Gegevensverificatie en -validatie zijn essentieel voor het succes van de implementatie van software die statistische analyse van gegevens uitvoert, zoals Smart IP&O. Dit artikel beschrijft het probleem en dient als een praktische gids om het werk goed te doen, vooral voor de gebruiker van de nieuwe applicatie.
Hoe minder ervaring uw organisatie heeft met het valideren van historische transacties of artikelstamkenmerken, hoe waarschijnlijker het is dat er problemen of fouten zijn opgetreden bij het invoeren van gegevens in het ERP die tot nu toe onopgemerkt zijn gebleven. De 'garbage in, garbage out'-regel betekent dat u prioriteit moet geven aan deze stap van het software-onboardingproces, anders loopt u het risico vertraging op te lopen en mogelijk geen ROI te genereren.
De beste persoon om te bevestigen dat gegevens in uw ERP correct zijn ingevoerd, is uiteindelijk de persoon die de business kent en bijvoorbeeld kan beweren “dit onderdeel behoort niet tot die productgroep”. Dat is meestal dezelfde persoon die Smart opent en gebruikt. Maar ook een databasebeheerder of IT-support kan een sleutelrol spelen door te kunnen zeggen: “Dit onderdeel is afgelopen december door Jane Smith aan die productgroep toegewezen.” Ervoor zorgen dat gegevens correct zijn, is misschien geen vast onderdeel van uw dagelijkse werk, maar kan worden opgesplitst in beheersbare kleine taken waarvoor een goede projectmanager tijd en middelen zal uittrekken.
De softwareleverancier voor vraagplanning die de gegevens ontvangt, speelt ook een rol. Ze zullen bevestigen dat de onbewerkte gegevens zonder problemen zijn opgenomen. De leverancier kan ook afwijkingen in de onbewerkte gegevensbestanden identificeren die wijzen op de noodzaak van validatie. Maar vertrouwen op de softwareleverancier om u gerust te stellen dat de gegevens er goed uitzien, is niet genoeg. U wilt na de livegang niet ontdekken dat u de output niet kunt vertrouwen omdat sommige gegevens "niet kloppen".
