Op prognoses gebaseerd voorraadbeheer, of MRP-logica (Material Needs Planning), is een methodologie voor vooruitplanning voor het beheer van voorraad. Deze methode zorgt ervoor dat bedrijven aan de vraag kunnen voldoen zonder overbevoorrading, wat kapitaal vastlegt, of onderbevoorrading, wat kan leiden tot omzetverlies en ontevreden klanten.
Door te anticiperen op de vraag en de voorraadniveaus dienovereenkomstig aan te passen, helpt deze aanpak het juiste evenwicht te behouden tussen het hebben van voldoende voorraad om aan de behoeften van de klant te voldoen en het minimaliseren van overtollige voorraadkosten. Bedrijven kunnen hun activiteiten optimaliseren, verspilling verminderen en de klanttevredenheid verbeteren door toekomstige behoeften te voorspellen. Laten we eens kijken hoe dit werkt.
Kernconcepten van op prognoses gebaseerd voorraadbeheer
Voorraaddynamiekmodellen: Voorraaddynamiekmodellen zijn van fundamenteel belang voor het begrijpen en beheren van voorraadniveaus. Het eenvoudigste model, bekend als het ‘zaagtandmodel’, laat zien dat voorraadniveaus afnemen naarmate de vraag toeneemt en zich net op tijd aanvult. Real-world scenario's vereisen echter vaak geavanceerdere modellen. Door stochastische elementen en variabiliteit op te nemen, zoals Monte Carlo-simulaties, kunnen bedrijven rekening houden met willekeurige schommelingen in de vraag en doorlooptijd, waardoor een realistischere voorspelling van de voorraadniveaus ontstaat.
IP&O-platform verbetert de modellering van de voorraaddynamiek door middel van geavanceerde data-analyse en simulatiemogelijkheden. Door gebruik te maken van AI en machine learning-algoritmen kan ons IP&O-platform vraagpatronen nauwkeuriger voorspellen en modellen in realtime aanpassen op basis van de nieuwste gegevens. Dit leidt tot nauwkeurigere voorraadniveaus, waardoor het risico op voorraadtekorten en overbevoorrading wordt verminderd.
Bestelhoeveelheid en timing bepalen: Effectief voorraadbeheer vereist dat u weet wanneer en hoeveel u moet bestellen. Dit omvat het voorspellen van de toekomstige vraag en het berekenen van de doorlooptijd voor het aanvullen van de voorraad. Door te voorspellen wanneer de voorraad het veiligheidsvoorraadniveau bereikt, kunnen bedrijven hun bestellingen plannen om een continue levering te garanderen.
Onze nieuwste tools blinken uit in het optimaliseren van bestelhoeveelheden en timing door gebruik te maken van voorspellende analyses en AI. Deze systemen kunnen enorme hoeveelheden gegevens analyseren, inclusief historische verkopen en markttrends. Door dit te doen, bieden ze nauwkeurigere vraagprognoses en optimaliseren ze de bestelpunten, zodat de voorraad precies op tijd wordt aangevuld zonder dat er overtollige voorraad ontstaat.
Doorlooptijd berekenen: Doorlooptijd is de periode vanaf het plaatsen van een bestelling tot het ontvangen van de voorraad. Het varieert afhankelijk van de beschikbaarheid van componenten. Als een product bijvoorbeeld uit meerdere componenten wordt samengesteld, wordt de doorlooptijd bepaald door het onderdeel met de langste doorlooptijd.
Slimme AI-gestuurde oplossingen verbeteren de berekening van de doorlooptijd door te integreren met supply chain managementsystemen. Deze systemen volgen de prestaties van leveranciers en historische doorlooptijden om nauwkeurigere schattingen van de doorlooptijd te bieden. Bovendien kunnen slimme technologieën bedrijven waarschuwen voor mogelijke vertragingen, waardoor proactieve aanpassingen aan voorraadplannen mogelijk worden.
