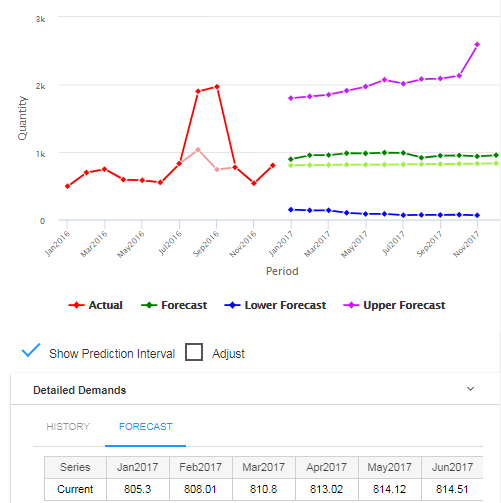
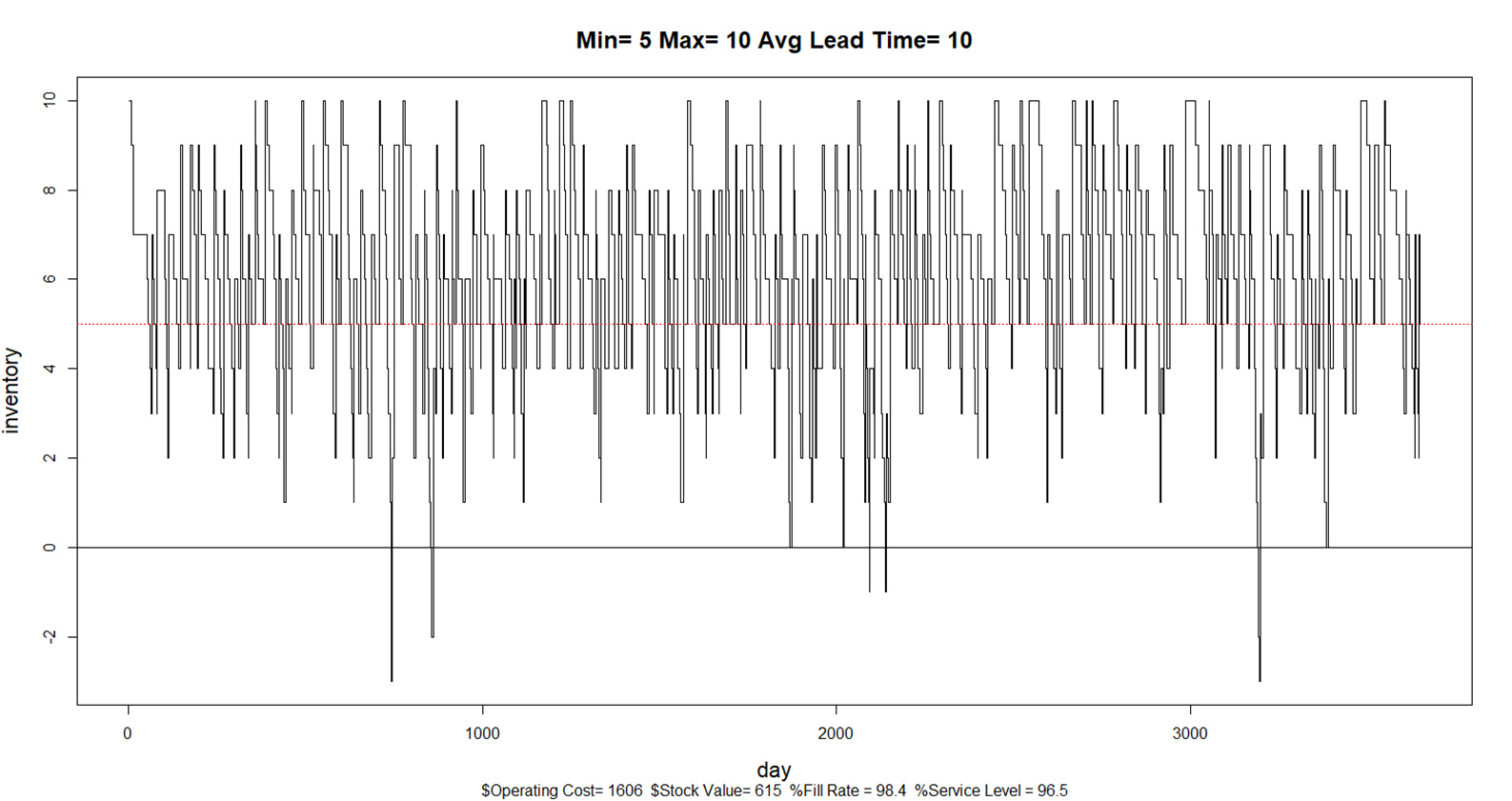
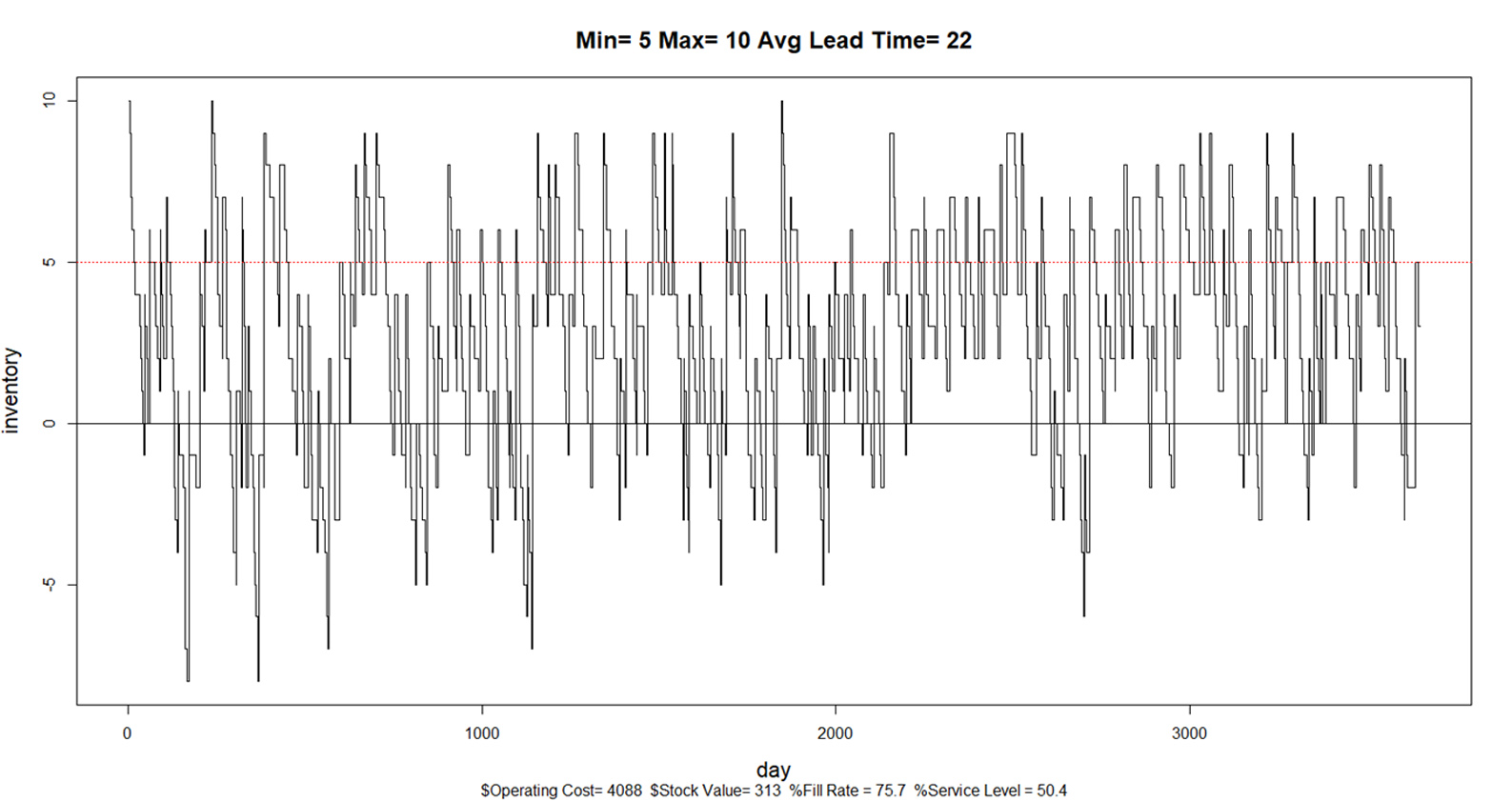
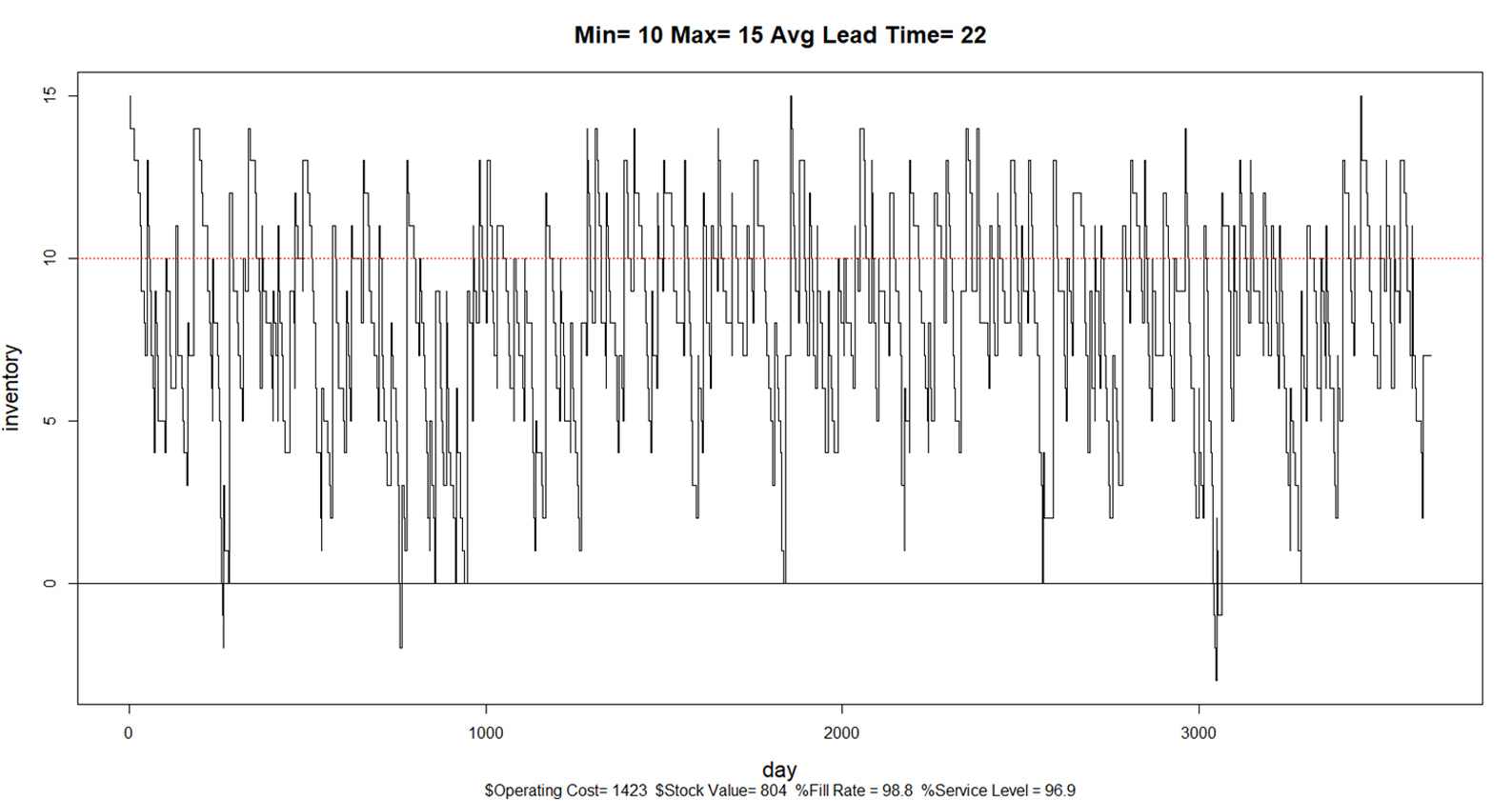
Verbeter de forecasting nauwkeurigheid, elimineer overtollige voorraad en maximaliseer service levels
In deze video-tutorial presenteert Dr. Thomas Willemain, mede-oprichter en SVP Research bij Smart Software, regressieanalyse, een gespecialiseerde statistische modelleringstechniek om leidende indicatoren te identificeren en te benutten om nauwkeurigere voorspellingen te bereiken. Regressieanalyse is een statistische procedure om de relatie tussen een responsvariabele en een of meer voorspellende variabelen te schatten. Het starten van woningen kan bijvoorbeeld een goede voorlopende indicator zijn van de vraag naar vinylbeplating. Tom legt uit hoe en wanneer je regressieanalyse gebruikt en werkt een praktijkvoorbeeld uit.

