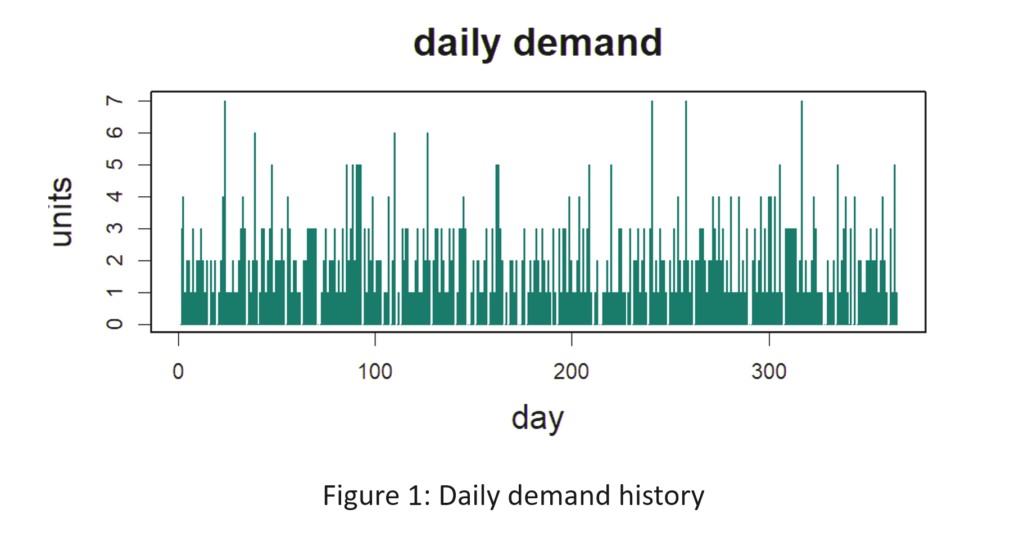
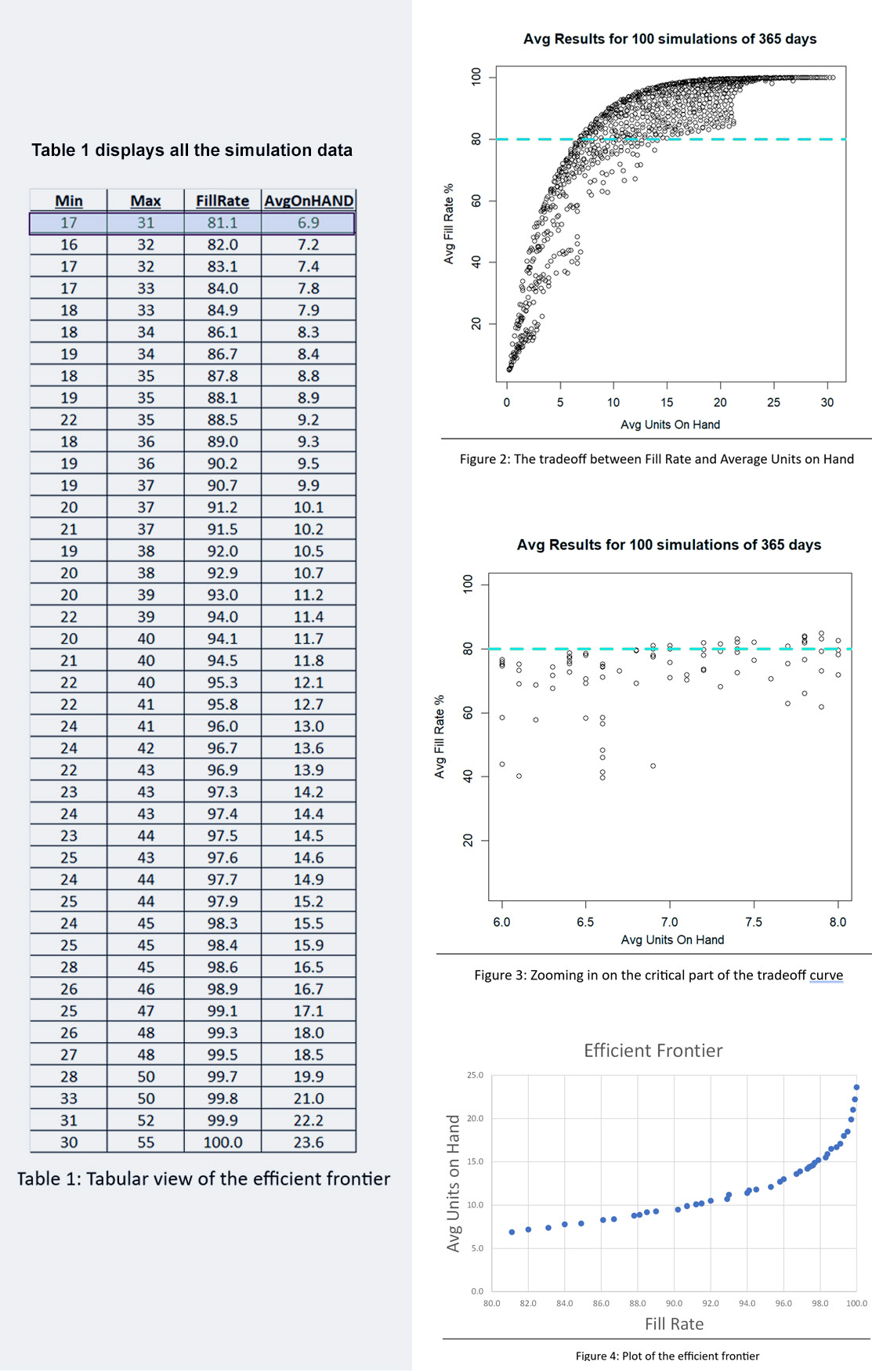
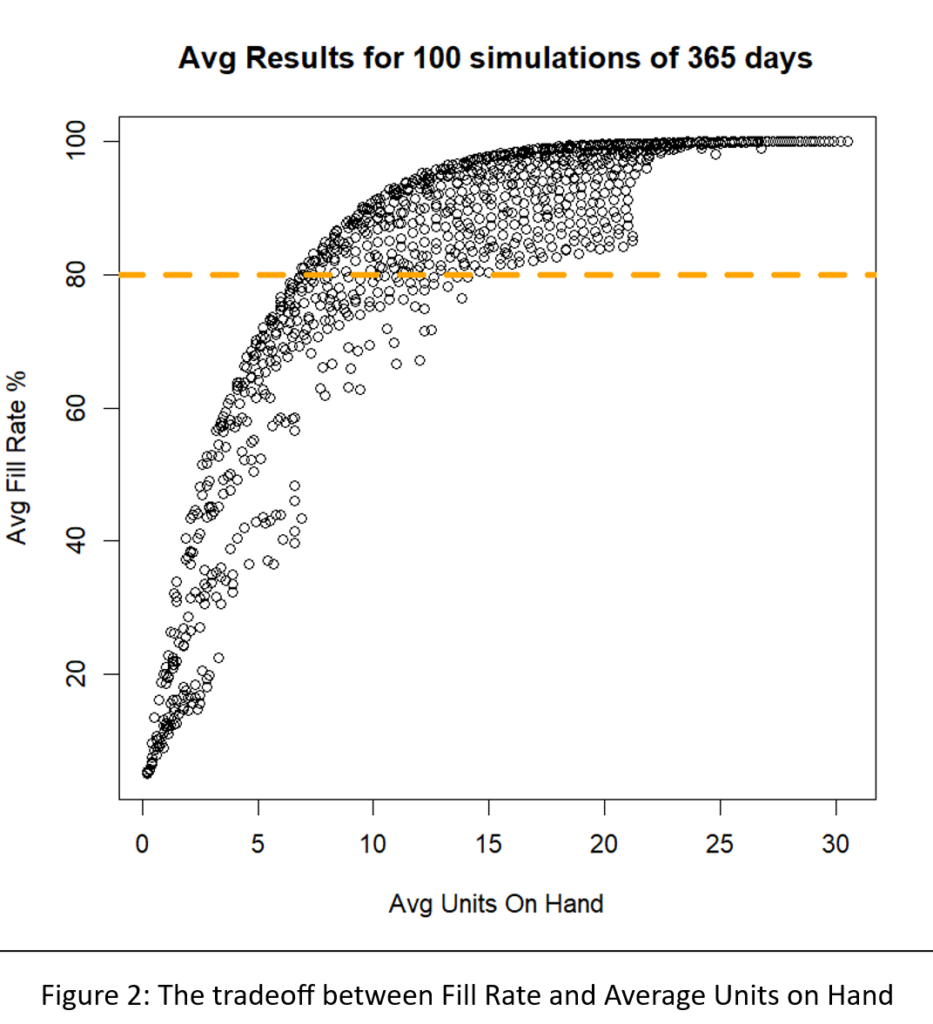
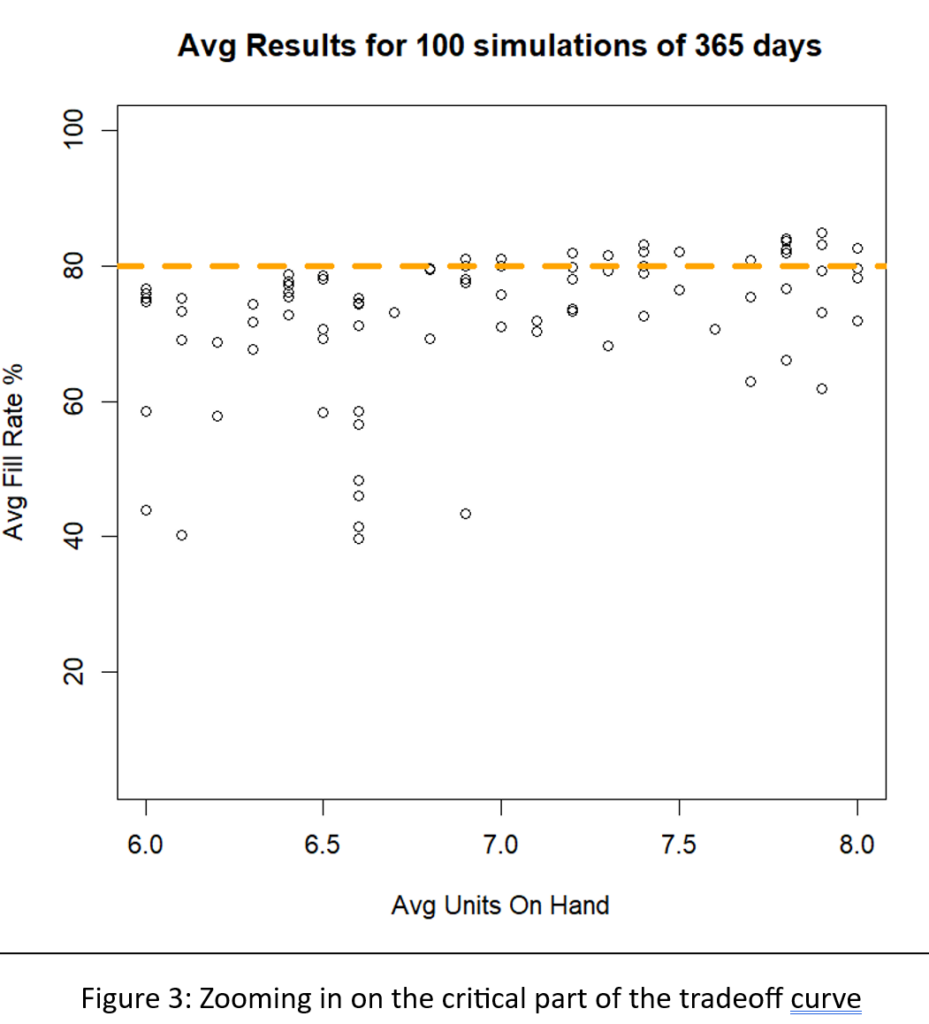
In deze blog onderzoeken we hoe organisaties uitzonderlijke efficiëntie en nauwkeurigheid kunnen bereiken met AI-gestuurde voorraadoptimalisatie. Traditionele methoden voor voorraadbeheer schieten vaak tekort vanwege hun reactieve karakter en hun afhankelijkheid van handmatige processen. Het handhaven van optimale voorraadniveaus is van fundamenteel belang om aan de vraag van de klant te voldoen en tegelijkertijd de kosten te minimaliseren. De introductie van AI-gestuurde voorraadoptimalisatie kan de last van handmatige processen aanzienlijk verminderen, waardoor supply chain-managers