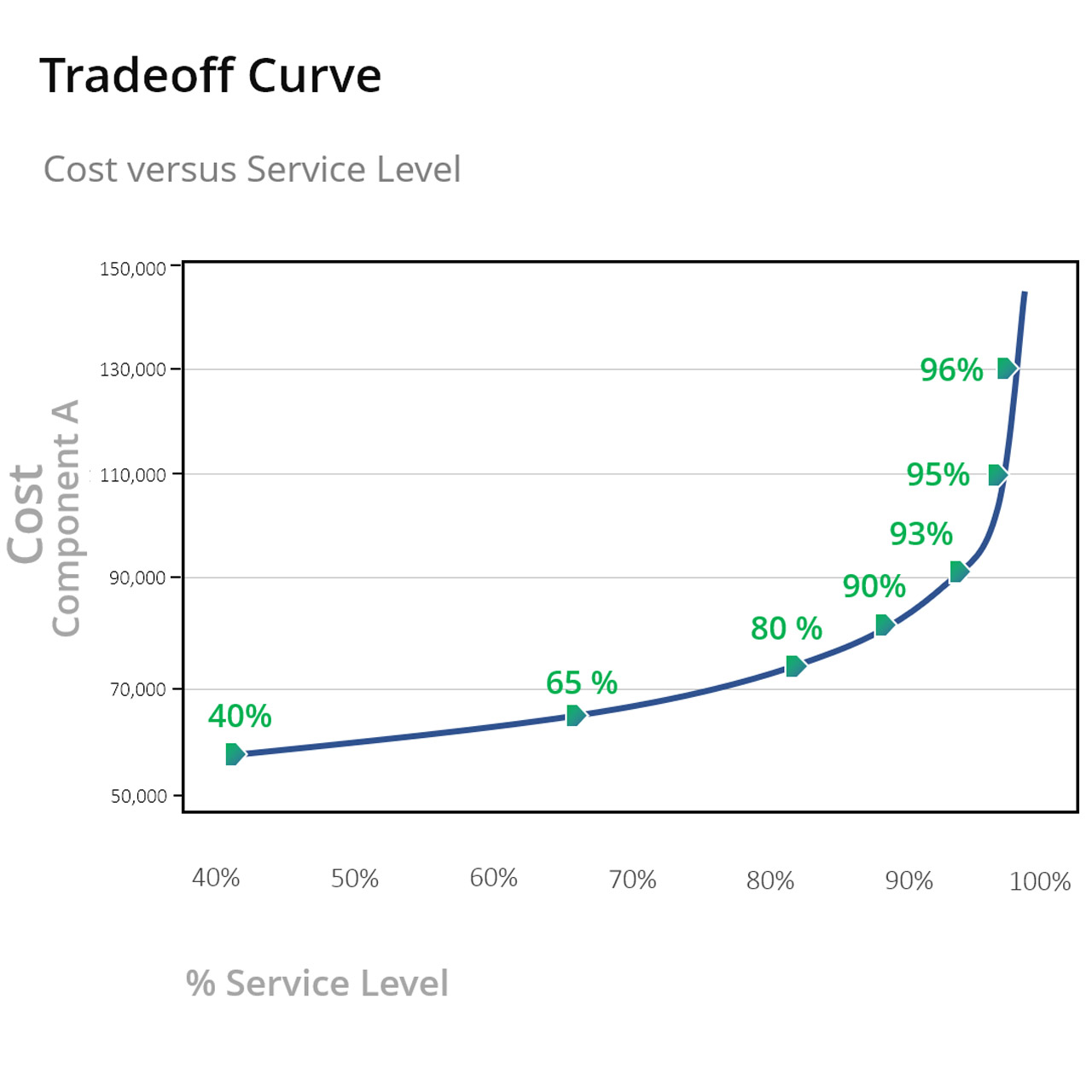
Berekening van de veiligheidsvoorraad: De veiligheidsvoorraad fungeert als buffer om te beschermen tegen variabiliteit in vraag en aanbod. Het berekenen van de veiligheidsvoorraad omvat het analyseren van de variabiliteit van de vraag en het instellen van een voorraadniveau dat de meeste potentiële scenario's dekt, waardoor het risico op voorraadtekorten wordt geminimaliseerd.
IP&O-technologie verbetert de berekening van de veiligheidsvoorraad aanzienlijk door middel van geavanceerde analyses. Door vraagpatronen en supply chain-variabelen voortdurend te monitoren, kunnen slimme systemen de veiligheidsvoorraadniveaus dynamisch aanpassen. Machine learning-algoritmen kunnen vraagpieken of -dalingen voorspellen en de veiligheidsvoorraad dienovereenkomstig aanpassen, waardoor optimale voorraadniveaus worden gegarandeerd en de voorraadkosten worden geminimaliseerd.
Het belang van nauwkeurige prognoses bij voorraadbeheer
Nauwkeurige prognoses zijn essentieel voor het minimaliseren van prognosefouten, die kunnen leiden tot overtollige voorraad of voorraadtekorten. Technieken zoals het gebruik van historische gegevens, het verbeteren van gegevensinvoer en het toepassen van geavanceerde voorspellingsmethoden helpen een betere nauwkeurigheid te bereiken. Voorspellingsfouten kunnen aanzienlijke financiële gevolgen hebben: te hoge prognoses resulteren in overtollige voorraad, terwijl te lage prognoses leiden tot gemiste verkoopkansen. Het beheren van deze fouten door middel van het systematisch volgen en aanpassen van prognosemethoden is cruciaal voor het handhaven van optimale voorraadniveaus.
De veiligheidsvoorraad zorgt ervoor dat bedrijven aan de behoeften van de klant kunnen voldoen, zelfs als de werkelijke vraag afwijkt van de prognose. Dit kussen beschermt tegen onvoorziene vraagpieken of vertragingen bij de bevoorrading. Nauwkeurige prognoses, effectief foutenbeheer en strategisch gebruik van de veiligheidsvoorraad verbeteren het op prognoses gebaseerde voorraadbeheer. Bedrijven kunnen de voorraaddynamiek begrijpen, de juiste bestelhoeveelheden en timing bepalen, nauwkeurige doorlooptijden berekenen en de juiste veiligheidsvoorraadniveaus instellen.
Het gebruik van state-of-the-art technologie zoals IP&O biedt aanzienlijke voordelen door het bieden van realtime data-inzichten, voorspellende analyses en adaptieve modellen. Dit leidt tot efficiënter voorraadbeheer, lagere kosten en verbeterde klanttevredenheid. Over het geheel genomen stelt IP&O bedrijven in staat beter te plannen en snel te reageren op marktveranderingen, waardoor ze de juiste voorraadbalans behouden om aan de behoeften van de klant te voldoen zonder onnodige kosten te maken.