Those of you who track hot topics will be familiar with the term “digital twin.” Those who have been too busy with work may want to read on and catch up.
What is a digital twin?
While there are several definitions of digital twin, here’s one that works well:
A digital twin is a dynamic virtual copy of a physical asset, process, system, or environment that looks like and behaves identically to its real-world counterpart. A digital twin ingests data and replicates processes so you can predict possible performance outcomes and issues that the real-world product might undergo. [Source: Unity.com]. For additional background, you might go to Mckinsey.com.
What is the difference between a digital twin (hereafter DT) and a model? Primarily, a DT gets connected to real-time data to maintain the model as an up-to-the-minute representation of the system you are working with.
Our current products might be called “slow-motion DT’s” because they are usually used with non-real-time data (though not stale data, since it is updated overnight) and applied to problems like planning the next quarter’s raw material buys or setting inventory parameters for a month or longer.
Are people using digital twins in my industry?
My impression is that the penetration of DT’s may be highest in the aerospace and nuclear industries. Most of our customers are elsewhere: in manufacturing, distribution, and public utilities such as transportation and power. Soon we’ll be offering new products that come closer to the strict definition of a DT that is connected intimately to the system it represents.
DT Preview
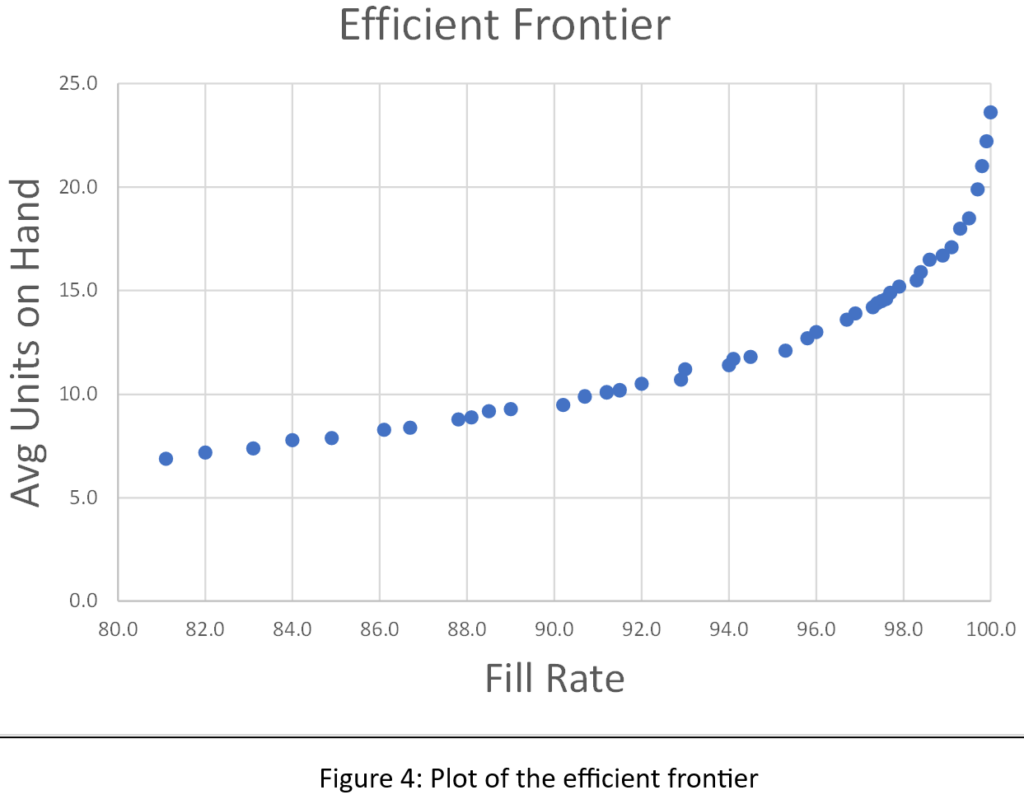
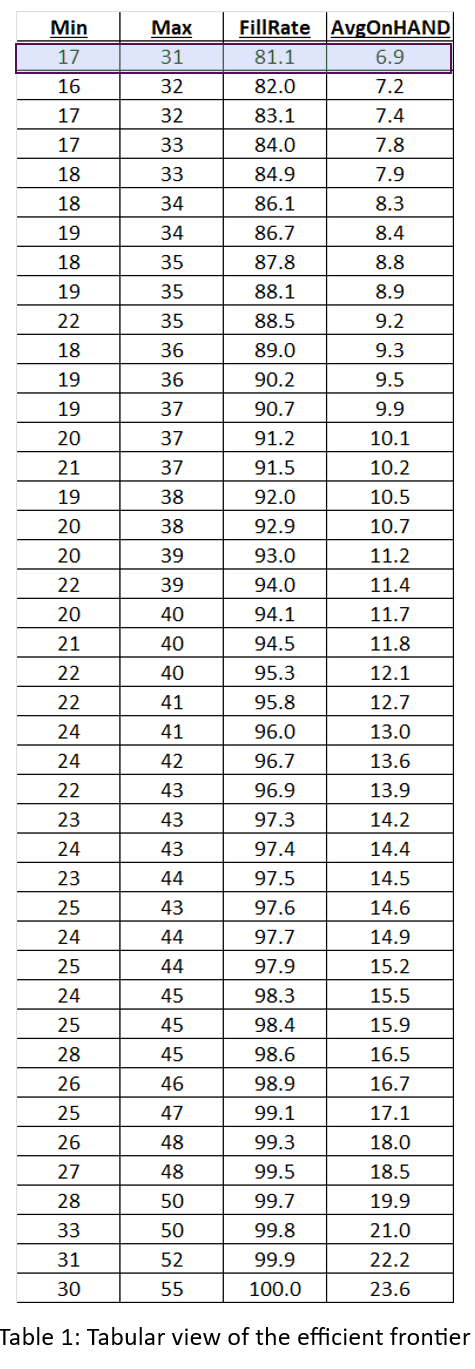
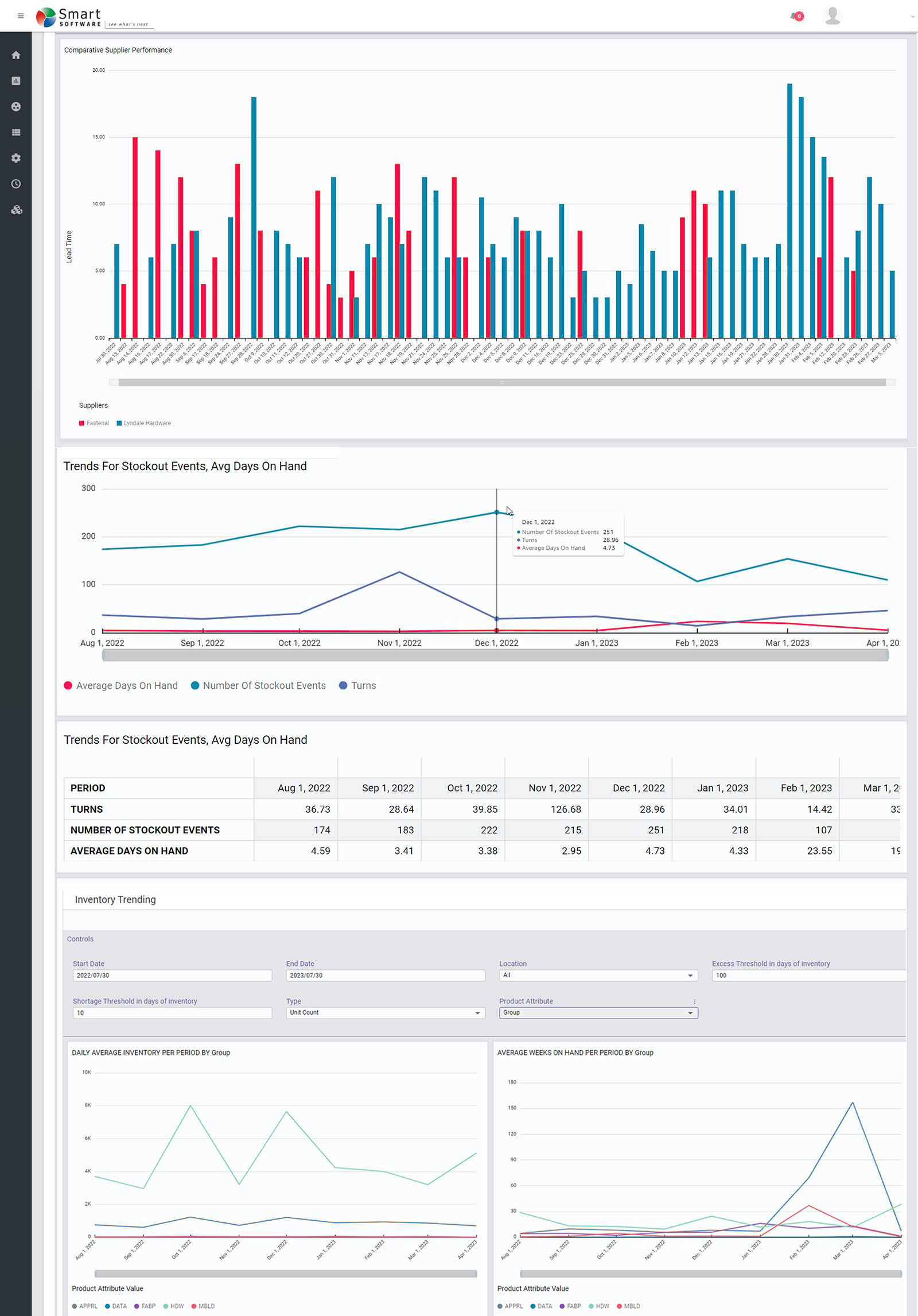
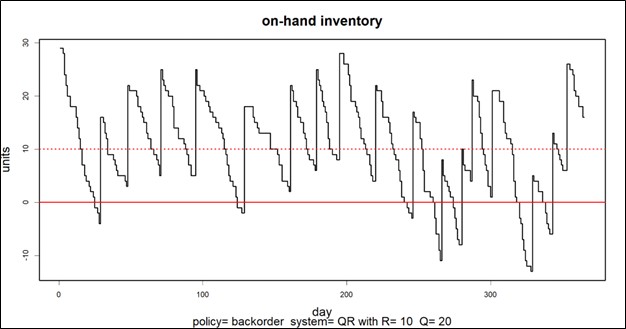
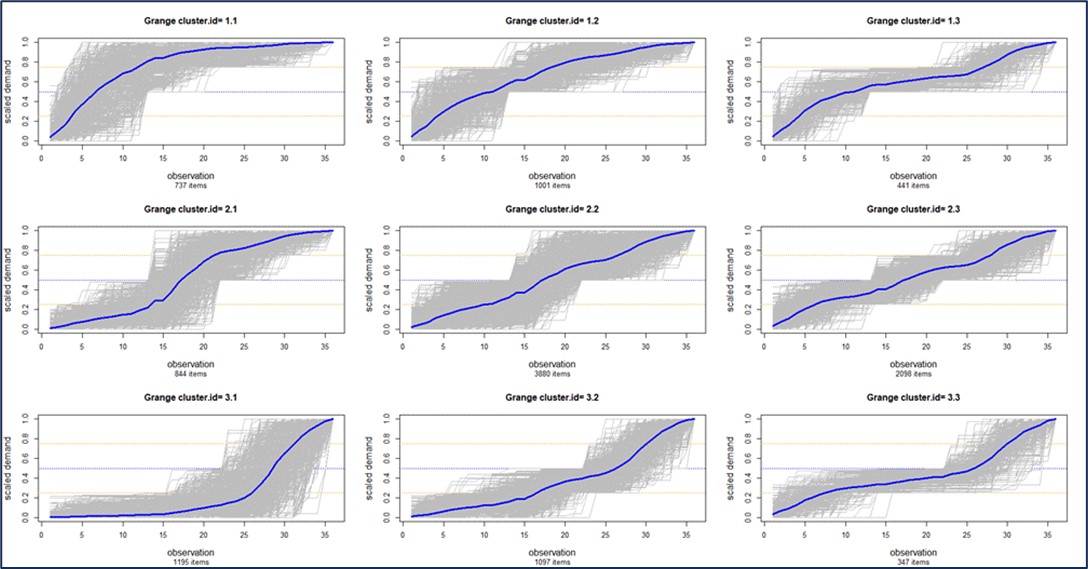
Most users of Smart Inventory Optimization™ (SIO) run the application periodically, typically monthly. SIO analyzes current demand for inventory items and recent supplier lead times, converting these into demand and supply scenarios, respectively. Then users either interactively (for individual items) or automatically (at scale) set inventory control parameters that will provide the long-term average performance they want, balancing the competing goals of minimizing inventory while guaranteeing a sufficient level of item availability.
