Ik begin met een bekentenis: ik ben een algoritme-man. Mijn hart leeft in de ‘machinekamer’ van onze software, waar razendsnelle berekeningen heen en weer gaan door de AWS-cloud, waardoor vraag- en aanbodscenario’s worden gegenereerd die worden gebruikt als leidraad voor belangrijke beslissingen over vraagvoorspelling en voorraadbeheer.
Maar ik erken dat het doelwit van al die mooie, woedende berekeningen het brein van de baas is, de persoon die verantwoordelijk is om ervoor te zorgen dat op de meest efficiënte en winstgevende manier aan de vraag van de klant wordt voldaan. Deze blog gaat dus over Smart Operational Analytics (SOA), waarmee rapportages voor het management worden gemaakt. Of, zoals ze in het leger worden genoemd, sit-reps.
Alle berekeningen die door de planners met behulp van onze software worden begeleid, worden uiteindelijk gedestilleerd in de SOA-rapporten voor het management. De rapporten richten zich op vijf gebieden: voorraadanalyse, voorraadprestaties, voorraadtrends, leveranciersprestaties en vraagafwijkingen.
Voorraadanalyse
Deze rapporten houden de huidige voorraadniveaus in de gaten en identificeren gebieden die verbetering behoeven. De nadruk ligt op de huidige voorraadaantallen en hun status (voorhanden, onderweg, in quarantaine), voorraadwisselingen en excessen versus tekorten.
Voorraadprestaties
Deze rapporten houden Key Performance Indicators (KPI's) bij, zoals opvullingspercentages, serviceniveaus en voorraadkosten. De analytische berekeningen elders in de software begeleiden u bij het behalen van uw KPI-doelen door Key Performance Predictions (KPP's) te berekenen op basis van aanbevolen instellingen voor bijvoorbeeld bestelpunten en bestelhoeveelheden. Maar soms komen er verrassingen voor, of wordt het operationele beleid niet uitgevoerd zoals aanbevolen, waardoor er altijd enige discrepantie zal zijn tussen KPP's en KPI's.
Voorraadtrends
Weten waar de zaken er vandaag voor staan is belangrijk, maar zien waar de zaken zich ontwikkelen is ook waardevol. Deze rapporten onthullen trends in de vraag naar artikelen, voorraadgebeurtenissen, het gemiddelde aantal beschikbare dagen, de gemiddelde verzendtijd en meer.
Prestaties van leveranciers
Uw bedrijf kan niet optimaal presteren als uw leveranciers u naar beneden halen. Deze rapporten monitoren de prestaties van leveranciers op het gebied van de nauwkeurigheid en snelheid van het invullen van aanvullingsorders. Als u meerdere leveranciers voor hetzelfde artikel heeft, kunt u deze met elkaar vergelijken.
Vraagafwijkingen
Uw gehele voorraadsysteem is vraaggestuurd en alle voorraadbeheerparameters worden berekend na het modelleren van de artikelvraag. Dus als er iets vreemds gebeurt aan de vraagzijde, moet u waakzaam zijn en u voorbereiden op het herberekenen van zaken als min- en max-waarden voor artikelen die zich vreemd beginnen te gedragen.
Overzicht
Het eindpunt van alle enorme berekeningen in onze software is het dashboard dat het management laat zien wat er aan de hand is, wat de toekomst biedt en waar de aandacht op moet worden gevestigd. Smart Inventory Analytics is het onderdeel van ons software-ecosysteem gericht op de C-Suite van uw bedrijf.
