Vraagplanning kost tijd en moeite. Het is de moeite waard voor zover het je daadwerkelijk helpt te maken wat je nodig hebt wanneer je het nodig hebt.
Maar het werk kan goed of slecht worden gedaan. We zien veel fabrikanten stoppen bij het eerste niveau terwijl ze gemakkelijk naar het tweede niveau kunnen gaan. En met een beetje meer moeite zouden ze helemaal naar het derde niveau kunnen gaan, door gebruik te maken van probabilistische modellering om de resultaten van de vraagplanning om te zetten in een voorraadoptimalisatieproces.
Het eerste niveau
Het eerste niveau is het maken van een vraagprognose met behulp van statistische methoden. Afbeelding 1 toont een poging op het eerste niveau: de vraaggeschiedenis van een artikel (rode lijn) en de verwachte prognose voor 12 maanden (groene lijn).
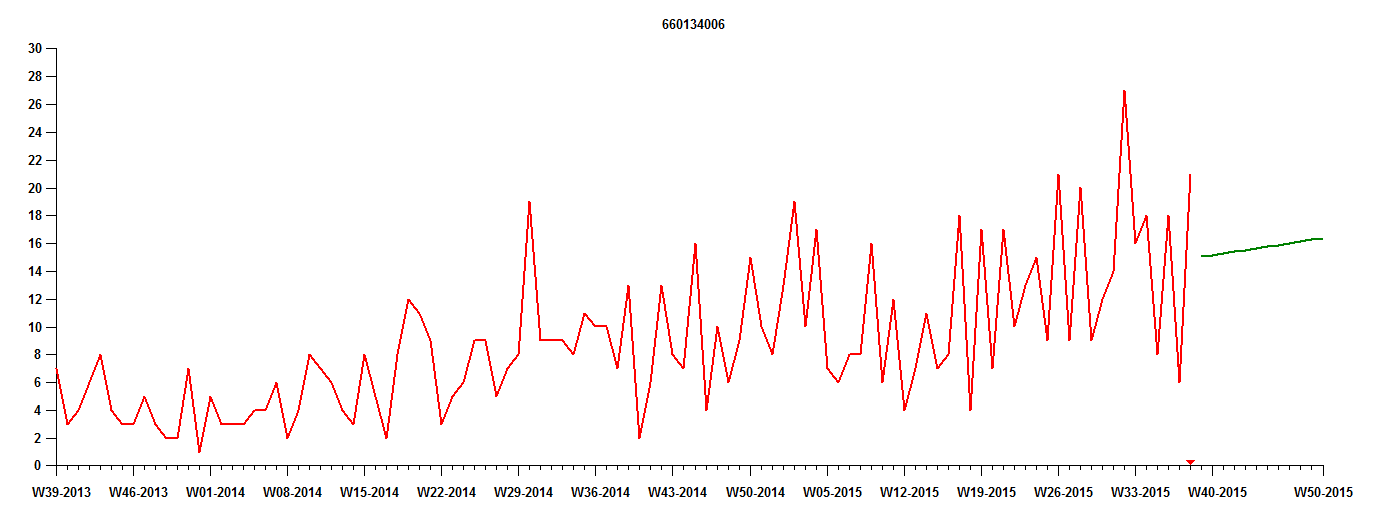
De voorspelling is kaal. Het projecteert alleen verwacht vraag negeren dat de vraag volatiel is en onvermijdelijk prognosefouten zal veroorzaken. (Dit is nog een voorbeeld van een belangrijke stelregel: “Het gemiddelde is niet het antwoord”). De voorspelling is waarschijnlijk zowel te hoog als te laag, en er is geen indicatie van voorspellingsonzekerheid bij de voorspelling. Dit betekent dat de planner geen inschatting heeft van het risico dat gepaard gaat met het nakomen van de prognose. Toch biedt deze prognose een rationele basis voor productieplanning, persoonlijke planning en inkoop van grondstoffen. Het is dus veel beter dan gissen.
Het tweede niveau
Het tweede niveau houdt expliciet rekening met de voorspelde onzekerheid. Figuur 2 toont een inspanning van het tweede niveau, bekend als een "percentielprognose".
Nu zien we een expliciete indicatie van voorspelde onzekerheid. De cyaankleurige lijn boven de groene prognoselijn vertegenwoordigt het verwachte 90e percentiel van de maandelijkse vraag. Dat wil zeggen, de vraag in elke toekomstige maand heeft een kans van 90% om op of onder de cyaanlijn te vallen. Anders gezegd, er is een kans van 10% dat de vraag elke maand de cyaanlijn overschrijdt.
