¿Está confundido acerca de qué es la IA y qué es el aprendizaje automático? ¿No está seguro de por qué saber más le ayudará con su trabajo de planificación de inventario? No te desesperes. Estarás bien y te mostraremos cómo algo de lo que sea puede ser útil.
¿Qué es y qué no es?
¿Qué es la IA y en qué se diferencia del ML? Bueno, ¿qué hace alguien hoy en día cuando quiere saber algo? Lo buscan en Google. Y cuando lo hacen, comienza la confusión.
Una fuente dice que la metodología de la red neuronal llamada aprendizaje profundo es un subconjunto del aprendizaje automático, que es un subconjunto de la IA. Pero otra fuente dice que el aprendizaje profundo ya es parte de la IA porque en cierto modo imita la forma en que funciona la mente humana, mientras que el aprendizaje automático no intenta hacer eso.
Una fuente dice que hay dos tipos de aprendizaje automático: supervisado y no supervisado. Otro dice que hay cuatro: supervisada, no supervisada, semisupervisada y de refuerzo.
Algunos dicen que el aprendizaje por refuerzo es aprendizaje automático; otros lo llaman IA.
Algunos de nosotros, los tradicionalistas, llamamos a muchas de ellas “estadísticas”, aunque no todas lo son.
Al nombrar los métodos, hay mucho espacio tanto para la emoción como para el arte de vender. Si un proveedor de software cree que usted quiere escuchar la frase "IA", es posible que la diga por usted sólo para hacerlo feliz.
Mejor centrarse en lo que sale al final.
Puede evitar algunas exageraciones confusas si se concentra en el resultado final que obtiene de alguna tecnología analítica, independientemente de su etiqueta. Hay varias tareas analíticas que son relevantes para los planificadores de inventario y los planificadores de demanda. Estos incluyen agrupamiento, detección de anomalías, detección de cambios de régimen y análisis de regresión. Los cuatro métodos suelen, aunque no siempre, clasificarse como métodos de aprendizaje automático. Pero sus algoritmos pueden surgir directamente de la estadística clásica.
Agrupación
Agrupar significa agrupar cosas que son similares y distanciarlas de cosas que son diferentes. A veces, agrupar es fácil: para separar geográficamente a sus clientes, simplemente ordénelos por estado o región de ventas. Cuando el problema no es tan obvio, puede utilizar datos y algoritmos de agrupamiento para realizar el trabajo automáticamente, incluso cuando se trata de conjuntos de datos masivos.
Por ejemplo, la Figura 1 ilustra un grupo de “perfiles de demanda”, que en este caso divide todos los artículos de un cliente en nueve grupos según la forma de sus curvas de demanda acumuladas. El grupo 1.1 en la parte superior izquierda contiene artículos cuya demanda se ha ido agotando, mientras que el grupo 3.1 en la parte inferior izquierda contiene artículos cuya demanda se ha acelerado. La agrupación también se puede realizar con proveedores. La elección del número de clústeres normalmente se deja a criterio del usuario, pero ML puede guiar esa elección. Por ejemplo, un usuario puede indicarle al software que "divida mis partes en 4 grupos", pero el uso de ML puede revelar que en realidad hay 6 grupos distintos que el usuario debe analizar.
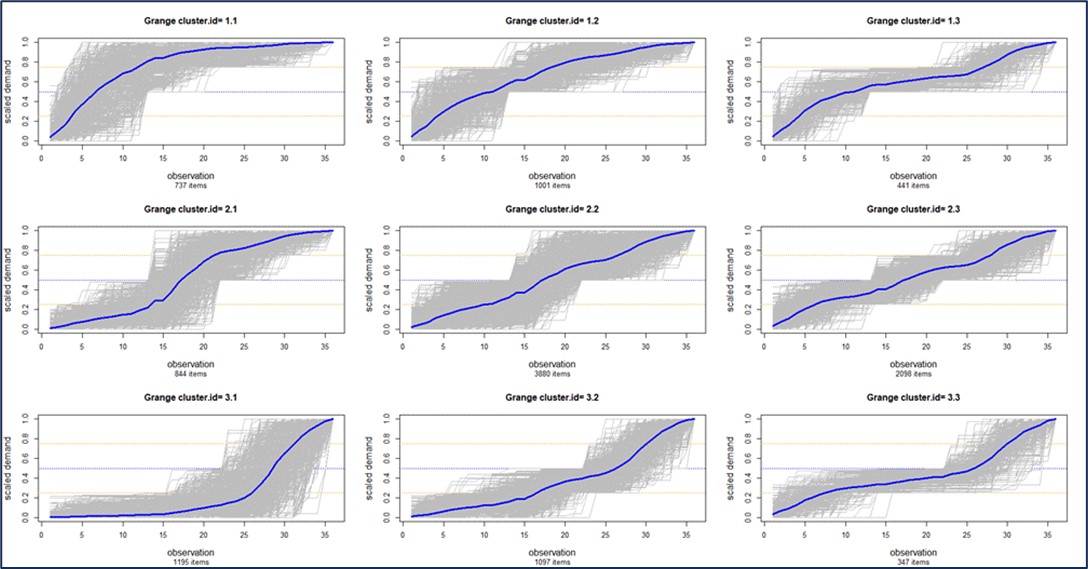
Figura 1: Agrupación de artículos según las formas de su demanda acumulada
Detección de anomalías
La previsión de la demanda se realiza tradicionalmente mediante la extrapolación de series temporales. Por ejemplo, el suavizado exponencial simple funciona para encontrar el “medio” de la distribución de la demanda en cualquier momento y proyectar ese nivel hacia adelante. Sin embargo, si ha habido un aumento o disminución repentino y único en la demanda en el pasado reciente, ese valor anómalo puede tener un efecto significativo pero no deseado en el pronóstico a corto plazo. Igual de grave para la planificación de inventarios, la anomalía puede tener un efecto enorme en la estimación de la variabilidad de la demanda, que va directamente al cálculo de los requisitos de existencias de seguridad.
