ACHTERGROND
De meeste blogs, webinars en whitepapers van Smart Software beschrijven het gebruik van onze software bij ‘normale werkzaamheden’. Deze gaat over ‘onregelmatige operaties’. Smart Software is bezig met het aanpassen van onze producten om u te helpen omgaan met uw eigen onregelmatige werkzaamheden. Dit is een voorproefje.
Ik hoorde de term ‘irreguliere operaties’ voor het eerst toen ik een sabbatical-tournee maakte bij de Amerikaanse Federal Aviation Administration in Washington, DC. De FAA verkort de term tot “IROPS” en gebruikt deze om situaties te beschrijven waarin weersomstandigheden, mechanische problemen of andere problemen de normale vliegtuigstroom verstoren.
Smart Inventory Optimization® (“SIO”) werkt momenteel aan het bieden van een zogenaamd “steady state”-beleid voor het beheren van voorraadartikelen. Dat betekent bijvoorbeeld dat SIO automatisch waarden berekent voor bestelpunten (ROP's) en bestelhoeveelheden (OQ's) die bedoeld zijn om in de nabije toekomst mee te gaan. Het berekent deze waarden op basis van simulaties van dagelijkse activiteiten die jaren in de toekomst reiken. Als en wanneer het onvoorzienbare gebeurt, zullen onze verandering van regime De detectiemethode reageert door verouderde gegevens te verwijderen en herberekening van de ROP's en OQ's mogelijk te maken.
We merken vaak de toenemende snelheid van zakendoen, waardoor de duur van de “afzienbare toekomst” wordt verkort. Sommige van onze klanten hanteren nu een kortere planningshorizon, zoals de overstap van kwartaal- naar maandplannen. Eén neveneffect van deze verandering is dat IROPS meer consequenties heeft. Als een plan gebaseerd is op drie gesimuleerde jaren van dagelijkse vraag, doet één vreemde gebeurtenis, zoals een grote verrassingsbestelling, er in het grote geheel niet zoveel toe. Maar als de planningshorizon erg kort is, kan één grote verrassingsvraag een groot effect hebben op de belangrijkste prestatie-indicatoren (KPI's) die over een korter interval worden berekend – er is geen tijd voor 'uitmiddelen'. De planner kan zich genoodzaakt zien een noodbestelling te plaatsen om de verstoring op te vangen. Wanneer moet de bestelling worden geplaatst om het meeste goed te doen? Hoe groot moet het zijn?
SCENARIO: NORMALE OPS
Om dit concreet te maken, beschouwen we het volgende scenario. Tom's Spares, Inc. levert kritische serviceonderdelen aan zijn klanten, waaronder SKU723, een vervangende printplaat die wordt verkocht onder de handelsnaam WIDGET. De vraag naar WIDGET is wisselend, er wordt minder dan één eenheid per dag gevraagd. Tom's Spares bestelt WIDGET's bij Acme Products, waardoor het 7 of 10 dagen duurt om de aanvullingsbestellingen uit te voeren.
Tom's Spares werkt met een korte voorraadplanningshorizon van 28 dagen. Het bedrijf opereert in een competitieve omgeving met ongeduldige klanten die alleen met tegenzin nabestellingen accepteren. Het beleid van Tom is om ROP's en OQ's zo in te stellen dat de voorraad beperkt blijft en tegelijkertijd een opvullingspercentage van minimaal 90% wordt gehandhaafd. Het management monitort maandelijks de KPI's. In het geval van WIDGETS worden deze KPI-doelen momenteel gehaald met een ROP=3 en een OQ=4, wat resulteert in een gemiddelde voorraad van ongeveer 4 eenheden en een gemiddeld opvullingspercentage van 96%. Tom's Spares heeft iets goeds op het gebied van WIDGETS.