Deze analyse is veel nuttiger omdat het risicobeheer ondersteunt. Als het belangrijk is om voldoende aanvoer van dit artikel te verzekeren, dan is het logisch om te produceren tot het 90e percentiel in plaats van tot de verwachte prognose. Het is tenslotte een gok of de verwachte voorspelling zal resulteren in voldoende productie om aan de maandelijkse vraag te voldoen. Deze prognose op het tweede niveau is in feite een ruwe vervanging van een zorgvuldig voorraadbeheerproces.
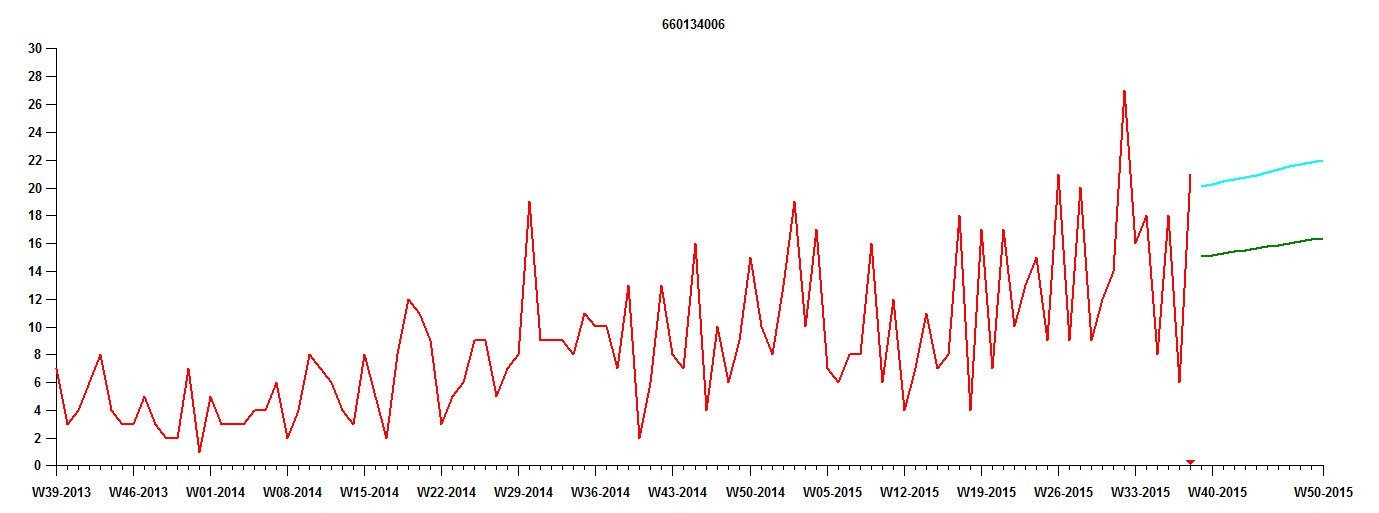
Afbeelding 2. Een percentielprognose, waarbij de cyaankleurige lijn het 90e percentiel van de maandelijkse vraag schat.
Gaat helemaal naar het derde niveau
Best practice is het derde niveau, dat vraagplanning gebruikt als basis voor het voltooien van een tweede taak: expliciete voorraadoptimalisatie. Figuur 3 toont de fundamentele plot voor het efficiënte beheer van ons eindproduct, ervan uitgaande dat het een productietijd van 1 maand heeft.
