Wij geloven dat de ontwikkeling van digitale tweelingen van voorraadsystemen de leidende factor is op het gebied van supply chain-analyse. Deze tweelingen nemen de vorm aan van discrete gebeurtenismodellen die Monte Carlo-simulatie gebruiken om het volledige scala aan operationele risico's te genereren en te optimaliseren. We beweren ook dat wij en onze collega's bij Smart Software een grote rol hebben gespeeld bij het smeden van die voorsprong. Maar we zijn niet de enigen: er zijn een klein aantal andere softwarebedrijven over de hele wereld die bezig zijn met een inhaalslag.
Wat is de volgende stap op het gebied van supply chain-analyse? Waar ligt de volgende grens? Het kan gaan om een soort neuraal netwerkmodel van een distributiesysteem. Maar we zouden betere kansen hebben op een uitbreiding van onze toonaangevende modellen van voorraadsystemen met één echelon naar voorraadsystemen met meerdere echelons.
Figuren 1 en 2 illustreren het onderscheid tussen systemen met één en meerdere echelons. Figuur 1 toont een fabrikant die afhankelijk is van een bron om zijn voorraad reserveonderdelen of componenten aan te vullen. Wanneer er voorraadtekorten dreigen, bestelt de fabrikant aanvullingsvoorraden bij de Bron.
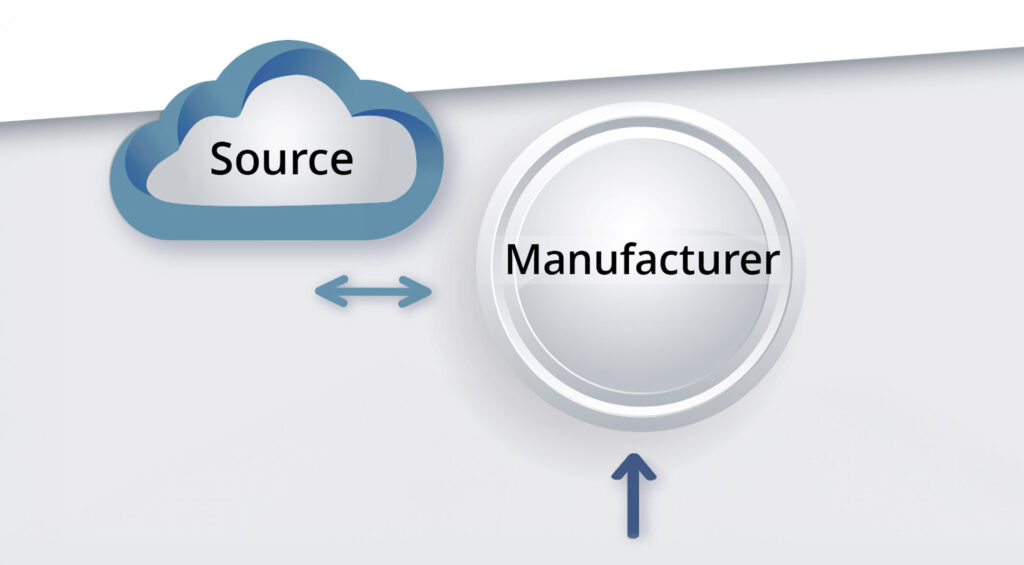
Figuur 1: Een inventarisatiesysteem met één echelon
Single-echelon-modellen bevatten niet expliciet details van de Bron. Het blijft mysterieus, een onzichtbare geest wiens enige relevante kenmerk de willekeurige tijd is die nodig is om te reageren op een aanvullingsverzoek. Belangrijk is dat er impliciet van wordt uitgegaan dat de Bron zelf nooit een voorraad opslaat. Die veronderstelling kan voor veel doeleinden ‘goed genoeg’ zijn, maar kan niet letterlijk waar zijn. Dit wordt afgehandeld door stockout-gebeurtenissen van leveranciers in de distributie van de doorlooptijd van de aanvullingen te verwerken. Het terugdringen van die veronderstelling is de reden voor multi-echelon-modellering.
Figuur 2 toont een eenvoudig inventarisatiesysteem met twee niveaus. Het verschuift domeinen van productie naar distributie. Er zijn meerdere magazijnen (WH's) afhankelijk van een distributiecentrum (DC) voor bevoorrading. Nu is de DC een expliciet onderdeel van het model. Het heeft een beperkte capaciteit om bestellingen te verwerken en vereist zijn eigen herschikkingsprotocollen. De DC krijgt zijn aanvulling van hogerop in de keten van een bron. De Bron kan de fabrikant van het inventarisitem zijn of misschien een “regionale DC” of iets dergelijks, maar – raad eens? – het is een andere geest. Net als in het single-echelonmodel heeft deze geest één zichtbaar kenmerk: de waarschijnlijkheidsverdeling van de doorlooptijd van de aanvulling. (De clou van een beroemde grap uit de natuurkunde is: “Maar mevrouw, het zijn schildpadden helemaal naar beneden.” In ons geval: “Het zijn geesten helemaal naar boven.”)