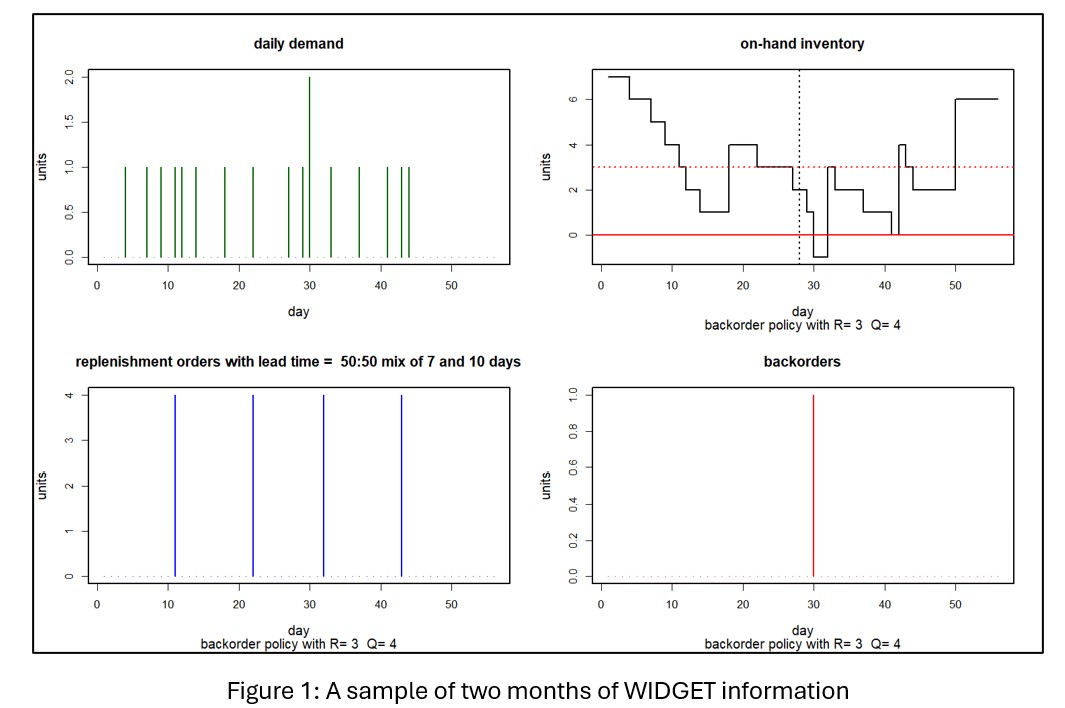
Figuur 1 toont twee maanden WIDGET-informatie. Het paneel linksboven toont de dagelijkse vraag naar eenheden. Rechtsboven ziet u de beschikbare dagelijkse eenheden. Het paneel linksonder toont de timing en de omvang van de aanvullingsorders naar Acme Products. Rechtsonder ziet u eenheden die zijn nabesteld vanwege voorraadtekorten. In deze simulatie was de dagelijkse vraag 0 of 1, met één vraag van 2 eenheden. Voorhanden eenheden begonnen de maand op 7 en daalden nooit onder de 1, hoewel er de volgende maand een voorraadtekort was, wat resulteerde in een enkele eenheid in nabestelling. Gedurende de twee maanden werden er vier aanvullingsorders van elk vier eenheden naar Acme gestuurd, die allemaal binnenkwamen tijdens de simulatieperiode van twee maanden.
GOEDE PROBLEMEN VERSTOREN NORMALE OPS
Nu voegen we wat ‘goede problemen’ toe aan het scenario: halverwege de planningsperiode ontstaat er een ongewoon grote order. Het is “goed” omdat meer vraag meer inkomsten impliceert. Maar het is een “probleem” omdat de normale parameters voor voorraadbeheer van de operatie (ROP=3, OQ=4) niet zijn gekozen om met deze situatie om te gaan. De piek in de vraag kan zo groot zijn, en zo ongunstig getimed, dat het voorraadsysteem overweldigd wordt, waardoor voorraadtekorten en de daarmee gepaard gaande nabestellingen ontstaan. Het KPI-rapport aan het management voor zo'n maand zou niet mooi zijn.