Es posible que los planificadores prefieran encontrar y eliminar dichas anomalías (y tal vez hacer un seguimiento fuera de línea para descubrir el motivo de la rareza). Pero nadie que tenga un gran trabajo que hacer querrá escanear visualmente miles de gráficos de demanda para detectar valores atípicos, eliminarlos del historial de demanda y luego volver a calcular todo. La inteligencia humana podría hacer eso, pero la paciencia humana pronto fallaría. Los algoritmos de detección de anomalías podrían hacer el trabajo automáticamente utilizando métodos estadísticos relativamente sencillos. Podrías llamar a esto “inteligencia artificial” si lo deseas.
Detección de cambio de régimen
La detección de cambios de régimen es como el hermano mayor de la detección de anomalías. El cambio de régimen es un cambio sostenido, más que temporal, en uno o más aspectos del carácter de una serie temporal. Si bien la detección de anomalías suele centrarse en cambios repentinos de la demanda media, el cambio de régimen podría implicar cambios en otras características de la demanda, como su volatilidad o su forma distributiva.
La Figura 2 ilustra un ejemplo extremo de cambio de régimen. La demanda de este artículo tocó fondo alrededor del día 120. Las políticas de control de inventario y los pronósticos de demanda basados en datos más antiguos estarían tremendamente fuera de lugar al final del historial de demanda.
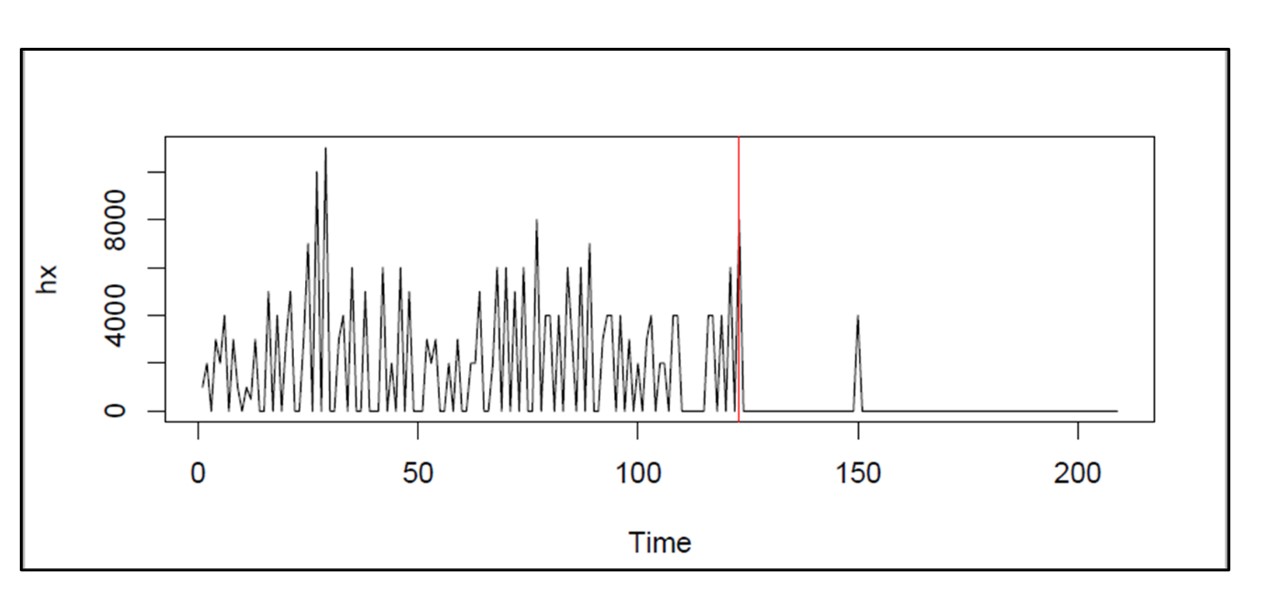
Figura 2: Un ejemplo de cambio de régimen extremo en un artículo con demanda intermitente
También en este caso se pueden desarrollar algoritmos estadísticos para resolver este problema, y sería justo llamarlos “aprendizaje automático” o “inteligencia artificial” si así estuviera motivado. El uso de ML o AI para identificar cambios de régimen en el historial de la demanda permite que el software de planificación de la demanda utilice automáticamente solo el historial relevante al realizar pronósticos en lugar de tener que seleccionar manualmente la cantidad de historial para introducirlo en el modelo.
Análisis de regresión
El análisis de regresión relaciona una variable con otra mediante una ecuación. Por ejemplo, las ventas de marcos de ventanas en un mes pueden predecirse a partir de los permisos de construcción expedidos unos meses antes. El análisis de regresión se ha considerado parte de la estadística durante más de un siglo, pero podemos decir que es "aprendizaje automático", ya que un algoritmo encuentra la manera precisa de convertir el conocimiento de una variable en una predicción del valor de otra.
Resumen
Es razonable estar interesado en lo que sucede en las áreas de aprendizaje automático e inteligencia artificial. Si bien la atención prestada a ChatGPT y sus competidores es interesante, no es relevante para el aspecto numérico de la planificación de la demanda o la gestión de inventario. Los aspectos numéricos del ML y la IA son potencialmente relevantes, pero hay que intentar ver a través de la nube de publicidad que rodea a estos métodos y centrarse en lo que pueden hacer. Si puede hacer el trabajo con métodos estadísticos clásicos, puede hacerlo y luego ejercer su opción de pegar la etiqueta ML a cualquier cosa que se mueva.