Managing spare parts inventory is a critical component for businesses that depend on equipment uptime and service reliability. Unlike regular inventory items, spare parts often have unpredictable demand patterns, making them more challenging to manage effectively. An efficient spare parts inventory management system helps prevent stockouts that can lead to operational downtime and costly delays while also avoiding overstocking that unnecessarily ties up capital and increases holding costs.
In this blog, we’ll explore several effective strategies for managing spare parts inventory, emphasizing the importance of optimizing stock levels, maintaining service levels, and using smart tools to aid in decision-making.
For many industries—especially manufacturing, transportation, utilities, and any sector reliant on complex machinery—spare parts serve as the backbone of maintenance operations. Ineffective management can result in significant downtime when critical parts are unavailable, leading to production halts, service disruptions, and customer dissatisfaction. On the other hand, overstocking items that may not be used promptly ties up working capital, increases storage costs, and can lead to obsolescence.
Given that many spare parts experience intermittent and unpredictable demand, it is essential to have a clear and proactive strategy for managing them. Effective spare parts inventory management ensures operational efficiency, cost savings, and reliability, which can provide a competitive advantage in the marketplace.
Key Strategies for Managing Spare Parts Inventory
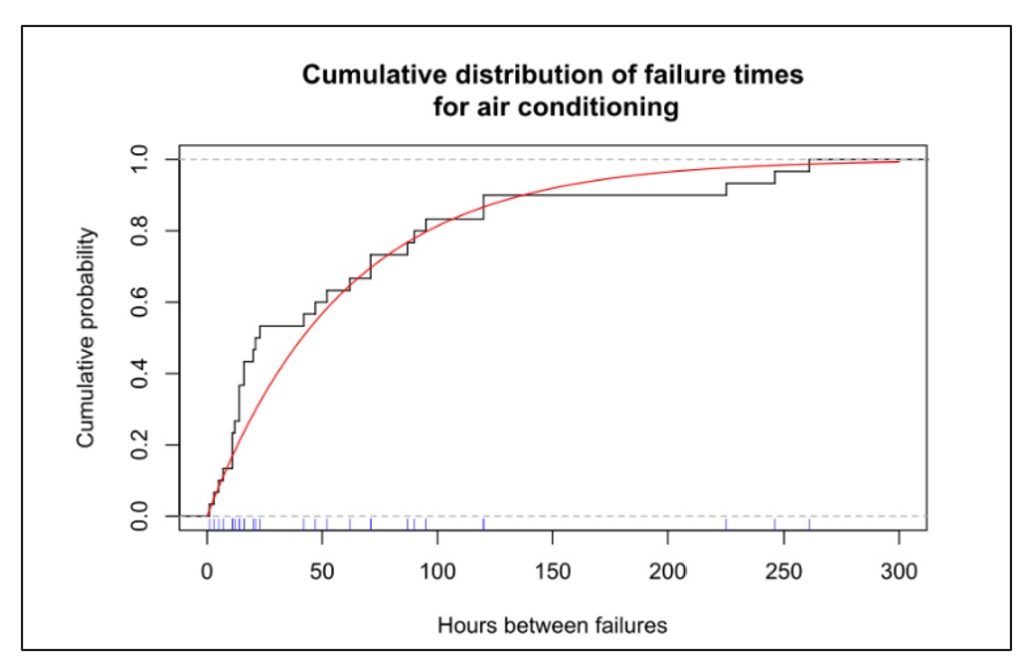
1. Forecasting Intermittent Demand. Spare parts often exhibit irregular demand patterns characterized by long periods of zero demand punctuated by sudden spikes when equipment failures occur. Traditional forecasting methods, which rely on consistent historical data trends, may not accurately predict such erratic usage. This can lead to either overstocking or stockouts.
Utilizing specialized forecasting tools like Smart IP&O’s patented intermittent demand forecasting algorithms can provide more accurate predictions. These advanced models analyze historical usage data, equipment failure rates, and maintenance schedules to adjust for demand variability. By incorporating probabilistic forecasting , machine learning, and AI techniques, now we can avoid both shortages that could halt operations and excess inventory that unnecessarily consumes resources.
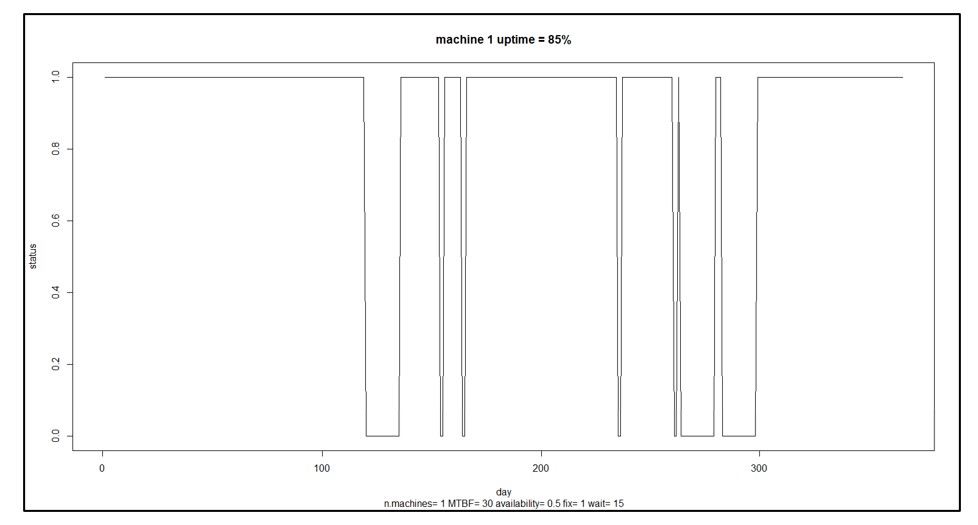
2. Setting Optimal Safety Stock Levels. Safety stock is essential for mitigating the risk of stockouts, especially for critical spare parts. Safety stock should account for lead time variability, demand fluctuations, and the criticality of the part. Using systems that calculate optimal safety stock levels based on these factors ensures that your parts are available when needed without excessive overstock. Safety stock settings should be reviewed regularly as part of an ongoing inventory optimization process.