Elke stap in de gegevensstroom heeft verificatie en validatie nodig. Verificatie betekent dat de gegevens in de ene stap nog steeds hetzelfde zijn nadat ze naar de volgende stap zijn gegaan. Validatie betekent dat de gegevens correct en bruikbaar zijn voor analyse.
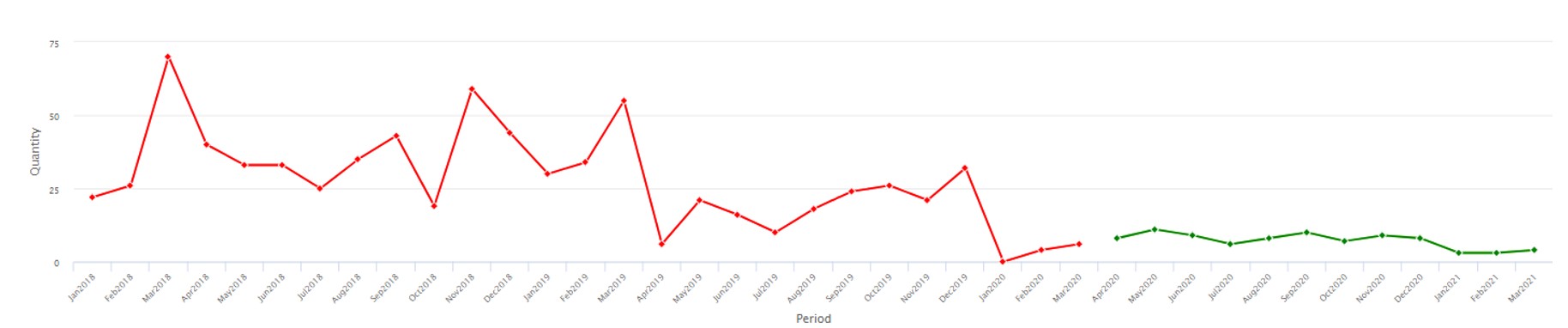
De meest voorkomende gegevensstroom ziet er als volgt uit:
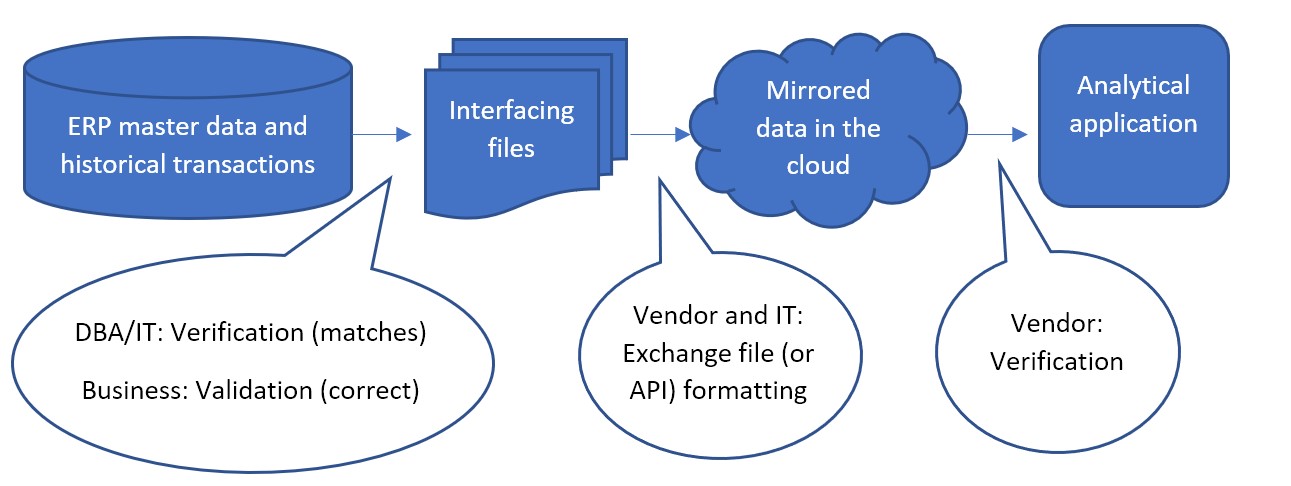
Minder vaak wordt de eerste stap tussen ERP-stamgegevens en de gekoppelde bestanden soms overgeslagen, waarbij bestanden niet als interface worden gebruikt. In plaats daarvan is een API die is gebouwd door IT of de leverancier van software voor inventarisoptimalisatie verantwoordelijk voor het rechtstreeks schrijven van gegevens vanuit de ERP naar de gespiegelde database in de cloud. De leverancier zou samenwerken met IT om te bevestigen dat de API werkt zoals verwacht. Maar zelfs in dat geval kan de eerste validatiestap nog steeds worden uitgevoerd. Na opname van de gegevens kan de leverancier de gespiegelde gegevens beschikbaar maken in bestanden voor de DBA/IT-verificatie en bedrijfsvalidatie.
De bevestiging dat de gespiegelde data in de cloud de stroom naar de applicatie voltooit, is de verantwoordelijkheid van de leverancier van software-as-a-service. SaaS-leveranciers testen voortdurend of de software correct werkt tussen de front-end-applicatie die hun abonnees zien en de back-end-gegevens in de clouddatabase. Als de abonnees nog steeds denken dat de gegevens niet kloppen in de applicatie, zelfs nadat ze de interfacing-bestanden hebben gevalideerd voordat ze live gaan, is dat een probleem dat ze moeten bespreken met de klantenondersteuning van de leverancier.
Hoe de interfacing-bestanden ook worden verkregen, het grootste deel van de verificatie en validatie komt toe aan de projectmanager en zijn team. Ze moeten een test van de interfacing-bestanden uitvoeren om te bevestigen:
- Ze matchen de gegevens in het ERP. En dat alle en alleen de ERP-gegevens die nodig waren om te extraheren voor gebruik in de applicatie, werden geëxtraheerd.