worden ontlast van vervelende taken. Met AI kunnen we de vraag nauwkeuriger voorspellen, overtollige voorraden verminderen, voorraadtekorten voorkomen en uiteindelijk de bedrijfsresultaten van onze organisatie verbeteren. Laten we eens kijken hoe deze aanpak niet alleen de verkoop- en operationele efficiëntie verhoogt, maar ook de klanttevredenheid verhoogt door ervoor te zorgen dat producten altijd beschikbaar zijn wanneer dat nodig is.
Inzichten voor verbeterde besluitvorming in voorraadbeheer
- Verbeterde voorspellingsnauwkeurigheid Geavanceerde Machine Learning-algoritmen analyseren historische gegevens om patronen te identificeren die mensen mogelijk over het hoofd zien. Technieken als clustering, detectie van regimeveranderingen, detectie van afwijkingen en regressieanalyse bieden diepgaande inzichten in gegevens. Het meten van voorspellingsfouten is essentieel voor het verfijnen van voorspellingsmodellen; Technieken als Mean Absolute Error (MAE) en Root Mean Squared Error (RMSE) helpen bijvoorbeeld bij het kwantificeren van de nauwkeurigheid van voorspellingen. Bedrijven kunnen de nauwkeurigheid verbeteren door voortdurend prognoses te monitoren en aan te passen op basis van deze foutstatistieken. Zoals de Demand Planner bij een Hardware Retailer vermeld, “Met de verbeteringen aan onze prognoses en voorraadplanning die Smart Software mogelijk maakte, hebben we de veiligheidsvoorraad met 20% kunnen verminderen en tegelijkertijd de voorraadtekorten met 35% kunnen verminderen.”
