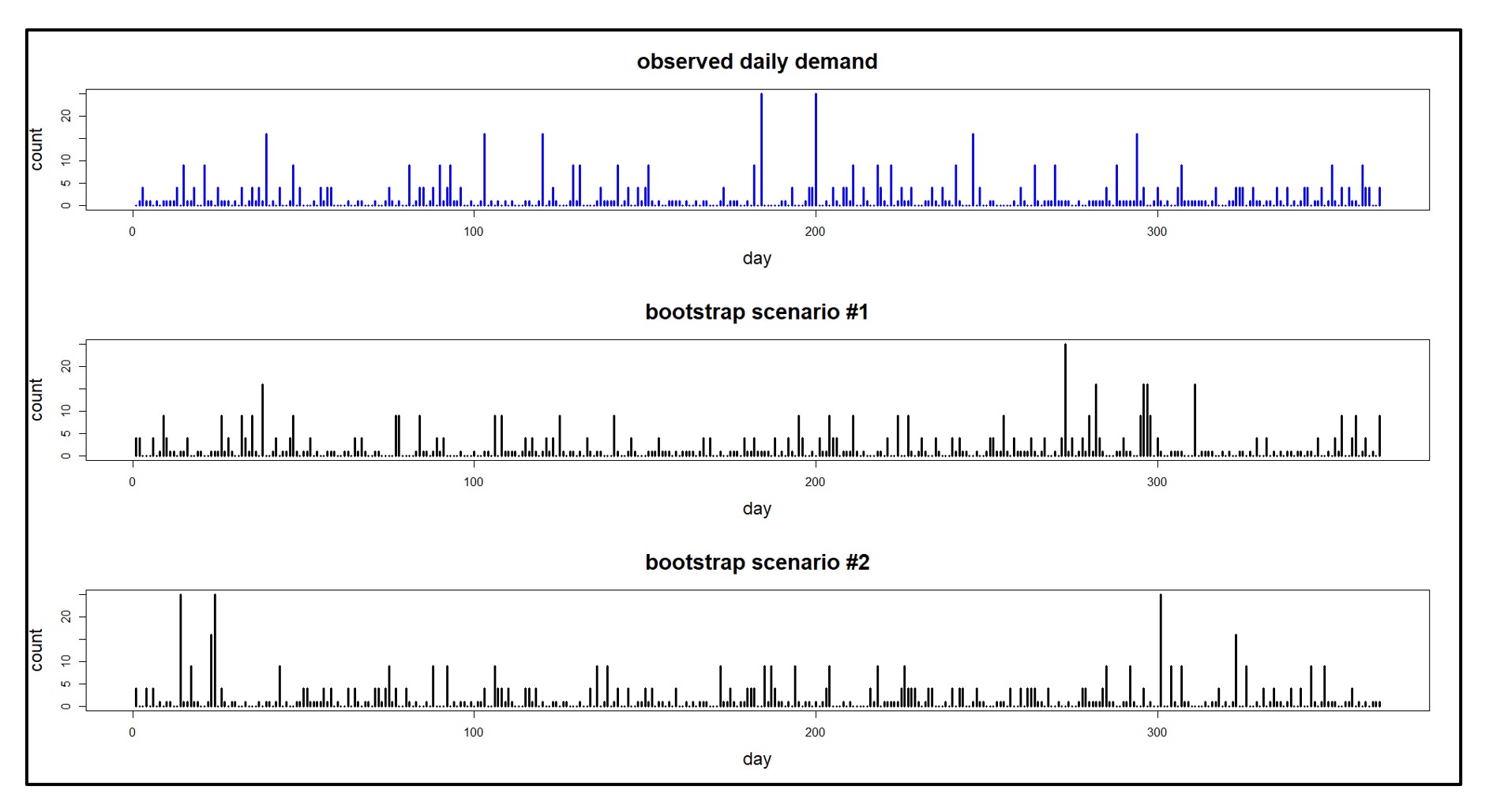
You will likely decide to make several refinements of your initial forecast before you are satisfied. You may want to exclude older historical data that you find to no longer be relevant. You could apply different weights to the forecast model that put varying emphases on the most recent data. You could apply trend dampening to increase or decrease aggressively trending statistical forecasts. You could allow the Machine Learning models to fine-tune the forecast selection for you and select the winning model automatically. Smart Demand Planner’s processing speed gives you plenty of time to make several passes and saves multiple versions of the forecasts as “snapshots” so you can compare forecast accuracy later.
Forecasting requires graphical support.
