If you had your head up lately, you may have noticed some additional madness off the basketball court: The failure of Silicon Valley Bank. Those of us in the supply chain world may have dismissed the bank failure as somebody else’s problem, but that sorry episode holds a big lesson for us, too: The importance of stress testing done right.
The Washington Post recently carried an opinion piece by Natasha Sarin called “Regulators missed Silicon Valley Bank’s problems for months. Here’s why.” Sarin outlined the flaws in the stress testing regime imposed on the bank by the Federal Reserve. One problem is that the stress tests are too static. The Fed’s stress factor for nominal GDP growth was a single scenario listing presumed values over the next 13 quarters (see Figure 1). Those 13 quarterly projections might be somebody’s consensus view of what a bad hair day would look like, but that’s not the only way things could play out. As a society, we are being taught to appreciate a better way to display contingencies every time the National Weather Service shows us projected hurricane tracks (see Figure 2). Each scenario represented by a different colored line shows a possible storm path, with the concentrated lines representing the most likely. By exposing the lower probability paths, risk planning is improved.
When stress testing the supply chain, we need realistic scenarios of possible future demands that might occur, even extreme demands. Smart provides this in our software (with considerable improvements in our Gen2 methods). The software generates a huge number of credible demand scenarios, enough to expose the full scope of risks (see Figure 3). Stress testing is all about generating massive numbers of planning scenarios, and Smart’s probabilistic methods are a radical departure from previous deterministic S&OP applications, being entirely scenario based.
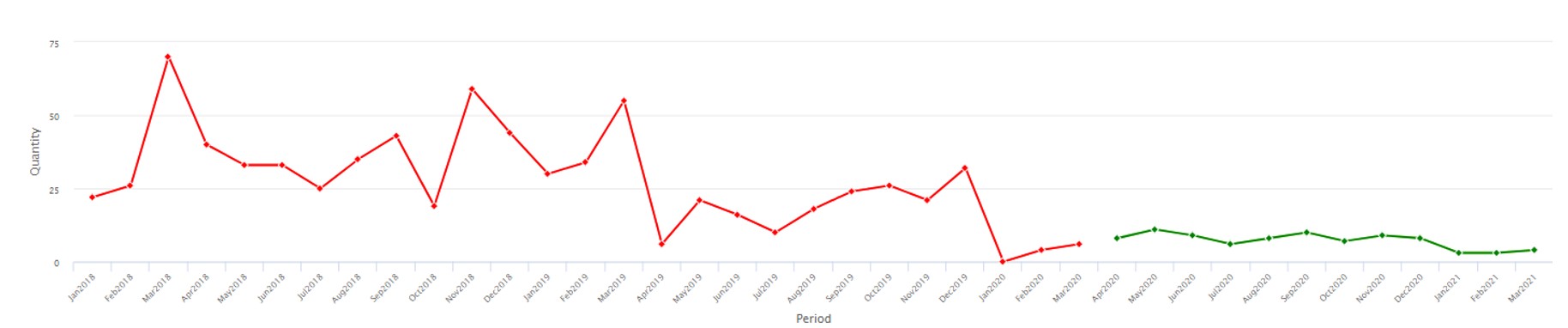
The other flaw in the Fed’s stress tests was that they were designed months in advance but never updated for changing conditions. Demand planners and inventory managers intuitively appreciate that key variables like item demand and supplier lead time are not only highly random even when things are stable but also subject to abrupt shifts that should require rapid rewriting of planning scenarios (see Figure 4, where the average demand jumps up dramatically between observations 19 and 20). Smart’s Gen2 products include new tech for detecting such “regime changes” and automatically changing scenarios accordingly.
Banks are forced to undergo stress tests, however flawed they may be, to protect their depositors. Supply chain professionals now have a way to protect their supply chains by using modern software to stress test their demand plans and inventory management decisions.
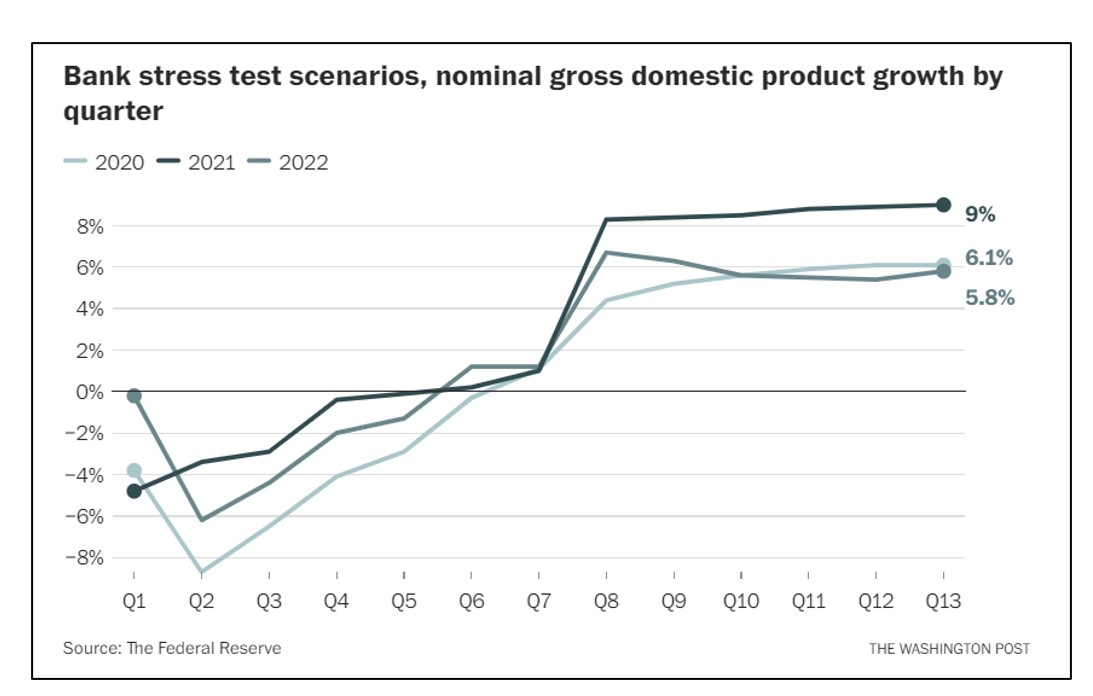
Figure 1: Scenarios used the Fed to stress test banks.