- Niets "springt eruit" voor het bedrijf als onjuist voor elk van de soorten informatie in de gegevens
- Ze zijn geformatteerd zoals verwacht.
DBA/IT Verificatie Taken
- Test het uittreksel:
IT's verificatiestap kan worden gedaan met verschillende tools, waarbij bestanden worden vergeleken of bestanden worden terug geïmporteerd naar de database als tijdelijke tabellen en ze worden samengevoegd met de originele gegevens om een match te bevestigen. IT kan afhankelijk zijn van een query om de gevraagde gegevens naar een bestand te halen, maar dat bestand kan niet overeenkomen. Het bestaan van scheidingstekens of regelretouren binnen de gegevenswaarden kan ertoe leiden dat een bestand afwijkt van de oorspronkelijke databasetabel. Het is omdat het bestand sterk afhankelijk is van scheidingstekens en regelterugloop om velden en records te identificeren, terwijl de tabel niet afhankelijk is van die tekens om de structuur te definiëren.
- Geen slechte karakters:
Vrije gegevensinvoervelden in het ERP, zoals productbeschrijvingen, kunnen soms zelf regeleinden, tabs, komma's en/of dubbele aanhalingstekens bevatten die de structuur van het uitvoerbestand kunnen beïnvloeden. Regelretouren mogen niet worden toegestaan in waarden die naar een bestand worden geëxtraheerd. Tekens die gelijk zijn aan het scheidingsteken moeten tijdens het extraheren worden verwijderd of er moet een ander scheidingsteken worden gebruikt.
Tip: als komma's het bestandsscheidingsteken zijn, kunnen getallen groter dan 999 niet worden geëxtraheerd met een komma. Gebruik "1000" in plaats van "1000".
- Bevestig de filters:
De andere manier waarop query-extracten onverwachte resultaten kunnen opleveren, is als voorwaarden voor de query onjuist zijn ingevoerd. De eenvoudigste manier om verkeerde "where-clausules" te voorkomen, is door ze niet te gebruiken. Extraheer alle gegevens en laat de leverancier enkele records eruit filteren volgens de regels die door het bedrijf zijn verstrekt. Als dit leidt tot uittrekbestanden die zo groot zijn dat er te veel rekentijd wordt besteed aan de gegevensuitwisseling, moet het DBA/IT-team met het bedrijf overleggen om precies te bevestigen welke filters op de gegevens kunnen worden toegepast om te voorkomen dat records worden uitgewisseld die geen betekenis hebben voor de gegevensuitwisseling. sollicitatie.
Tip: Houd er rekening mee dat actief/inactief of informatie over de levenscyclus van items niet mag worden gebruikt om records uit te filteren. Deze informatie moet naar de applicatie worden gestuurd, zodat deze weet wanneer een item inactief wordt.
- Wees consistent:
Het extractieproces moet elke keer dat het wordt uitgevoerd, bestanden met een consistent formaat produceren. Bestandsnamen, veldnamen en positie, scheidingsteken en Excel-bladnaam als Excel wordt gebruikt, numerieke formaten en datumnotaties, en het gebruik van aanhalingstekens rond waarden mogen nooit verschillen van de ene uitvoering van het extract van dag tot dag. Voor elke uitvoering van het uittreksel moet een hands-off rapport of opgeslagen procedure worden opgesteld en gebruikt.
Zakelijke validatie achtergrond
Hieronder vindt u een uitsplitsing van elke validatiestap in overwegingen, met name in het geval dat de leverancier een sjabloonformaat heeft verstrekt voor de gekoppelde bestanden, waarbij elk type informatie in een eigen bestand wordt verstrekt. Bestanden die vanuit uw ERP naar Smart worden verzonden, zijn geformatteerd zodat ze eenvoudig vanuit het ERP kunnen worden geëxporteerd. Dat soort formaat maakt de vergelijking terug naar het ERP een relatief eenvoudige taak voor IT, maar het kan moeilijker zijn voor het bedrijf om te interpreteren. De beste praktijk is om de ERP-gegevens te manipuleren, hetzij door draaitabellen of iets dergelijks in een spreadsheet te gebruiken. IT kan helpen door geherformatteerde gegevensbestanden aan te bieden voor beoordeling door het bedrijf.