- Realtime gegevensanalyse State-of-the-art systemen kunnen enorme hoeveelheden gegevens in realtime verwerken, waardoor bedrijven hun voorraadniveaus dynamisch kunnen aanpassen op basis van de huidige vraagtrends en marktomstandigheden. Afwijkingsdetectiealgoritmen kunnen plotselinge pieken of dalen in de vraag automatisch identificeren en corrigeren, zodat de voorspellingen accuraat blijven. Een opmerkelijk succesverhaal komt van Smart IP&O, waarmee een bedrijf de voorraad tegen 20% kon verminderen en tegelijkertijd de serviceniveaus kon handhaven door voortdurend realtime gegevens te analyseren en de prognoses dienovereenkomstig aan te passen. FedEx Tech's Manager Materials benadrukt, “Wat het verzoek ook is, we moeten aan onze serviceverplichtingen de volgende dag voldoen. Smart stelt ons in staat om onze voorraad aan te passen om er zeker van te zijn dat we de producten en onderdelen bij de hand hebben om de serviceniveaus te bereiken die onze klanten nodig hebben.”
- Verbeterde supply chain-efficiëntie Intelligente technologieplatforms kunnen de gehele supply chain optimaliseren, van inkoop tot distributie, door doorlooptijden te voorspellen en orderhoeveelheden te optimaliseren. Dit verkleint het risico op over- en onderbezetting. Met behulp van op prognoses gebaseerd voorraadbeheer heeft Smart Software bijvoorbeeld een fabrikant geholpen zijn toeleveringsketen te stroomlijnen, de doorlooptijden met 15% te verkorten en de algehele efficiëntie te verbeteren. De VP Operations bij Procon Pump verklaarde: “Een van de dingen die ik leuk vind aan deze nieuwe tool... is dat ik de gevolgen van beslissingen over voorraadvoorraden kan evalueren voordat ik ze implementeer.”
- Verbeterde besluitvorming AI biedt bruikbare inzichten en aanbevelingen, waardoor managers weloverwogen beslissingen kunnen nemen. Dit omvat het identificeren van langzaam bewegende artikelen, het voorspellen van de toekomstige vraag en het optimaliseren van de voorraadniveaus. Regressieanalyse kan bijvoorbeeld de verkoop relateren aan externe variabelen zoals seizoensinvloeden of economische indicatoren, waardoor een dieper inzicht ontstaat in de vraagfactoren. Een van de klanten van Smart Software rapporteerde een aanzienlijke verbetering in de besluitvormingsprocessen, wat resulteerde in een stijging van het serviceniveau met 30% en een vermindering van de overtollige voorraad met 15%. “Smart IP&O stelde ons in staat de vraag op elke opslaglocatie te modelleren en, met behulp van serviceniveaugestuurde planning, te bepalen hoeveel we op voorraad moesten hebben om het serviceniveau te bereiken dat we nodig hebben”, aldus de Inkoopmanager bij Seneca Companies.
- Kostenbesparing Door de voorraadniveaus te optimaliseren kunnen bedrijven de opslagkosten verlagen en verliezen als gevolg van verouderde of verlopen producten minimaliseren. AI-gestuurde systemen verminderen ook de noodzaak van handmatige voorraadcontroles, waardoor tijd en arbeidskosten worden bespaard. Dat blijkt uit een recente casestudy hoe de implementatie van Inventory Planning & Optimization (IP&O) binnen 90 dagen na de start van het project werd gerealiseerd. In de daaropvolgende zes maanden maakte IP&O het mogelijk de voorraadparameters voor enkele duizenden artikelen aan te passen, wat resulteerde in een voorraadreductie van $9,0 miljoen, terwijl het beoogde serviceniveau behouden bleef.
Door gebruik te maken van geavanceerde algoritmen en realtime data-analyse kunnen bedrijven optimale voorraadniveaus handhaven en de algehele prestaties van hun supply chain verbeteren. Inventory Planning & Optimization (IP&O) is een krachtig hulpmiddel dat uw organisatie kan helpen deze doelen te bereiken. Het integreren van de modernste voorraadoptimalisatie in uw organisatie kan leiden tot aanzienlijke verbeteringen op het gebied van efficiëntie, kostenreductie en klanttevredenheid.