RECENTE BERICHTEN

Iedereen maakt prognoses om de voorraadplanning te stimuleren. Het is alleen de vraag hoe.
Vaak zullen bedrijven volhouden dat ze "geen prognoses gebruiken" om voorraad te plannen. Ze gebruiken vaak methodes voor bestelpunten en worstelen met het verbeteren van tijdige levering, voorraadrotaties en andere KPI's. Hoewel ze niet denken dat wat ze doen expliciet voorspellen, gebruiken ze zeker schattingen van de toekomstige vraag om bestelpunten zoals min/max te ontwikkelen.

Wat Silicon Valley Bank kan leren van Supply Chain Planning
Als je de laatste tijd je hoofd omhoog hebt gehouden, heb je misschien wat extra waanzin opgemerkt op het basketbalveld: het falen van Silicon Valley Bank. Degenen onder ons in de supply chain-wereld hebben het bankfalen misschien afgedaan als het probleem van iemand anders, maar die spijtige episode bevat ook een grote les voor ons: het belang van stresstesten die goed worden uitgevoerd.

Ontdek gegevensfeiten en verbeter de voorraadprestaties
De beste voorraadplanningsprocessen zijn gebaseerd op statistische analyse om relevante feiten over de gegevens te ontdekken. Wanneer u over de feiten beschikt en uw zakelijke kennis toevoegt, kunt u beter geïnformeerde beslissingen nemen over opslag die een aanzienlijk rendement opleveren. Je schept ook de juiste verwachtingen bij interne en externe belanghebbenden, zodat er minder ongewenste verrassingen zijn.

recente berichten
 Het beheren van de voorraad reserveonderdelen: beste praktijkenIn this blog, we’ll explore several effective strategies for managing spare parts inventory, emphasizing the importance of optimizing stock levels, maintaining service levels, and using smart tools to aid in decision-making. Managing spare parts inventory is a critical component for businesses that depend on equipment uptime and service reliability. Unlike regular inventory items, spare parts often have unpredictable demand patterns, making them more challenging to manage effectively. An efficient spare parts inventory management system helps prevent stockouts that can lead to operational downtime and costly delays while also avoiding overstocking that unnecessarily ties up capital and increases holding costs. […]
Het beheren van de voorraad reserveonderdelen: beste praktijkenIn this blog, we’ll explore several effective strategies for managing spare parts inventory, emphasizing the importance of optimizing stock levels, maintaining service levels, and using smart tools to aid in decision-making. Managing spare parts inventory is a critical component for businesses that depend on equipment uptime and service reliability. Unlike regular inventory items, spare parts often have unpredictable demand patterns, making them more challenging to manage effectively. An efficient spare parts inventory management system helps prevent stockouts that can lead to operational downtime and costly delays while also avoiding overstocking that unnecessarily ties up capital and increases holding costs. […] 5 manieren om de snelheid van beslissingen in de toeleveringsketen te verbeterenDe belofte van een digitale supply chain heeft de manier waarop bedrijven opereren getransformeerd. In de kern kan het snelle, datagestuurde beslissingen nemen en tegelijkertijd kwaliteit en efficiëntie in de hele bedrijfsvoering garanderen. Het gaat echter niet alleen om toegang tot meer data. Organisaties hebben de juiste tools en platforms nodig om die data om te zetten in bruikbare inzichten. Dit is waar besluitvorming cruciaal wordt, vooral in een landschap waar nieuwe digitale supply chain-oplossingen en AI-gestuurde platforms u kunnen ondersteunen bij het stroomlijnen van veel processen binnen de beslissingsmatrix. […]