Als u zich wilt verdiepen in de interfacing-bestanden, moet u ze begrijpen. De leverancier zal een nauwkeurig sjabloon leveren, maar over het algemeen bestaan de interfacebestanden uit drie typen: catalogusgegevens, artikelkenmerken en transactiegegevens.
- Catalogusgegevens bevatten identifiers en hun attributen. Identificaties zijn typisch voor producten, locaties (dit kunnen fabrieken of magazijnen zijn), uw klanten en uw leveranciers.
- Artikelkenmerken bevatten informatie over producten op locaties die nodig zijn voor analyse van de product- en locatiecombinatie. Zoals:
- Huidig bevoorradingsbeleid in de vorm van een Min en Max, Bestelpunt, of Herzieningsperiode en Bestelling tot waarde, of Veiligheidsvoorraad
- Toewijzing primaire leverancier en nominale doorlooptijd en kosten per eenheid van die leverancier
- Vereisten voor de bestelhoeveelheid, zoals de minimale bestelhoeveelheid, de grootte van de productieserie of veelvouden van bestellingen
- Actieve/inactieve status van de combinatie product/locatie of vlaggen die de status ervan in de levenscyclus aangeven, zoals pre-obsolete
- Attributen voor groepering of filtering, zoals toegewezen inkoper/planner of productcategorie
- Actuele voorraadinformatie zoals bij de hand, op bestelling en in transithoeveelheden.
- Transactiegegevens bevatten verwijzingen naar identifiers samen met datums en hoeveelheden. Zoals de verkochte hoeveelheid in een verkooporder van een product, op een locatie, voor een klant, op een datum. Of hoeveelheid geplaatst op inkooporder van een product, naar een locatie, van een leverancier, op een datum. Of hoeveelheid gebruikt in een werkorder van een componentproduct op een locatie op een datum.
Catalogusgegevens valideren
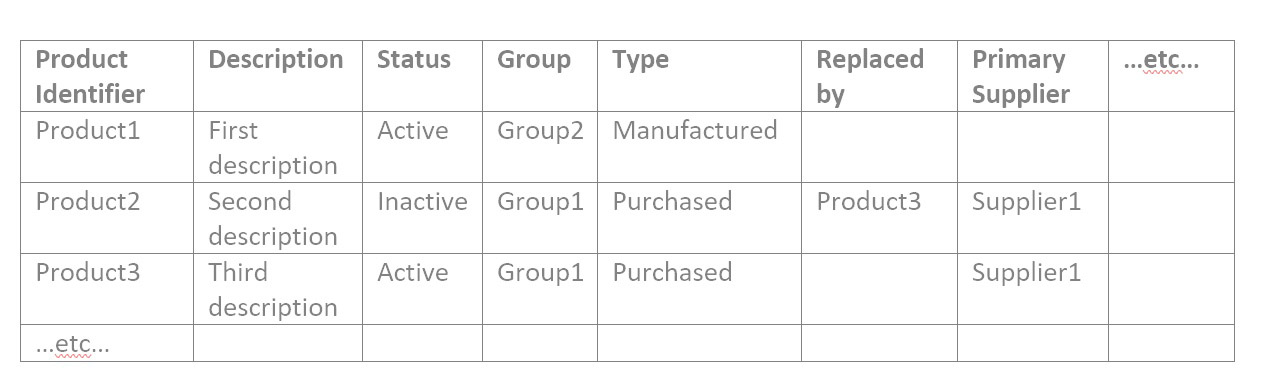
Als u eerst de catalogusgegevens bekijkt, hebt u mogelijk catalogusbestanden die lijken op deze voorbeelden:
| Locatie-ID |
Beschrijving |
Regio |
Bron Locatie |
enz… |
| Locatie1 |
Eerste locatie |
noorden |
|
|
| Locatie2 |
Tweede locatie |
zuiden |
Locatie1 |
|
| Locatie3 |
Derde locatie |
zuiden |
Locatie1 |
|
| …enz… |
|
|
|
|
| Klantidentificatie |
Beschrijving |
Verkoper |
Verzenden vanaf locatie |
enz… |
| Klant1 |
Eerste klant |
Jane |
Locatie1 |
|
| Klant2 |
Tweede klant |
Jane |
Locatie3 |
|
| Klant3 |
Derde klant |
Jo |
Locatie2 |
|
| …enz… |
|
|
|
|
| Identificatie van de leverancier |
Beschrijving |
Toestand |
Typische doorlooptijddagen |
enz… |
| Leverancier1 |
Eerste leverancier |
Actief |
18 |
|
| Leverancier2 |
Tweede leverancier |
Actief |
60 |
|
| Leverancier3 |
Derde leverancier |
Actief |
5 |
|
| …enz… |
|
|
|
|
