In dit artikel zullen we de functionaliteit voor 'voorgestelde bestellingen' in Epicor BisTrack bekijken, de beperkingen ervan uitleggen en samenvatten hoe Smart Inventory Planning & Optimization (Smart IP&O) kan helpen de voorraad te verminderen en voorraadtekorten te minimaliseren door de afwegingen tussen voorraadrisico's nauwkeurig te beoordelen. en voorraadkosten.
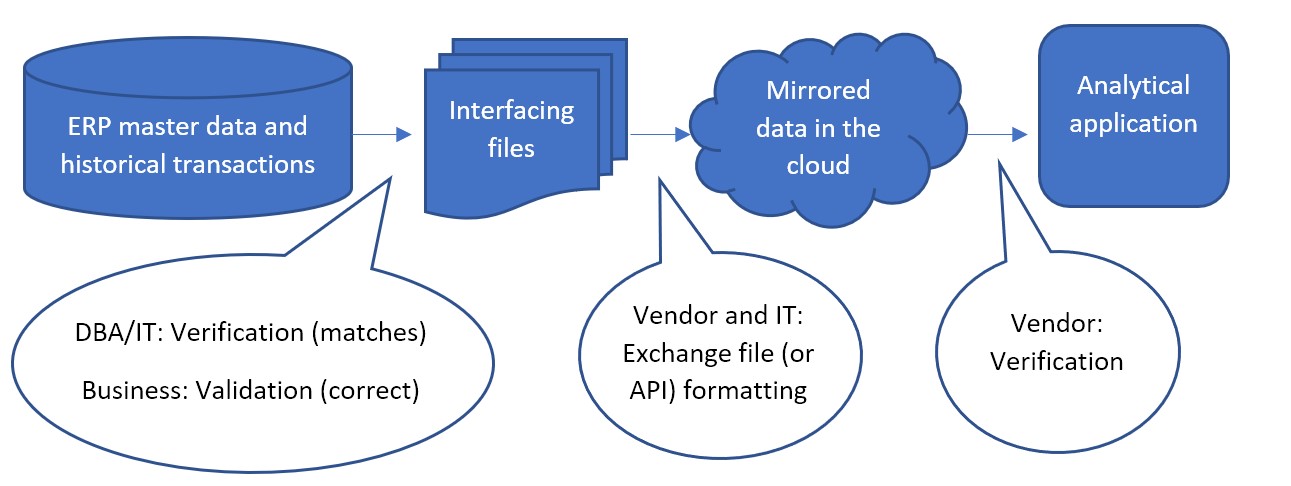
Automatisering van bevoorrading in Epicor BisTrack
Epicor BisTrack's “Suggested Ordering” kan de aanvulling beheren door voor te stellen wat te bestellen en wanneer, via op punten gebaseerd beleid voor herbestelling, zoals min-max en/of handmatig gespecificeerde leveringsweken. BisTrack bevat een aantal basisfunctionaliteiten om deze parameters te berekenen op basis van gemiddeld gebruik of omzet, doorlooptijd van leveranciers en/of door de gebruiker gedefinieerde seizoensaanpassingen. Als alternatief kunnen nabestelpunten volledig handmatig worden opgegeven. BisTrack presenteert de gebruiker vervolgens een lijst met voorgestelde bestellingen door inkomend aanbod, huidige voorraad, uitgaande vraag en voorraadbeleid op elkaar af te stemmen.
Hoe Epicor BisTrack “Aanbevolen bestelling” werkt
Om een lijst met voorgestelde bestellingen te krijgen, specificeren gebruikers de methoden achter de suggesties, inclusief locaties waarvoor ze bestellingen moeten plaatsen en hoe ze het voorraadbeleid kunnen bepalen dat bepaalt wanneer een suggestie wordt gedaan en in welke hoeveelheid.