5 manieren om de snelheid van beslissingen in de toeleveringsketen te verbeterenDe belofte van een digitale supply chain heeft de manier waarop bedrijven opereren getransformeerd. In de kern kan het snelle, datagestuurde beslissingen nemen en tegelijkertijd kwaliteit en efficiëntie in de hele bedrijfsvoering garanderen. Het gaat echter niet alleen om toegang tot meer data. Organisaties hebben de juiste tools en platforms nodig om die data om te zetten in bruikbare inzichten. Dit is waar besluitvorming cruciaal wordt, vooral in een landschap waar nieuwe digitale supply chain-oplossingen en AI-gestuurde platforms u kunnen ondersteunen bij het stroomlijnen van veel processen binnen de beslissingsmatrix. […] 12 Oorzaken van Overstocking en Praktische OplossingenEffectief voorraadbeheer is cruciaal voor het behouden van een gezonde balans en het verzekeren dat middelen optimaal worden toegewezen. Hier is een diepgaande verkenning van de belangrijkste oorzaken van overstocking, hun implicaties en mogelijke oplossingen. […]
12 Oorzaken van Overstocking en Praktische OplossingenEffectief voorraadbeheer is cruciaal voor het behouden van een gezonde balans en het verzekeren dat middelen optimaal worden toegewezen. Hier is een diepgaande verkenning van de belangrijkste oorzaken van overstocking, hun implicaties en mogelijke oplossingen. […] FAQ: Slimme IP&O voor beter voorraadbeheer.Effectief supply chain- en voorraadbeheer zijn essentieel voor het bereiken van operationele efficiëntie en klanttevredenheid. Deze blog biedt duidelijke en beknopte antwoorden op enkele basisvragen en andere veelvoorkomende vragen van onze Smart IP&O-klanten, en biedt praktische inzichten om typische uitdagingen te overwinnen en uw voorraadbeheerpraktijken te verbeteren. Met de focus op deze belangrijke gebieden helpen we u complexe voorraadproblemen om te zetten in strategische, beheersbare acties die kosten verlagen en de algehele prestaties verbeteren met Smart IP&O. […]
FAQ: Slimme IP&O voor beter voorraadbeheer.Effectief supply chain- en voorraadbeheer zijn essentieel voor het bereiken van operationele efficiëntie en klanttevredenheid. Deze blog biedt duidelijke en beknopte antwoorden op enkele basisvragen en andere veelvoorkomende vragen van onze Smart IP&O-klanten, en biedt praktische inzichten om typische uitdagingen te overwinnen en uw voorraadbeheerpraktijken te verbeteren. Met de focus op deze belangrijke gebieden helpen we u complexe voorraadproblemen om te zetten in strategische, beheersbare acties die kosten verlagen en de algehele prestaties verbeteren met Smart IP&O. […] 7 belangrijke trends in vraagplanning die de toekomst vormgevenVraagplanning gaat verder dan alleen het voorspellen van productbehoeften; het gaat erom ervoor te zorgen dat uw bedrijf nauwkeurig, efficiënt en kosteneffectief aan de vraag van klanten voldoet. De nieuwste technologie voor vraagplanning pakt belangrijke uitdagingen aan, zoals nauwkeurigheid van voorspellingen, voorraadbeheer en marktresponsiviteit. In deze blog introduceren we kritieke trends voor vraagplanning, waaronder datagestuurde inzichten, probabilistische voorspellingen, consensusplanning, voorspellende analyses, scenariomodellering, realtime zichtbaarheid en multilevel voorspellingen. Deze trends helpen u om voorop te blijven lopen, uw toeleveringsketen te optimaliseren, kosten te verlagen en de klanttevredenheid te verbeteren, waardoor uw bedrijf op de lange termijn succesvol wordt. […]