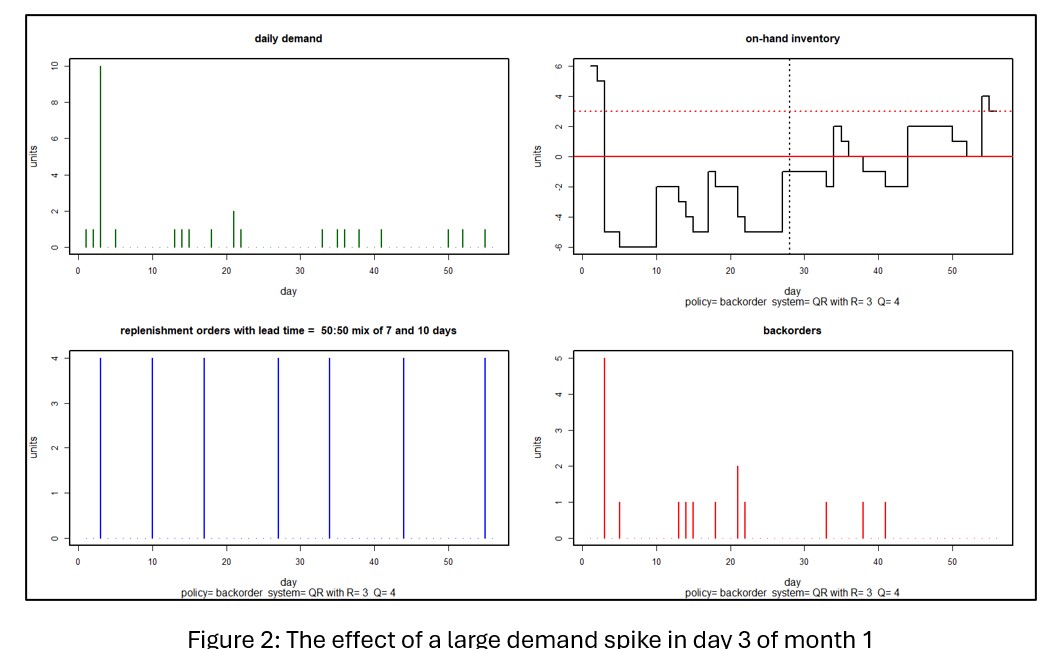
Figuur 2 toont een scenario waarin een vraagpiek van 10 eenheden optreedt op de derde dag van de planningsperiode. In dit geval zet de piek de voorraad voor de rest van de maand onder water en creëert een cascade van nabestellingen die zich uitstrekt tot de volgende maand. Met een gemiddelde van meer dan 1.000 simulaties tonen de KPI's van maand 1 een gemiddelde van 0,6 eenheden en een miserabel opvullingspercentage van 44%.
TERUGVECHTEN MET ONREGELMATIGE OPERATIES
Tom's Spares kan op een onregelmatige situatie reageren met een onregelmatige verplaatsing door een noodaanvulorder aan te maken. Om het goed te doen, moeten ze nadenken over (a) wanneer ze de bestelling moeten plaatsen, (b) hoe groot de bestelling moet zijn en (c) of ze de bestelling moeten bespoedigen.
De vraag over de timing lijkt voor de hand te liggen: reageer zodra de order toekomt. Als de klant echter vroegtijdig zou waarschuwen, zou Tom's Spares vroegtijdig kunnen bestellen en in een betere positie zijn om de verstoring als gevolg van de piek te beperken. Als de communicatie tussen Tom's en de klant die de grote bestelling plaatst echter gebrekkig is, kan het zijn dat de klant Tom's later of helemaal niet op de hoogte stelt.
Ook de omvang van de speciale bestelling lijkt voor de hand liggend: bestel het benodigde aantal eenheden vooraf. Maar dat werkt het beste als Tom's Spares weet wanneer de vraagpiek zal aanbreken. Zo niet, dan is het misschien een goed idee om extra te bestellen om de duur van eventuele nabestellingen te beperken. Over het algemeen geldt dat hoe minder vroegtijdige waarschuwing wordt gegeven, hoe groter de bestelling die Tom's moet plaatsen. Deze relatie kan uiteraard worden onderzocht met simulatie.