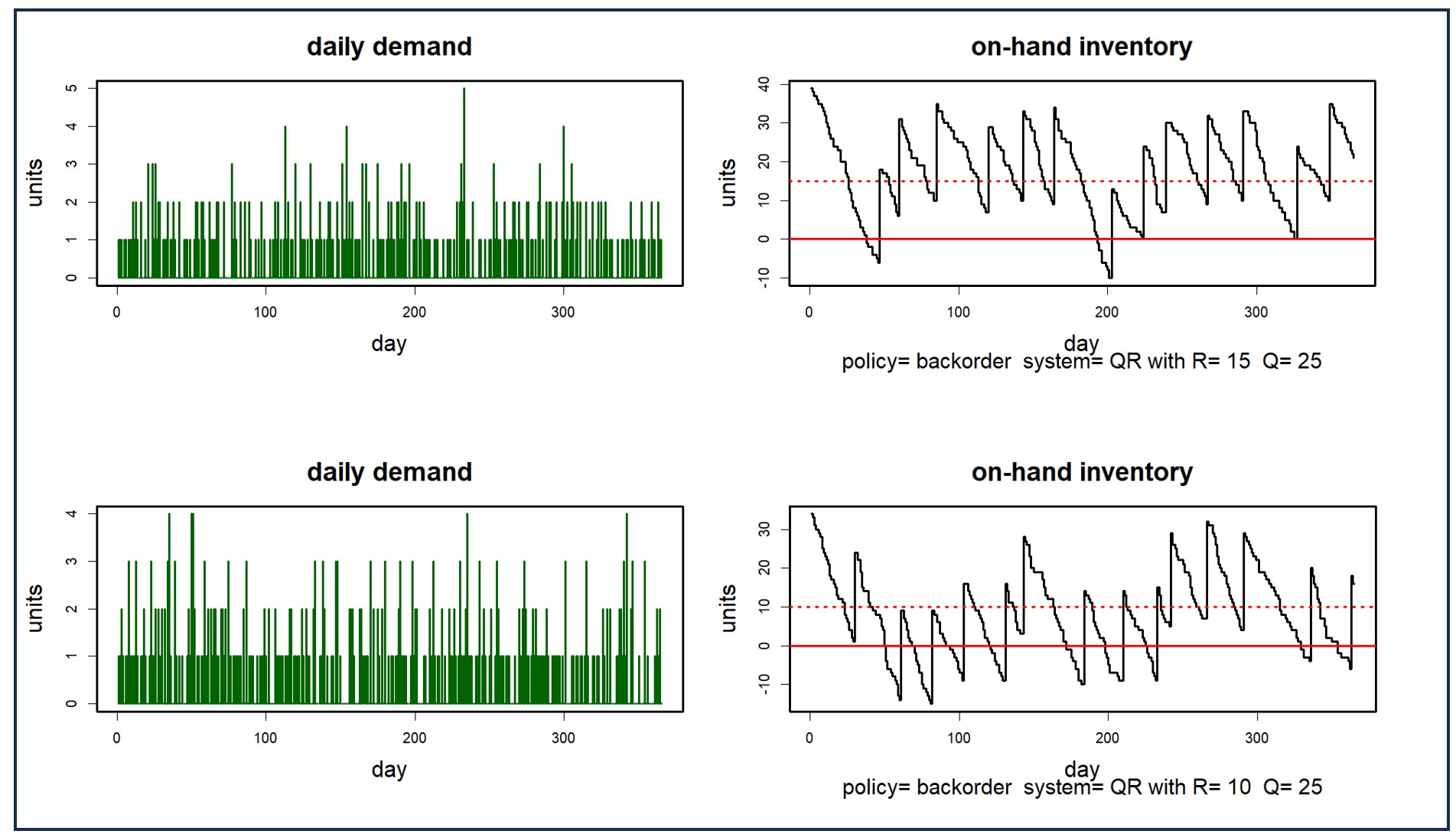
The patterns evident in data can be seen by a discerning eye. The credibility of your forecasts will often depend heavily on graphical comparisons other business stakeholders make when they assess the historical data and forecasts. Smart Demand Planner provides graphical displays of forecasts, history, and forecast vs. actuals reporting.
Forecasts are never exactly correct.
Because some error always creeps into even the best forecasting process, one of the most useful supplements to a forecast is an honest estimate of its margin of error.
Smart Demand Planner presents both graphical and tabular summaries of forecast accuracy based on the acid test of predicting data held back from development of the forecasting model.
Forecast intervals or confidence intervals are also very useful. They detail the likely range of possible demand that is expected to occur. For example, if actual demand falls outside of the 90% confidence interval more than 10% of the time then there is reason to investigate further.
Forecasting requires a match of method to data.
One of the major technical tasks in forecasting is to match the choice of forecasting technique to the nature of the data. Features of a data series like trend, seasonality or abrupt shifts in level suggest certain techniques instead of others.
Smart Demand Planner’ Automatic forecasting feature makes this match quickly, accurately and automatically.
Forecasting is often a part of a larger process of planning or control.
For example, forecasting can be a powerful complement to spreadsheet-based financial analysis, extending rows of figures off into the future. In addition, accurate sales and product demand forecasts are fundamental inputs to a manufacturer’s production planning and inventory control processes. An objective statistical forecast of future sales will always help identify when the budget (or sales plan) may be too unrealistic. Gap analysis enables the business to take corrective action to their demand and marketing plans to ensure they do not miss the budgeted plan.
Forecasts need to be integrated into ERP systems
Smart Demand Planner can quickly and easily transfer its results to other applications, such as spreadsheets, databases and planning systems including ERP applications. Users are able to export forecasts in a variety of file formats either via download or to secure FTP file locations. Smart Demand Planner includes API based integrations to a variety of ERP and EAM systems including Epicor Kinetic and Epicor Prophet 21, Sage X3 and Sage 300, Oracle NetSuite, and each of Microsoft’s Dynamics 365 ERP systems. API based integrations enable customers to push forecast results directly back to the ERP system on demand.
The result is more efficient sales planning, budgeting, production scheduling, ordering, and inventory planning.