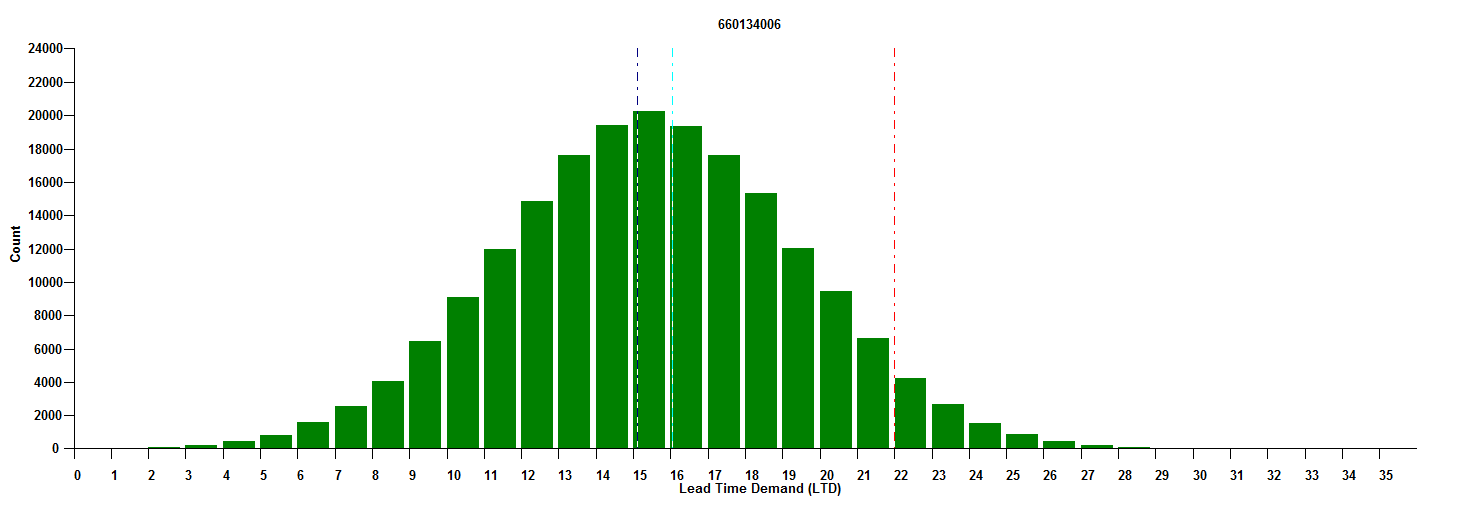
Afbeelding 3 toont het gebruik van probabilistische prognoses en hoeveel afname van de voorraad gereed product kan plaatsvinden gedurende een productietijd van een maand. De onzekerheid in de vraag komt tot uiting in de spreiding van de mogelijke vraag, van een dieptepunt van 0 tot een maximum van 35, waarbij 15 eenheden de meest waarschijnlijke waarde is. De verticale rode lijn bij 22 geeft het "bestelpunt" (of "min" of "triggerwaarde") aan dat overeenkomt met het behouden van de kans op voorraad in afwachting van aanvulling tot een lage 5%. Wanneer de voorraad daalt tot 22 of lager, is het tijd om meer te bestellen. Het derde niveau maakt gebruik van probabilistische vraagprognoses met volledige blootstelling aan prognoseonzekerheid om de voorraad van het eindproduct efficiënt te beheren.
Opsommen
Het voorspellen van de meest waarschijnlijke vraag naar een artikel is een nuttige eerste stap. Het brengt je halverwege waar je wilt zijn. Maar het biedt een onvolledige gids voor planning, omdat het de volatiliteit van de vraag en de verwachte onzekerheid die het creëert, negeert. Door een buffer aan de vraagprognose toe te voegen, komt u verder, omdat het risico wordt verkleind dat een sprong in de vraag u een tekort aan product zal opleveren. Dit kussen kan worden berekend door middel van probabilistische prognosebenaderingen die een hoog percentage van de verdeling van de toekomstige vraag voorspellen. En als u nog een stap verder wilt gaan, kunt u prognoses van de vraagverdeling over een doorlooptijd invoeren om bestelpunten (minuten) te berekenen om ervoor te zorgen dat u een acceptabel laag risico op voorraaduitval heeft.
Gezien wat moderne prognosetechnologie voor u kan doen, waarom zou u halverwege uw doel willen stoppen?

gerelateerde berichten

Maak van AI-gestuurde voorraadoptimalisatie een bondgenoot voor uw organisatie
In deze blog onderzoeken we hoe organisaties uitzonderlijke efficiëntie en nauwkeurigheid kunnen bereiken met AI-gestuurde voorraadoptimalisatie. Traditionele methoden voor voorraadbeheer schieten vaak tekort vanwege hun reactieve karakter en hun afhankelijkheid van handmatige processen. Het handhaven van optimale voorraadniveaus is van fundamenteel belang om aan de vraag van de klant te voldoen en tegelijkertijd de kosten te minimaliseren. De introductie van AI-gestuurde voorraadoptimalisatie kan de last van handmatige processen aanzienlijk verminderen, waardoor supply chain-managers worden ontlast van vervelende taken.