1: Controleer op een redelijk aantal catalogusrecords
Open elk bestand met catalogusgegevens in een spreadsheetprogramma zoals Google Spreadsheets of MS Excel. Beantwoord deze vragen:
- Is het recordaantal in de marge? Als u ongeveer 50.000 producten heeft, zouden er niet slechts 10.000 rijen in het bestand moeten staan.
- Als het een kort bestand is, bijvoorbeeld het locatiebestand, kunt u precies bevestigen dat alle verwachte identifiers erin staan.
- Filter op elke attribuutwaarde en bevestig nogmaals dat het aantal records met die attribuutwaarde zinvol is.
2: Controleer de juistheid van waarden in elk attribuutveld
Iemand die weet wat de producten zijn en wat de groepen betekenen, moet de tijd nemen om te bevestigen dat het echt goed is, voor alle attributen van alle catalogusgegevens.
Dus als uw productbestand de attributen bevat zoals in het bovenstaande voorbeeld, zou u filteren op Status van Actief en controleren of alle resulterende producten daadwerkelijk actief zijn. Filter vervolgens op Status van Inactief en controleer of alle resulterende producten daadwerkelijk inactief zijn. Filter vervolgens op de eerste groepswaarde en bevestig dat alle resulterende producten in die groep zitten. Herhaal dit voor Groep2 en Groep3, enz. Herhaal dit voor elk attribuut in elk bestand.
Het kan helpen om deze validatie uit te voeren met een vergelijking met een reeds bestaand en vertrouwd rapport. Als u om welke reden dan ook een andere spreadsheet heeft die producten per groep weergeeft, kunt u de interfacing-bestanden daarmee vergelijken. Mogelijk moet u vertrouwd raken met de functie VERT.ZOEKEN die helpt bij het vergelijken van spreadsheets.
Artikelkenmerkgegevens valideren
1: Controleer op een redelijk aantal itemrecords
De bevestiging van de itemattribuutgegevens is vergelijkbaar met de catalogusgegevens. Bevestig dat het aantal product/locatie-combinaties logisch is in totaal en voor elk van de unieke itemkenmerken, één voor één. Dit is een voorbeeldbestand met artikelgegevens:
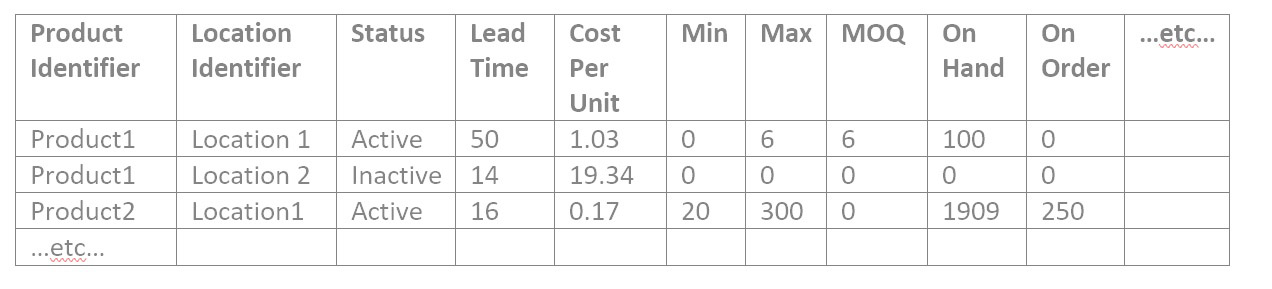
2: Zoek en verklaar rare getallen in het itembestand
Er zijn meestal veel numerieke waarden in de itemattributen, dus "rare" cijfers verdienen een beoordeling. Om gegevens voor een numeriek attribuut in een willekeurig bestand te valideren, zoekt u waar het nummer is:
- Ontbreekt volledig
- Gelijk aan nul
- Minder dan nul
- Meer dan de meeste anderen, of minder dan de meeste anderen (sorteer op die kolom)
- Helemaal geen nummer, terwijl het zou moeten zijn