Figure 2: Scenarios used by the National Weather Service to predict hurricane tracks
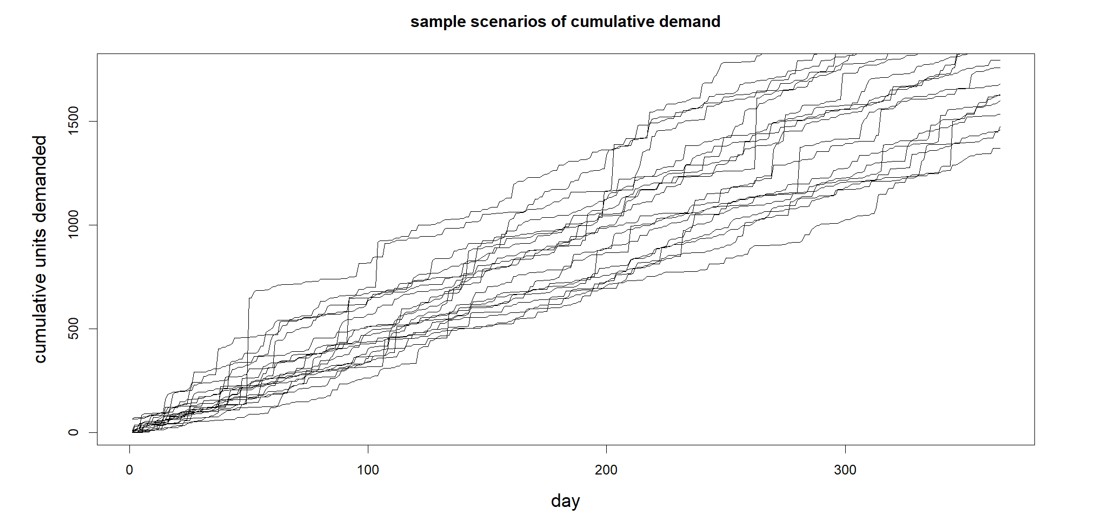
Figure 3: Demand scenarios of the type generated by Smart Demand Planner
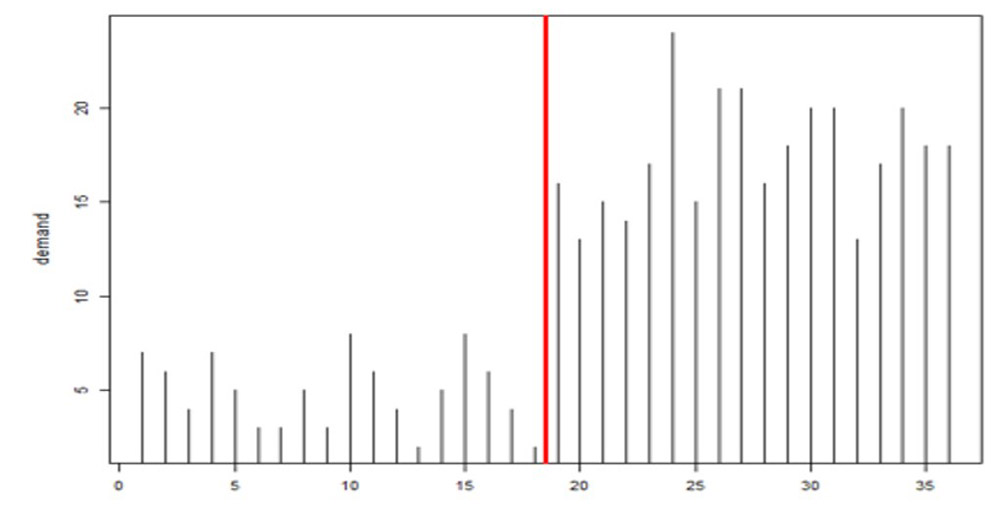
Figure 4: Example of regime change in product demand after observation #19