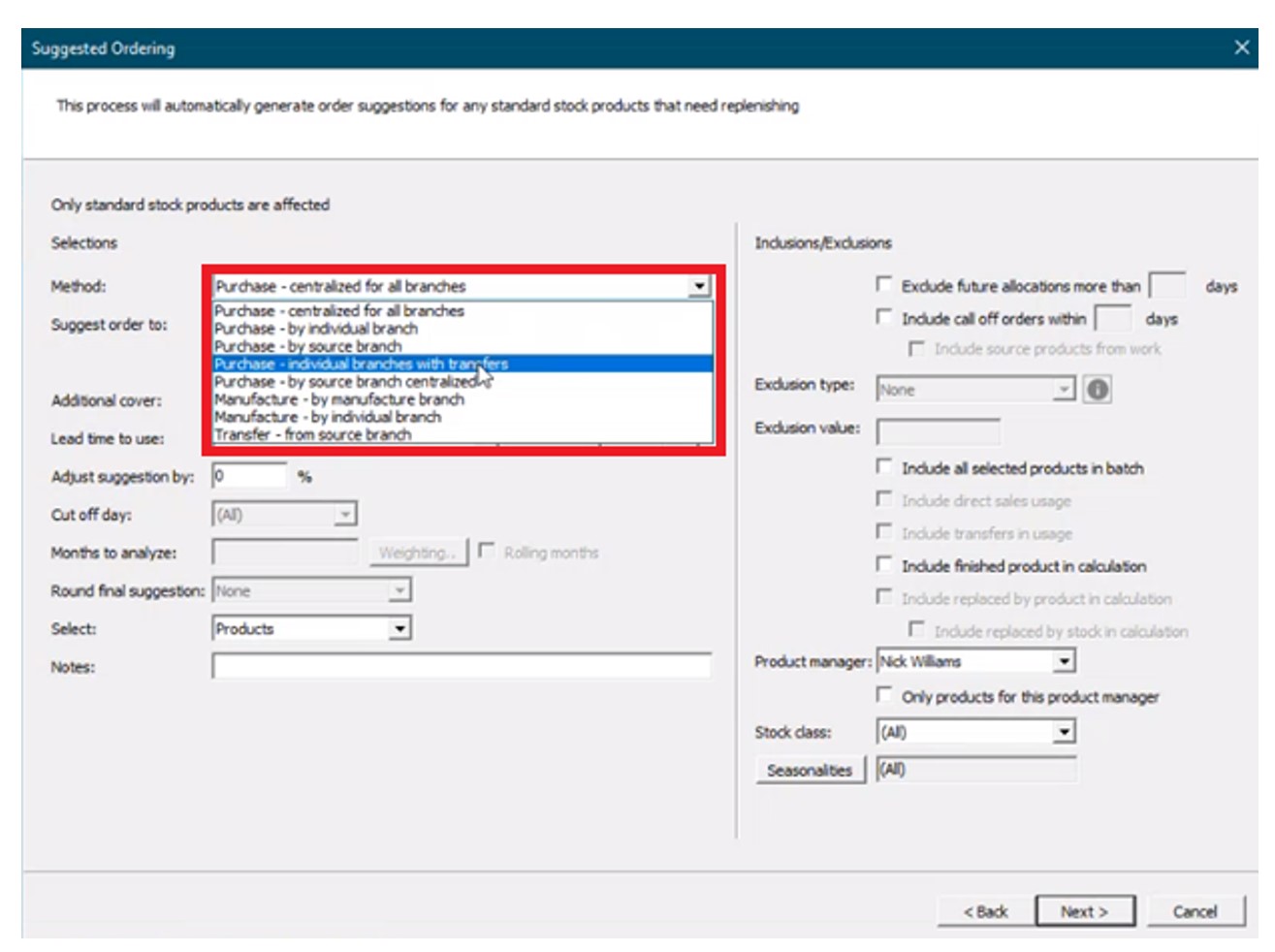
Eerst wordt het veld “methode” gespecificeerd uit de volgende opties om te bepalen welk soort suggestie wordt gegenereerd en voor welke locatie(s):
Aankoop – Aanbevelingen voor inkooporders genereren.
- Gecentraliseerd voor alle vestigingen – Genereert suggesties voor één locatie die inkopen doet voor alle andere locaties.
- Per individueel filiaal – Genereert suggesties voor meerdere locaties (leveranciers verzenden rechtstreeks naar elk filiaal).
- Per bronvertakking – Genereert suggesties voor een bronvertakking die materiaal zal overbrengen naar vertakkingen die deze bedient (“hub en sprak”).
