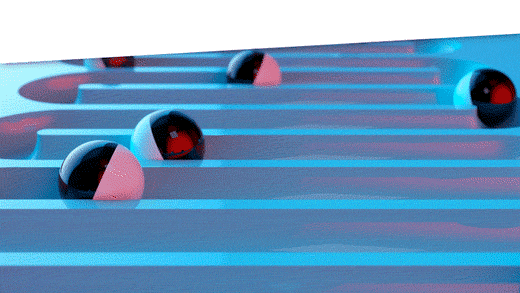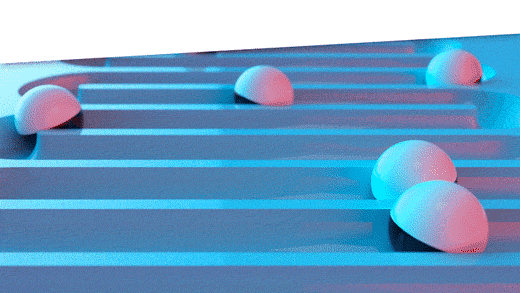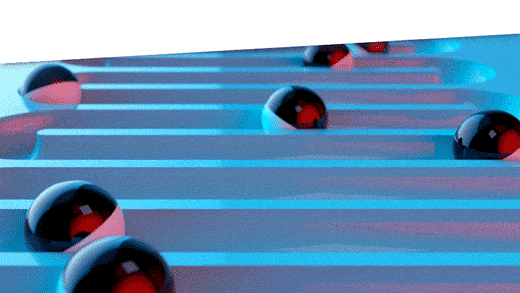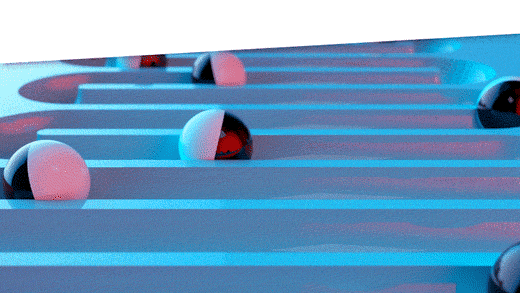Smart IP&O biedt geautomatiseerde statistische prognoses die de juiste prognosemethode selecteren die de gegevens het beste voorspelt. Het doet dit voor elke tijdreeks in de dataset. Deze blog zal leken helpen begrijpen hoe de voorspellingsmethoden automatisch worden gekozen.
Smart stelt vele methoden beschikbaar, waaronder enkele en dubbele exponentiële afvlakking, lineair en eenvoudig voortschrijdend gemiddelde, en Winters-modellen. Elk model is ontworpen om een ander soort patroon vast te leggen. De criteria om automatisch één statistische methode uit een reeks keuzes te kiezen, zijn gebaseerd op welke methode het dichtst bij het correct voorspellen van de achtergehouden geschiedenis kwam.
Eerdere vraaggeschiedenis wordt aan elke methode doorgegeven en het resultaat wordt vergeleken met de werkelijke waarden om de methode te vinden die er in het algemeen het dichtst bij kwam. Die "winnende" automatisch gekozen methode krijgt dan alle geschiedenis voor dat item om de prognose te produceren.
De algehele aard van het vraagpatroon voor het item wordt vastgelegd door verschillende delen van de geschiedenis vast te houden, zodat een incidentele uitbijter de keuze van de methode niet onnodig beïnvloedt. U kunt het visualiseren met behulp van het onderstaande diagram, waarin elke rij een 3-periodevoorspelling in de uitgehouden geschiedenis vertegenwoordigt, gebaseerd op verschillende hoeveelheden van de rode eerdere geschiedenis. De varianties van elke pass worden samen gemiddeld om de algemene rangschikking van de methode ten opzichte van alle andere methoden te bepalen.
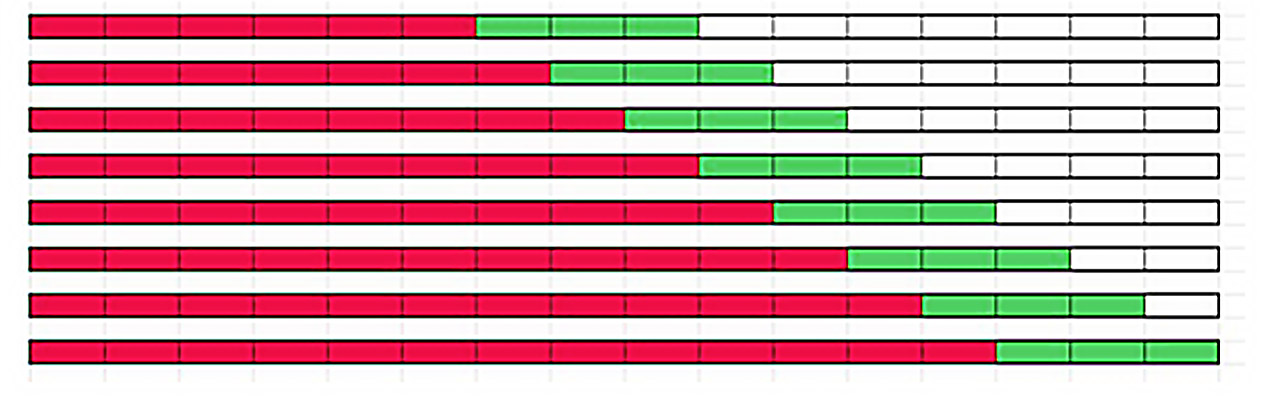
Voor de meeste tijdreeksen kan dit proces nauwkeurig trends, seizoensinvloeden en gemiddeld volume vastleggen. Maar soms komt een gekozen methode wiskundig het dichtst in de buurt van het voorspellen van de achtergehouden geschiedenis, maar projecteert deze niet op een logische manier.
Gebruikers kunnen dit corrigeren door de uitzonderingsrapporten en filterfuncties van het systeem te gebruiken om items te identificeren die een beoordeling verdienen. Vervolgens kunnen ze de automatische prognosemethoden configureren waarmee ze voor dat item in aanmerking willen komen.