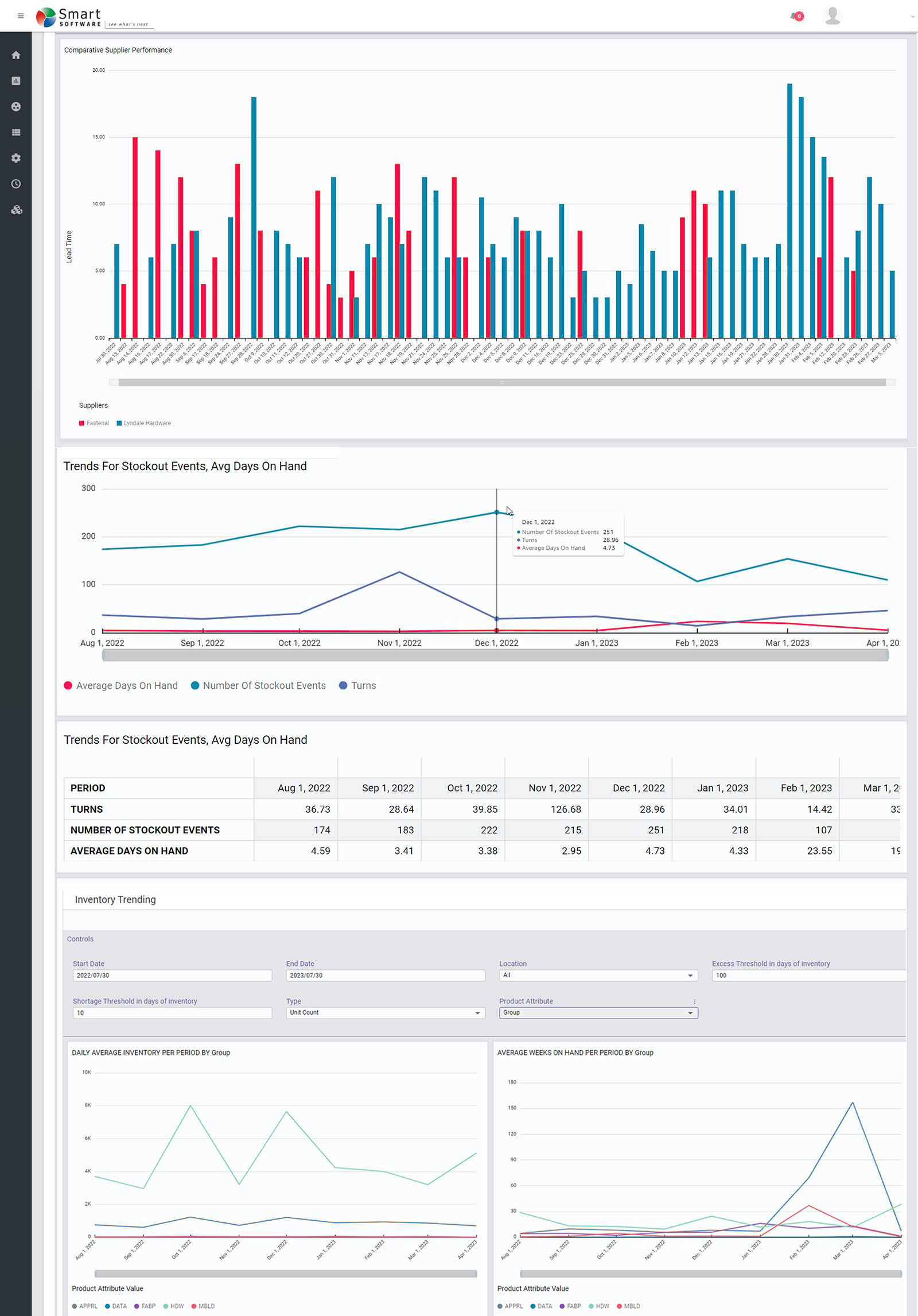
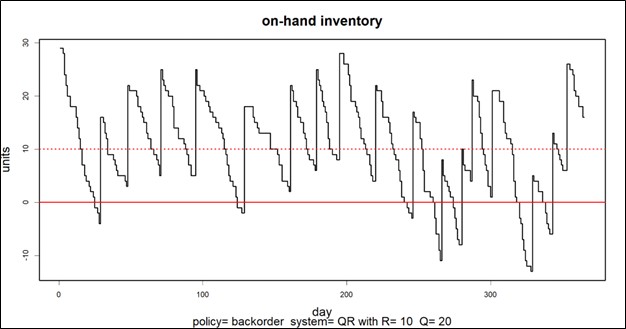
Figuur 1: Enkele voorbeeldrapportages in grafische vorm