- Individuele vestigingen met overdrachten – Genereert suggesties voor een individuele vestiging die materiaal zal overdragen naar vestigingen die zij bedient (“hub and spoke”, waarbij de “hub” geen bronfiliaal hoeft te zijn).
Vervaardiging – Genereer werkordersuggesties voor gefabriceerde goederen.
- Per productietak.
- Per individuele vestiging.
Overdracht van brontak – Genereer overdrachtssuggesties van een bepaalde vestiging naar andere vestigingen.
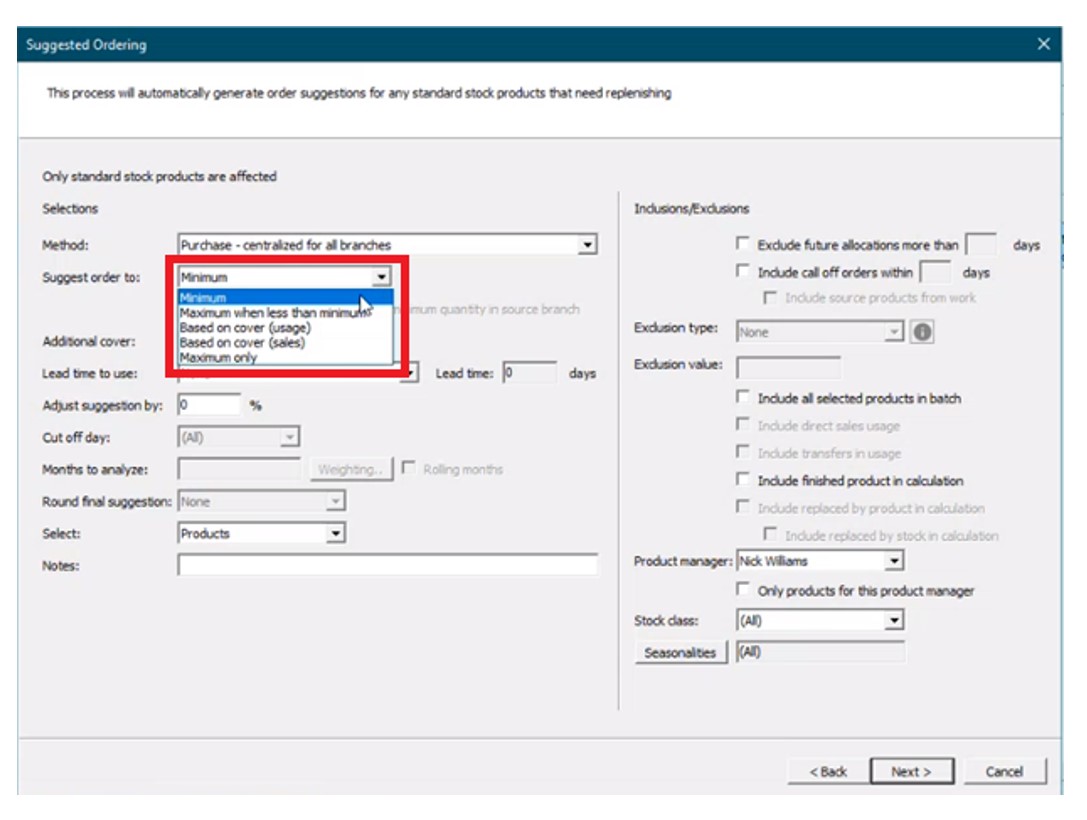
Vervolgens wordt de “bestelling voorstellen aan” gespecificeerd uit de volgende opties:
- Minimum – Stelt bestellingen voor “tot” de minimale beschikbare hoeveelheid (“min”). Voor elk artikel waarvan de voorraad minder is dan de minimumhoeveelheid, zal BisTrack een bestelsuggestie voorstellen om aan te vullen tot dit aantal.
- Maximaal wanneer minder dan min – Stelt bestellingen voor “tot” een maximale voorhanden hoeveelheid wanneer de minimale voorhanden hoeveelheid wordt overschreden (bijvoorbeeld een min-max voorraadbeleid).
- Gebaseerd op dekking (gebruik) – Stelt bestellingen voor op basis van dekking voor een door de gebruiker gedefinieerd aantal leveringsweken met betrekking tot een opgegeven doorlooptijd. Intern gegeven gebruik Afhankelijk van de vraag zal BisTrack bestellingen aanbevelen waarbij het aanbod kleiner is dan de gewenste dekking om het verschil te dekken.