3. Using Min/Max Inventory Policies. A common approach to spare parts inventory is using Min/Max policies, where inventory is replenished up to a maximum level once it drops below a minimum threshold. This system allows for flexibility and ensures that stock levels are maintained without requiring constant monitoring. Adjusting these parameters based on service level goals can ensure you’re not carrying excess inventory while still meeting demand.
4. Inventory Optimization involves balancing holding costs, stockout costs, and desired service levels to achieve the most cost-effective inventory management strategy. Software solutions like Smart IP&O can simulate various demand and supply scenarios and calculate the optimal inventory policies.
By leveraging advanced AI algorithms and data analytics, Smart IP&O helps organizations determine the right inventory levels for each spare part, considering factors like demand variability, lead times, and cost constraints. This ensures that you maintain the right balance between having sufficient inventory to meet demand and minimizing the costs associated with overstocking. Moreover, optimization tools allow for continuous adjustments based on real-time data and shifting demand patterns, enabling organizations to respond proactively to market or supply chain changes.
5. Regular Review of Supplier Lead Times Supplier performance and lead times can significantly impact your spare parts strategy. Delivery delays can cause stockouts if not accounted for in your planning. Monitoring actual lead times against expected performance helps adjust reorder points and safety stock levels accordingly. Systems like Smart IP&O provide detailed reporting on supplier performance, including lead time variability, on-time delivery rates, and quality metrics. With access to this information, you can identify potential risks in your supply chain and take proactive measures, such as finding alternative suppliers or adjusting inventory policies, to mitigate the impact of supplier unreliability.
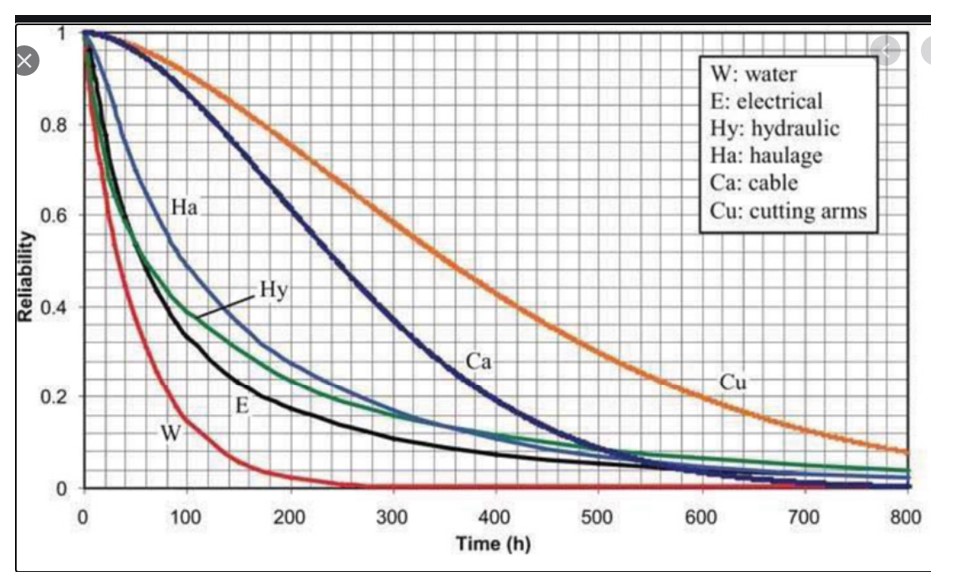
6. Managing Obsolescence. Spare parts often become obsolete when equipment is upgraded or phased out. Holding onto obsolete inventory ties up capital and occupies valuable warehouse space. Regularly reviewing your inventory for items nearing obsolescence can prevent excess stock. Methods such as using cycle stock and safety stock calculations based on demand can help mitigate the risks of holding onto outdated inventory.
7. Automating Inventory Processes. Automation in inventory management can significantly reduce manual errors, increase efficiency, and ensure timely replenishment of spare parts. Tools like Smart IP&O automate many forecasting, optimization, and replenishment tasks that would otherwise be labor-intensive and prone to human error.
By integrating these tools with existing ERP systems, organizations can achieve seamless updates and adjustments based on the latest demand and supply data. Automation enables real-time visibility into inventory levels, demand trends, and supply chain disruptions, allowing for quicker decision-making and enhanced responsiveness to changes. Moreover, automation frees up personnel to focus on strategic tasks rather than routine data entry and calculations.
Managing spare parts inventory effectively ensures operational continuity and avoids unnecessary costs. By leveraging advanced forecasting tools, setting optimal safety stock levels, and using smart inventory optimization strategies, companies can minimize stockouts, reduce holding costs, and enhance overall service levels. Continuous improvement and the integration of technology into the inventory management process provide significant long-term benefits for any organization reliant on spare parts. Embracing these best practices not only contributes to operational efficiency but also supports strategic objectives such as cost reduction, customer satisfaction, and competitive advantage.
White Paper: What you Need to know about Forecasting and Planning Service Parts
This paper describes Smart Software’s patented methodology for forecasting demand, safety stocks, and reorder points on items such as service parts and components with intermittent demand, and provides several examples of customer success.