De aankomst van de aanvulopdracht kon worden overgelaten aan de gebruikelijke bedrijfsvoering van Acme Products. In de bovenstaande simulaties was de kans even groot dat Acme binnen zeven of veertien dagen zou reageren. Voor een planningshorizon van 28 dagen kan het risico nemen om binnen 14 dagen een antwoord te krijgen vragen om problemen zijn, dus het kan voor Tom's vooral de moeite waard zijn om Acme te betalen voor versnelde verzending. Misschien van de ene op de andere dag, maar mogelijk iets goedkoper maar toch relatief snel.
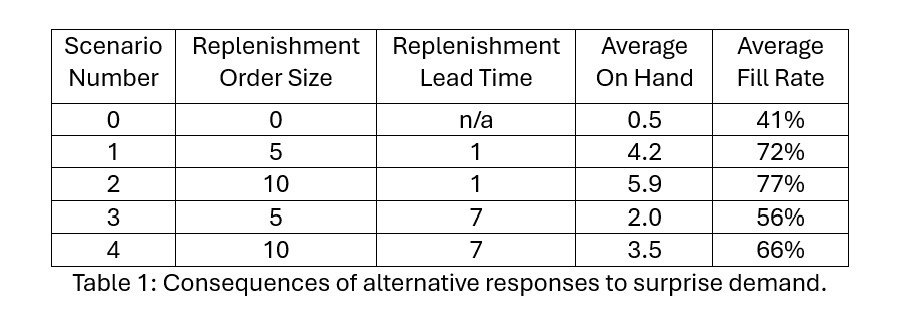
We hebben nog een paar scenario's onderzocht met behulp van simulatie. Tabel 1 toont de resultaten. Scenario's 1-4 gaan ervan uit dat er op dag 3 een verrassende extra vraag van 10 eenheden arriveert, wat aanleiding geeft tot een onmiddellijke bestelling voor extra aanvulling. De omvang en doorlooptijd van de aanvulorder varieert.
Scenario 0 laat zien dat niets doen als reactie op de verrassende vraag leidt tot een verschrikkelijk 41%-opvullingspercentage voor die maand; niet getoond is dat dit resultaat de volgende maand een aanhoudend slechte prestatie inhoudt. Reguliere operaties zullen niet goed werken. De planner moet iets doen om op de afwijkende vraag te reageren.
Als u hier iets aan wilt doen, betekent dit dat u een eenmalige noodaanvullingsbestelling moet doen. De planner moet de omvang en het tijdstip van die bestelling kiezen. Scenario's 1 en 3 tonen aanvullingen van "halve grootte". Scenario's 1 en 2 geven nachtelijke aanvullingen weer, terwijl scenario's 3 en 4 een gegarandeerde respons binnen één week weergeven.
De resultaten maken duidelijk dat onmiddellijke reactie belangrijker is dan de omvang van de aanvulorder om de opvullingsgraad te herstellen. Nachtelijke aanvulling levert opvullingspercentages op in het 70%-bereik, terwijl een aanvultijd van een week het opvullingspercentage verlaagt naar het midden-50% tot midden-60%-bereik.
AFHAALMAAL
Voorraadbeheersoftware breidt zich uit van de traditionele focus op normale operaties naar een extra focus op onregelmatige operaties (IROPS). Deze evolutie is mogelijk gemaakt door de ontwikkeling van nieuwe statistische methoden voor het genereren van vraagscenario's op dagelijks niveau.
We hebben één IROPS-situatie overwogen: de verrassende komst van een abnormaal grote vraag. Dagelijkse simulaties gaven inzicht in de timing en de omvang van een noodaanvullingsorder. De resultaten van een dergelijke analyse bieden inventarisplanners een kritische back-up door de resultaten van alternatieve interventies te schatten die hun ervaring hen suggereert.