Dagelijkse vraagscenario's
In deze videoblog leggen we uit hoe tijdreeksvoorspellingen naar voren zijn gekomen als een cruciaal hulpmiddel, vooral op dagelijks niveau, waarmee Smart Software sinds de oprichting ruim veertig jaar geleden pionierde. De evolutie van bedrijfspraktijken van jaarlijkse naar meer verfijnde temporele stappen zoals maandelijkse en nu dagelijkse data-analyse illustreert een significante verschuiving in operationele strategieën.

Constructief spelen met Digital Twins
Degenen onder u die actuele onderwerpen volgen, zullen bekend zijn met de term ‘digitale tweeling’. Degenen die het te druk hebben gehad met hun werk, willen misschien verder lezen en bijpraten. Hoewel er verschillende definities van een digitale tweeling bestaan, is er één die goed werkt: een digitale tweeling is een dynamische virtuele kopie van een fysiek bezit, proces, systeem of omgeving die er hetzelfde uitziet en zich hetzelfde gedraagt als zijn tegenhanger in de echte wereld. Een digitale tweeling neemt gegevens op en repliceert processen, zodat u mogelijke prestatieresultaten en problemen kunt voorspellen die het echte product kan ondergaan.
recente berichten
 Het beheren van de voorraad reserveonderdelen: beste praktijkenIn this blog, we’ll explore several effective strategies for managing spare parts inventory, emphasizing the importance of optimizing stock levels, maintaining service levels, and using smart tools to aid in decision-making. Managing spare parts inventory is a critical component for businesses that depend on equipment uptime and service reliability. Unlike regular inventory items, spare parts often have unpredictable demand patterns, making them more challenging to manage effectively. An efficient spare parts inventory management system helps prevent stockouts that can lead to operational downtime and costly delays while also avoiding overstocking that unnecessarily ties up capital and increases holding costs. […]
Het beheren van de voorraad reserveonderdelen: beste praktijkenIn this blog, we’ll explore several effective strategies for managing spare parts inventory, emphasizing the importance of optimizing stock levels, maintaining service levels, and using smart tools to aid in decision-making. Managing spare parts inventory is a critical component for businesses that depend on equipment uptime and service reliability. Unlike regular inventory items, spare parts often have unpredictable demand patterns, making them more challenging to manage effectively. An efficient spare parts inventory management system helps prevent stockouts that can lead to operational downtime and costly delays while also avoiding overstocking that unnecessarily ties up capital and increases holding costs. […] 5 manieren om de snelheid van beslissingen in de toeleveringsketen te verbeterenDe belofte van een digitale supply chain heeft de manier waarop bedrijven opereren getransformeerd. In de kern kan het snelle, datagestuurde beslissingen nemen en tegelijkertijd kwaliteit en efficiëntie in de hele bedrijfsvoering garanderen. Het gaat echter niet alleen om toegang tot meer data. Organisaties hebben de juiste tools en platforms nodig om die data om te zetten in bruikbare inzichten. Dit is waar besluitvorming cruciaal wordt, vooral in een landschap waar nieuwe digitale supply chain-oplossingen en AI-gestuurde platforms u kunnen ondersteunen bij het stroomlijnen van veel processen binnen de beslissingsmatrix. […]
5 manieren om de snelheid van beslissingen in de toeleveringsketen te verbeterenDe belofte van een digitale supply chain heeft de manier waarop bedrijven opereren getransformeerd. In de kern kan het snelle, datagestuurde beslissingen nemen en tegelijkertijd kwaliteit en efficiëntie in de hele bedrijfsvoering garanderen. Het gaat echter niet alleen om toegang tot meer data. Organisaties hebben de juiste tools en platforms nodig om die data om te zetten in bruikbare inzichten. Dit is waar besluitvorming cruciaal wordt, vooral in een landschap waar nieuwe digitale supply chain-oplossingen en AI-gestuurde platforms u kunnen ondersteunen bij het stroomlijnen van veel processen binnen de beslissingsmatrix. […] 12 Oorzaken van Overstocking en Praktische OplossingenEffectief voorraadbeheer is cruciaal voor het behouden van een gezonde balans en het verzekeren dat middelen optimaal worden toegewezen. Hier is een diepgaande verkenning van de belangrijkste oorzaken van overstocking, hun implicaties en mogelijke oplossingen. […]