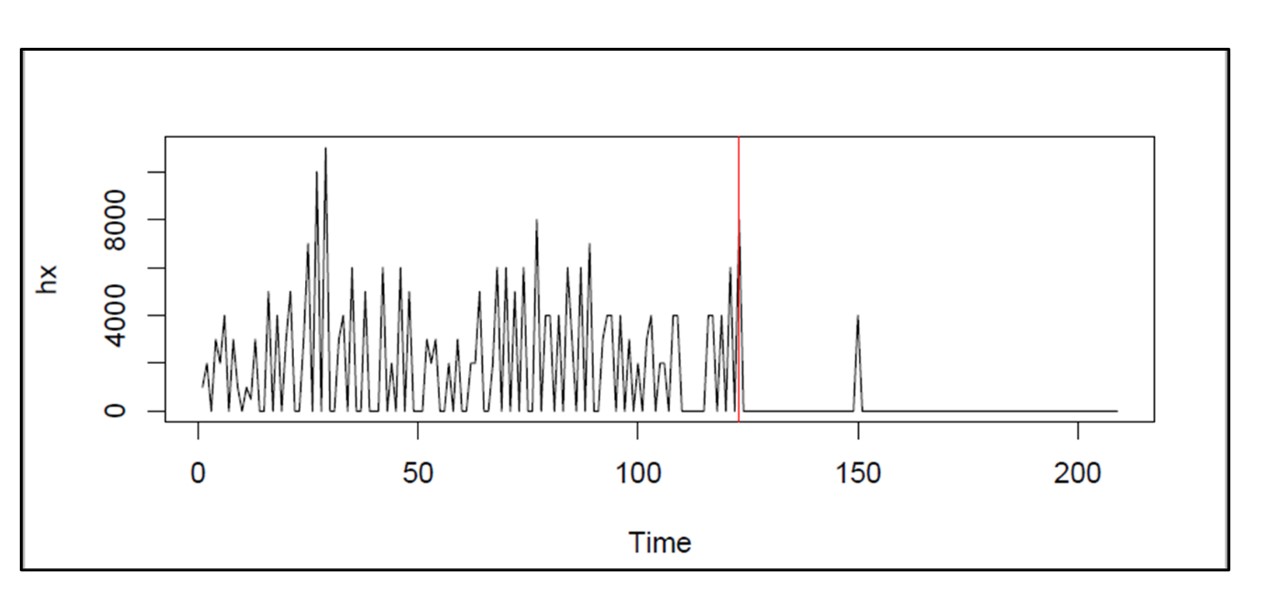
Smart Supply Planner (SSP) operates in a more immediate way to react to contingencies. Any day could bring an anomalous order that spikes up demand, such as when a new customer places a surprising initial stocking order. Or a key supplier could experience a problem at its factory and be forced to delay shipment of your planned replenishment orders. In the long run, these contingencies average out and justify the recommendations coming out of SIO. However, SSP will give you a way to react in the short run to seize opportunities or dodge bullets.
At its core, SSP operates like SIO in that it is scenario driven. The differences are that it uses short planning horizons and uses real-time initial conditions as the basis for its simulations of inventory system performance. Then it will provide real-time recommendations for interventions that offset the disruption caused by the contingencies. These would include cancelling or expediting replenishment orders.
Summary
Digital twins let you try out plans “in silico” before you implement them in the factory or warehouse. At their core are mathematical models of your operation but connected to real-time data. They provide a “digital sandbox” in which you can try out ideas and get immediate predictions of how well they will work. Much more than a spreadsheet, DT’s will soon be the key tool in your inventory planning toolbox.