Een speciale overweging van bestanden die geen catalogusbestanden zijn, is dat ze mogelijk niet de beschrijvingen van de producten en locaties tonen, alleen hun identifiers, die voor u betekenisloos kunnen zijn. U kunt kolommen invoegen voor de product- en locatiebeschrijvingen die u gewend bent te zien en deze in de spreadsheet invullen om u te helpen bij uw werk. De VLOOKUP-functie werkt hier ook voor. Of u nu wel of niet een ander rapport hebt om het Items-bestand mee te vergelijken, u hebt de catalogusbestanden voor Producten en Locatie met zowel de identifier als de beschrijving voor elke rij.
3: Controle ter plaatse
Als u gefrustreerd bent dat er te veel attribuutwaarden zijn om binnen een redelijke tijd handmatig te controleren, is steekproefsgewijze controle een oplossing. Het kan worden gedaan op een manier die waarschijnlijk problemen oppikt. Haal voor elk attribuut een lijst op met de unieke waarden in elke kolom. U kunt een kolom naar een nieuw blad kopiëren en vervolgens de functie Duplicaten verwijderen gebruiken om de lijst met mogelijke waarden te bekijken. Met het:
- Bevestig dat er geen attribuutwaarden aanwezig zijn die dat niet zouden moeten zijn.
- Het kan moeilijker zijn om te onthouden welke attribuutwaarden ontbreken die er zouden moeten zijn, dus het kan helpen om naar een andere bron te kijken om u eraan te herinneren. Als bijvoorbeeld Groep1 tot en met Groep12 aanwezig zijn, kunt u een andere bron controleren om te onthouden of dit alle mogelijke groepen zijn. Zelfs als het niet vereist is voor de interfacing-bestanden voor de applicatie, kan het voor IT gemakkelijk zijn om een lijst te extraheren van alle mogelijke groepen die in uw ERP staan, die u kunt gebruiken voor de validatie. Als u extra of ontbrekende waarden vindt die u niet verwacht, breng dan een voorbeeld van elk naar IT om te onderzoeken.
- Sorteer alfabetisch en scan naar beneden om te zien of twee waarden vergelijkbaar zijn, maar enigszins verschillen, misschien alleen in interpunctie, wat zou kunnen betekenen dat in één record de attribuutgegevens onjuist zijn ingevoerd.
Controleer voor elk type item, misschien één van elke productgroep en/of locatie, of alle attributen in elk bestand correct zijn of op zijn minst een sanity check doorstaan. Hoe meer u een breed scala aan items kunt controleren, hoe kleiner de kans dat u problemen zult hebben nadat ze live zijn gegaan.
Transactiegegevens valideren
Transactiebestanden kunnen allemaal een vergelijkbare indeling hebben:

1: Vind rare getallen in elk transactiebestand en leg ze uit
Deze moeten worden gecontroleerd op "rare" getallen in het veld Hoeveelheid. Dan kunt u doorgaan naar:
- Filter op datums buiten het verwachte bereik of ontbrekende verwachte datums.