12 Oorzaken van Overstocking en Praktische OplossingenEffectief voorraadbeheer is cruciaal voor het behouden van een gezonde balans en het verzekeren dat middelen optimaal worden toegewezen. Hier is een diepgaande verkenning van de belangrijkste oorzaken van overstocking, hun implicaties en mogelijke oplossingen. […] FAQ: Slimme IP&O voor beter voorraadbeheer.Effectief supply chain- en voorraadbeheer zijn essentieel voor het bereiken van operationele efficiëntie en klanttevredenheid. Deze blog biedt duidelijke en beknopte antwoorden op enkele basisvragen en andere veelvoorkomende vragen van onze Smart IP&O-klanten, en biedt praktische inzichten om typische uitdagingen te overwinnen en uw voorraadbeheerpraktijken te verbeteren. Met de focus op deze belangrijke gebieden helpen we u complexe voorraadproblemen om te zetten in strategische, beheersbare acties die kosten verlagen en de algehele prestaties verbeteren met Smart IP&O. […]
FAQ: Slimme IP&O voor beter voorraadbeheer.Effectief supply chain- en voorraadbeheer zijn essentieel voor het bereiken van operationele efficiëntie en klanttevredenheid. Deze blog biedt duidelijke en beknopte antwoorden op enkele basisvragen en andere veelvoorkomende vragen van onze Smart IP&O-klanten, en biedt praktische inzichten om typische uitdagingen te overwinnen en uw voorraadbeheerpraktijken te verbeteren. Met de focus op deze belangrijke gebieden helpen we u complexe voorraadproblemen om te zetten in strategische, beheersbare acties die kosten verlagen en de algehele prestaties verbeteren met Smart IP&O. […] 7 belangrijke trends in vraagplanning die de toekomst vormgevenVraagplanning gaat verder dan alleen het voorspellen van productbehoeften; het gaat erom ervoor te zorgen dat uw bedrijf nauwkeurig, efficiënt en kosteneffectief aan de vraag van klanten voldoet. De nieuwste technologie voor vraagplanning pakt belangrijke uitdagingen aan, zoals nauwkeurigheid van voorspellingen, voorraadbeheer en marktresponsiviteit. In deze blog introduceren we kritieke trends voor vraagplanning, waaronder datagestuurde inzichten, probabilistische voorspellingen, consensusplanning, voorspellende analyses, scenariomodellering, realtime zichtbaarheid en multilevel voorspellingen. Deze trends helpen u om voorop te blijven lopen, uw toeleveringsketen te optimaliseren, kosten te verlagen en de klanttevredenheid te verbeteren, waardoor uw bedrijf op de lange termijn succesvol wordt. […]
7 belangrijke trends in vraagplanning die de toekomst vormgevenVraagplanning gaat verder dan alleen het voorspellen van productbehoeften; het gaat erom ervoor te zorgen dat uw bedrijf nauwkeurig, efficiënt en kosteneffectief aan de vraag van klanten voldoet. De nieuwste technologie voor vraagplanning pakt belangrijke uitdagingen aan, zoals nauwkeurigheid van voorspellingen, voorraadbeheer en marktresponsiviteit. In deze blog introduceren we kritieke trends voor vraagplanning, waaronder datagestuurde inzichten, probabilistische voorspellingen, consensusplanning, voorspellende analyses, scenariomodellering, realtime zichtbaarheid en multilevel voorspellingen. Deze trends helpen u om voorop te blijven lopen, uw toeleveringsketen te optimaliseren, kosten te verlagen en de klanttevredenheid te verbeteren, waardoor uw bedrijf op de lange termijn succesvol wordt. […]

Voorraadoptimalisatie voor fabrikanten, distributeurs en MRO
- Het beheren van de voorraad reserveonderdelen: beste praktijkenIn this blog, we’ll explore several effective strategies for managing spare parts inventory, emphasizing the importance of optimizing stock levels, maintaining service levels, and using smart tools to aid in decision-making. Managing spare parts inventory is a critical component for businesses that depend on equipment uptime and service reliability. Unlike regular inventory items, spare parts often have unpredictable demand patterns, making them more challenging to manage effectively. An efficient spare parts inventory management system helps prevent stockouts that can lead to operational downtime and costly delays while also avoiding overstocking that unnecessarily ties up capital and increases holding costs. […]