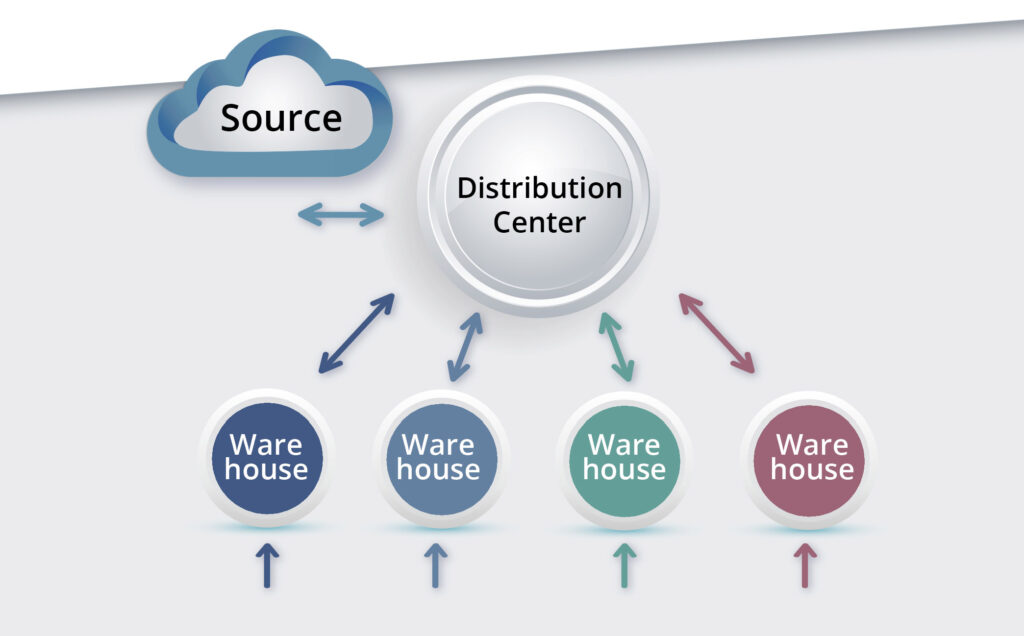
Figuur 2: Een inventarisatiesysteem met twee niveaus
Het probleem van procesontwerp en -optimalisatie is veel moeilijker op twee niveaus. De moeilijkheid is niet alleen de toevoeging van nog twee controleparameters voor elke WH (bijvoorbeeld een Min en een Max voor elk) plus dezelfde twee parameters voor de DC. Het lastigste deel is het modelleren van de interactie tussen de WH's. In het model met één niveau opereert elke WH in zijn eigen kleine wereld en hoort hij nooit "Sorry, we hebben geen voorraad meer" van de spookachtige Bron. Maar in een systeem met twee niveaus zijn er meerdere WH's die allemaal strijden om bevoorrading vanuit hun gedeelde DC. Deze concurrentie creëert de belangrijkste analytische moeilijkheid: de WH's kunnen niet afzonderlijk worden gemodelleerd, maar moeten tegelijkertijd worden geanalyseerd. Als één DC bijvoorbeeld tien WH's bedient, zijn er 2+10×2 = 22 voorraadbeheerparameters waarvan de waarden moeten worden berekend. In nerdtaal: het is niet triviaal om een beperkt, discreet optimalisatieprobleem met 22 variabelen en een stochastische objectieve functie op te lossen.
Als we het verkeerde systeemontwerp kiezen, ontdekken we een nieuw fenomeen dat inherent is aan systemen met meerdere niveaus, dat we informeel ‘meltdown’ of ‘catastrofe’ noemen. Bij dit fenomeen kan het DC de bevoorradingsbehoefte van de WH's niet bijhouden, waardoor er uiteindelijk voorraadtekorten op magazijnniveau ontstaan. Vervolgens putten de steeds hectischer wordende aanvullingsverzoeken van de WH de voorraad bij het DC uit, waardoor zijn eigen paniekerige verzoeken om aanvulling vanuit het regionale DC beginnen. Als het regionale DC er te lang over doet om het DC weer aan te vullen, dan ontaardt het hele systeem in een tragedie van uitputting.
Eén oplossing voor het meltdown-probleem is om het DC zo te ontwerpen dat het bijna nooit leeg raakt, maar dat kan erg duur zijn. Daarom is er in de eerste plaats een regionaal DC. Elk betaalbaar systeemontwerp heeft dus een DC die net goed genoeg is om lang mee te gaan tussen meltdowns. Dit perspectief impliceert een nieuw type Key Performance Indicator (KPI), zoals “De kans op een meltdown binnen X jaar is minder dan Y procent.”
De volgende grens zal nieuwe methoden en nieuwe maatstaven vereisen, maar zal een nieuwe manier bieden om distributiesystemen te ontwerpen en te optimaliseren. Onze skunkfabriek genereert al prototypes. Bekijk deze ruimte.