- Gebaseerd op meer dan (verkoop) – Stelt bestellingen voor op basis van dekking voor een door de gebruiker gedefinieerd aantal leveringsweken met betrekking tot een opgegeven doorlooptijd. Gegeven verkooporders Afhankelijk van de vraag zal BisTrack bestellingen aanbevelen waarbij het aanbod kleiner is dan de gewenste dekking om het verschil te dekken.
- Alleen maximum – Stelt bestellingen voor “tot” een maximale voorhanden hoeveelheid waarbij het aanbod minder is dan dit maximum.
Ten slotte kunnen gebruikers, als BisTrack de drempels voor herbestellingen kan bepalen, aanvullende voorraaddekking specificeren als buffervoorraad, doorlooptijden, hoeveel maanden historische vraag er rekening mee moet houden, en kunnen ze ook handmatig periode-voor-periode wegingsschema's definiëren om de seizoensinvloeden te benaderen. De gebruiker krijgt een lijst met voorgestelde bestellingen op basis van de gedefinieerde criteria. Een inkoper kan vervolgens met één klik op de knop inkooporders voor leveranciers genereren.
Beperkingen
Vuistregelmethoden
Hoewel BisTrack organisaties in staat stelt automatisch bestelpunten te genereren, zijn deze methoden gebaseerd op eenvoudige gemiddelden die geen rekening houden met seizoensinvloeden, trends of de volatiliteit in de vraag naar een artikel. Gemiddelden zullen altijd achterblijven bij deze patronen en zijn niet in staat trends te volgen. Overweeg een zeer seizoensgebonden product zoals een sneeuwschep. Als we een gemiddelde nemen van de vraag in de zomer/herfst wanneer we het winterseizoen naderen, in plaats van vooruit te kijken, dan zullen de aanbevelingen gebaseerd zijn op de langzamere periodes in plaats van te anticiperen op de komende vraag. Zelfs als we de geschiedenis van een heel jaar of langer in ogenschouw nemen, zullen de aanbevelingen zonder handmatige tussenkomst overcompenseren tijdens de langzamere maanden en het drukke seizoen onderschatten.
Vuistregelmethoden falen ook als ze worden gebruikt als buffer tegen de variabiliteit van vraag en aanbod. De gemiddelde vraag gedurende de doorlooptijd kan bijvoorbeeld 20 eenheden bedragen. Een planner wil echter vaak meer dan 20 eenheden op voorraad hebben om te voorkomen dat de voorraad uitvalt als de doorlooptijden langer zijn dan verwacht of de vraag hoger is dan gemiddeld. Met BisTrack kunnen gebruikers de bestelpunten specificeren op basis van veelvouden van de gemiddelden. Omdat de veelvouden echter geen rekening houden met de mate van voorspelbaarheid en variabiliteit in de vraag, zult u altijd voorspelbare artikelen overbevoorraden en onvoorspelbare artikelen te weinig hebben. Lees dit artikel voor meer informatie over waarom veelvouden van het gemiddelde falen als het gaat om het ontwikkelen van het juiste bestelpunt.
Handmatige invoer
Over de eerder genoemde seizoensinvloeden gesproken: BisTrack biedt de gebruiker de mogelijkheid om deze te benaderen door het gebruik van handmatig ingevoerde “gewichten” voor elke periode. Dit dwingt de gebruiker om voor elk item te beslissen hoe dat seizoenspatroon eruit ziet. Zelfs daarbuiten moet de gebruiker dicteren hoeveel extra weken aan voorraad hij moet meenemen om voorraadtekorten tegen te gaan. en moet specificeren rond welke doorlooptijd moet worden gepland. Is 2 weken extra aanvoer voldoende? Is 3 genoeg? Of is dat teveel? Er is geen manier om dit te weten zonder te raden, en wat logisch is voor één item is misschien niet de juiste aanpak voor alle items.