 Innovatie van de OEM-aftermarket met AI-gestuurde voorraadoptimalisatieDe aftermarketsector biedt OEM's een beslissend voordeel door een stabiele inkomstenstroom te bieden en de loyaliteit van klanten te bevorderen door de betrouwbare en tijdige levering van serviceonderdelen. Het beheren van inventaris en het voorspellen van de vraag in de aftermarket gaat echter gepaard met uitdagingen, waaronder onvoorspelbare vraagpatronen, enorme productassortimenten en de noodzaak van snelle doorlooptijden. Traditionele methoden schieten vaak tekort vanwege de complexiteit en variabiliteit van de vraag in de aftermarket. De nieuwste technologieën kunnen grote datasets analyseren om de toekomstige vraag nauwkeuriger te voorspellen en voorraadniveaus te optimaliseren, wat leidt tot betere service en lagere kosten. […]
Innovatie van de OEM-aftermarket met AI-gestuurde voorraadoptimalisatieDe aftermarketsector biedt OEM's een beslissend voordeel door een stabiele inkomstenstroom te bieden en de loyaliteit van klanten te bevorderen door de betrouwbare en tijdige levering van serviceonderdelen. Het beheren van inventaris en het voorspellen van de vraag in de aftermarket gaat echter gepaard met uitdagingen, waaronder onvoorspelbare vraagpatronen, enorme productassortimenten en de noodzaak van snelle doorlooptijden. Traditionele methoden schieten vaak tekort vanwege de complexiteit en variabiliteit van de vraag in de aftermarket. De nieuwste technologieën kunnen grote datasets analyseren om de toekomstige vraag nauwkeuriger te voorspellen en voorraadniveaus te optimaliseren, wat leidt tot betere service en lagere kosten. […] Toekomstbestendige hulpprogramma's: geavanceerde analyses voor optimalisatie van de supply chainNutsvoorzieningen op het gebied van elektriciteit, aardgas, stedelijk water en telecommunicatie zijn allemaal activa-intensief en afhankelijk van fysieke infrastructuur die in de loop van de tijd goed moet worden onderhouden, bijgewerkt en geüpgraded. Het maximaliseren van de uptime van bedrijfsmiddelen en de betrouwbaarheid van de fysieke infrastructuur vereist effectief voorraadbeheer, prognoses van reserveonderdelen en leveranciersbeheer. Een nutsbedrijf dat deze processen effectief uitvoert, presteert beter dan zijn concurrenten, levert een beter rendement op voor zijn investeerders en hogere serviceniveaus voor zijn klanten, terwijl het zijn impact op het milieu vermindert. […]
Toekomstbestendige hulpprogramma's: geavanceerde analyses voor optimalisatie van de supply chainNutsvoorzieningen op het gebied van elektriciteit, aardgas, stedelijk water en telecommunicatie zijn allemaal activa-intensief en afhankelijk van fysieke infrastructuur die in de loop van de tijd goed moet worden onderhouden, bijgewerkt en geüpgraded. Het maximaliseren van de uptime van bedrijfsmiddelen en de betrouwbaarheid van de fysieke infrastructuur vereist effectief voorraadbeheer, prognoses van reserveonderdelen en leveranciersbeheer. Een nutsbedrijf dat deze processen effectief uitvoert, presteert beter dan zijn concurrenten, levert een beter rendement op voor zijn investeerders en hogere serviceniveaus voor zijn klanten, terwijl het zijn impact op het milieu vermindert. […] Centreringswet: timing, prijzen en betrouwbaarheid van reserveonderdelenIn dit artikel begeleiden we u bij het opstellen van een voorraadplan voor reserveonderdelen, waarbij prioriteit wordt gegeven aan beschikbaarheidsstatistieken zoals serviceniveaus en vulpercentages, terwijl de kostenefficiëntie wordt gewaarborgd. We zullen ons concentreren op een benadering van voorraadplanning genaamd Service Level-Driven Inventory Optimization. Vervolgens bespreken we hoe u kunt bepalen welke onderdelen u in uw inventaris moet opnemen en welke onderdelen mogelijk niet nodig zijn. Ten slotte onderzoeken we manieren om uw op serviceniveau gebaseerde voorraadplan consistent te verbeteren. […]
Centreringswet: timing, prijzen en betrouwbaarheid van reserveonderdelenIn dit artikel begeleiden we u bij het opstellen van een voorraadplan voor reserveonderdelen, waarbij prioriteit wordt gegeven aan beschikbaarheidsstatistieken zoals serviceniveaus en vulpercentages, terwijl de kostenefficiëntie wordt gewaarborgd. We zullen ons concentreren op een benadering van voorraadplanning genaamd Service Level-Driven Inventory Optimization. Vervolgens bespreken we hoe u kunt bepalen welke onderdelen u in uw inventaris moet opnemen en welke onderdelen mogelijk niet nodig zijn. Ten slotte onderzoeken we manieren om uw op serviceniveau gebaseerde voorraadplan consistent te verbeteren. […]