- Zoek waar transactie-ID's en regelnummers ontbreken. Dat zouden ze niet moeten zijn.
- Als er meer dan één record is voor een bepaalde combinatie van transactie-ID en transactieregelnummer, is dat dan een vergissing? Anders gezegd, moeten dubbele records hun hoeveelheden bij elkaar optellen of is dat dubbeltelling?
2: Sanity check opgetelde hoeveelheden
Voer een gezond verstand uit door te filteren op een bepaald product waarmee u bekend bent, en filter op een herkenbare periode zoals vorige maand of vorig jaar, en som de hoeveelheden op. Is dat totale bedrag wat u voor dat product in dat tijdsbestek verwachtte? Als u informatie heeft over het totale gebruik buiten een locatie, kunt u de gegevens op die manier splitsen om de hoeveelheden op te tellen en te vergelijken met wat u verwacht. Draaitabellen zijn handig voor verificatie van transactiegegevens. Met hen kunt u de gegevens bekijken zoals:
| Product |
Jaar |
Hoeveelheid Totaal |
| Prod1 |
2022 |
9,034 |
| Prod1 |
2021 |
8,837 |
| enz |
|
|
Het jaarlijkse totaal van de producten kan eenvoudig te controleren zijn als u de producten goed kent. Of u kunt VERT.ZOEKEN gebruiken om attributen toe te voegen, zoals een productgroep, en daarop draaien om een hoger niveau te zien dat vertrouwder is:
| Productgroep |
Jaar |
Hoeveelheid Totaal |
| Groep 1 |
2022 |
22,091 |
| Groep2 |
2021 |
17,494 |
| enz |
|
|
3: Sanity check telling van records
Het kan helpen om een aantal transacties weer te geven in plaats van een som van de hoeveelheden, vooral voor inkoopordergegevens. Zoals:
| Product |
Jaar |
Aantal PO's |
| Prod1 |
2022 |
4 |
| Prod1 |
2021 |
1 |
| enz |
|
|
En/of dezelfde samenvatting op een hoger niveau, zoals:
| Productgroep |
Jaar |
Aantal PO's |
| Groep 1 |
2022 |
609 |
| Groep2 |
2021 |
40 |
| enz |
|
|
4: Controle ter plaatse
Steekproefsgewijs controleren van de juistheid van een enkele transactie, voor elk type artikel en elk type transactie, voltooit de due diligence. Besteed speciale aandacht aan welke datum aan de transactie is gekoppeld en of deze geschikt is voor de analyse. Datums kunnen een aanmaakdatum zijn, zoals de datum waarop een klant een bestelling bij u heeft geplaatst, of een beloftedatum, zoals de datum waarop u verwachtte te leveren op de bestelling van de klant op het moment dat u deze aanmaakte, of een uitvoeringsdatum, wanneer u daadwerkelijk heeft geleverd op de bestelling. Soms wordt een beloftedatum gewijzigd dagen nadat de bestelling is gemaakt als deze niet kan worden gehaald. Zorg ervoor dat de gebruiksdatum de werkelijke vraag van de klant naar het product zo goed mogelijk weergeeft.
Wat te doen met slechte gegevens
Als er weinig of eenmalig foutieve invoer is, kunt u de ERP-records met de hand bewerken zodra ze worden gevonden, waardoor uw cataloguskenmerken worden opgeschoond, zelfs nadat de applicatie live is gegaan. Maar als grote hoeveelheden attributen of transactiehoeveelheden niet kloppen, kan dit een intern project ertoe aanzetten om gegevens opnieuw correct in te voeren en mogelijk om het proces te wijzigen of te documenteren dat moet worden gevolgd wanneer nieuwe records in uw ERP worden ingevoerd.
Er moet voor worden gezorgd dat de implementatie van de SaaS-applicatie niet te lang op zich laat wachten tijdens het wachten op schone attributen. Verdeel het werk in brokken en gebruik de applicatie om eerst de opgeschoonde gegevens te analyseren, zodat het gegevensopschoningsproject parallel loopt met het halen van waarde uit de nieuwe applicatie.