Intermittent Demand
Veel BisTrack-klanten kunnen bepaalde items als “onvoorspelbaar” beschouwen vanwege de periodieke of ‘klonterige’ aard van hun vraag. Met andere woorden, artikelen die worden gekenmerkt door een sporadische vraag, grote pieken in de vraag en periodes van weinig of helemaal geen vraag. Traditionele methoden – en vooral de vuistregels – zullen niet werken voor dit soort items. Twee extra weken aanvoer voor een zeer voorspelbaar, stabiel artikel kunnen bijvoorbeeld veel te veel zijn; voor een artikel met een zeer volatiele vraag is dezelfde regel mogelijk niet voldoende. Zonder een betrouwbare manier om deze volatiliteit voor elk item objectief te beoordelen, blijven kopers gissen wanneer ze moeten kopen en hoeveel.
Terugkeren naar spreadsheets
De realiteit is dat de meeste BisTrack-gebruikers de neiging hebben om het grootste deel van hun planning offline, in Excel, te doen. Spreadsheets zijn niet speciaal ontworpen voor prognoses en voorraadoptimalisatie. Gebruikers zullen vaak door de gebruiker gedefinieerd bakken vuistregel methoden die vaak meer kwaad dan goed doen. Eenmaal berekend, moeten gebruikers de informatie handmatig opnieuw in BisTrack invoeren. Het tijdrovende karakter van het proces brengt bedrijven ertoe zelden hun voorraadbeleid berekenen - Er gaan vele maanden en soms jaren voorbij tussen de massa-updates, wat leidt tot een reactieve aanpak van ‘instellen en vergeten’, waarbij de enige keer dat een koper/planner het voorraadbeleid beoordeelt, is op het moment van de bestelling. Wanneer beleid wordt herzien nadat het orderpunt al is geschonden, is het te laat. Wanneer het bestelpunt te hoog wordt geacht, is handmatige ondervraging vereist om de geschiedenis te bekijken, voorspellingen te berekenen, bufferposities te beoordelen en opnieuw te kalibreren. Het enorme volume aan bestellingen betekent dat kopers bestellingen gewoon vrijgeven in plaats van de tijd te nemen om alles te beoordelen, wat leidt tot een aanzienlijke overtollige voorraad. Als het bestelpunt te laag is, is het al te laat. Er kan nu een spoedactie nodig zijn, waardoor de kosten omhoog gaan, ervan uitgaande dat de klant niet zomaar ergens anders heen gaat.
Epicor is slimmer
Epicor werkt samen met Smart Software en biedt Smart IP&O aan als een platformonafhankelijke add-on voor zijn ERP-oplossingen, waaronder BisTrack, een gespecialiseerde ERP voor de hout-, hardware- en bouwmaterialenindustrie. De Smart IP&O-oplossing wordt compleet geleverd met een bidirectionele integratie met BisTrack. Hierdoor kunnen klanten van Epicor gebruik maken van speciaal voor dit doel gebouwde, beste voorraadoptimalisatietoepassingen. Met Epicor Smart IP&O kunt u prognoses genereren die trends en seizoensinvloeden vastleggen zonder handmatige configuraties. U kunt het voorraadbeleid automatisch opnieuw kalibreren met behulp van in de praktijk bewezen, geavanceerde statistische en probabilistische modellen die zijn ontworpen om nauwkeurig te plannen Intermittent demand. Veiligheidsvoorraden houden nauwkeurig rekening met variabiliteit in vraag en aanbod, zakelijke omstandigheden en prioriteiten. U kunt profiteren service level gestuurde planning zodat je net genoeg voorraad hebt of gebruik maken van optimalisatie methodes die het meest winstgevende voorraadbeleid en serviceniveaus voorschrijven, waarbij rekening wordt gehouden met de werkelijke kosten van het aanhouden van voorraad. U kunt grondstoffenaankopen ondersteunen met nauwkeurige vraagvoorspellingen over langere horizonten, en 'wat-als'-scenario's uitvoeren om alternatieve strategieën te beoordelen voordat het plan wordt uitgevoerd.
Slimme IP&O-klanten realiseren routinematig een jaarlijks rendement van zeven cijfers door verminderde snelheid, hogere verkopen en minder overtollige voorraden, terwijl ze tegelijkertijd een concurrentievoordeel verwerven door zich te onderscheiden door verbeterde klantenservice. Om een opgenomen webinar te zien, gehost door de Epicor Users Group, waarin het Demand Planning en Inventory Optimization-platform van Smart wordt geprofileerd, registreer u dan hier.