7 belangrijke trends in vraagplanning die de toekomst vormgevenVraagplanning gaat verder dan alleen het voorspellen van productbehoeften; het gaat erom ervoor te zorgen dat uw bedrijf nauwkeurig, efficiënt en kosteneffectief aan de vraag van klanten voldoet. De nieuwste technologie voor vraagplanning pakt belangrijke uitdagingen aan, zoals nauwkeurigheid van voorspellingen, voorraadbeheer en marktresponsiviteit. In deze blog introduceren we kritieke trends voor vraagplanning, waaronder datagestuurde inzichten, probabilistische voorspellingen, consensusplanning, voorspellende analyses, scenariomodellering, realtime zichtbaarheid en multilevel voorspellingen. Deze trends helpen u om voorop te blijven lopen, uw toeleveringsketen te optimaliseren, kosten te verlagen en de klanttevredenheid te verbeteren, waardoor uw bedrijf op de lange termijn succesvol wordt. […]

Voorraadoptimalisatie voor fabrikanten, distributeurs en MRO
- Het beheren van de voorraad reserveonderdelen: beste praktijkenIn this blog, we’ll explore several effective strategies for managing spare parts inventory, emphasizing the importance of optimizing stock levels, maintaining service levels, and using smart tools to aid in decision-making. Managing spare parts inventory is a critical component for businesses that depend on equipment uptime and service reliability. Unlike regular inventory items, spare parts often have unpredictable demand patterns, making them more challenging to manage effectively. An efficient spare parts inventory management system helps prevent stockouts that can lead to operational downtime and costly delays while also avoiding overstocking that unnecessarily ties up capital and increases holding costs. […]
 Innovatie van de OEM-aftermarket met AI-gestuurde voorraadoptimalisatieDe aftermarketsector biedt OEM's een beslissend voordeel door een stabiele inkomstenstroom te bieden en de loyaliteit van klanten te bevorderen door de betrouwbare en tijdige levering van serviceonderdelen. Het beheren van inventaris en het voorspellen van de vraag in de aftermarket gaat echter gepaard met uitdagingen, waaronder onvoorspelbare vraagpatronen, enorme productassortimenten en de noodzaak van snelle doorlooptijden. Traditionele methoden schieten vaak tekort vanwege de complexiteit en variabiliteit van de vraag in de aftermarket. De nieuwste technologieën kunnen grote datasets analyseren om de toekomstige vraag nauwkeuriger te voorspellen en voorraadniveaus te optimaliseren, wat leidt tot betere service en lagere kosten. […]
Innovatie van de OEM-aftermarket met AI-gestuurde voorraadoptimalisatieDe aftermarketsector biedt OEM's een beslissend voordeel door een stabiele inkomstenstroom te bieden en de loyaliteit van klanten te bevorderen door de betrouwbare en tijdige levering van serviceonderdelen. Het beheren van inventaris en het voorspellen van de vraag in de aftermarket gaat echter gepaard met uitdagingen, waaronder onvoorspelbare vraagpatronen, enorme productassortimenten en de noodzaak van snelle doorlooptijden. Traditionele methoden schieten vaak tekort vanwege de complexiteit en variabiliteit van de vraag in de aftermarket. De nieuwste technologieën kunnen grote datasets analyseren om de toekomstige vraag nauwkeuriger te voorspellen en voorraadniveaus te optimaliseren, wat leidt tot betere service en lagere kosten. […] Toekomstbestendige hulpprogramma's: geavanceerde analyses voor optimalisatie van de supply chainNutsvoorzieningen op het gebied van elektriciteit, aardgas, stedelijk water en telecommunicatie zijn allemaal activa-intensief en afhankelijk van fysieke infrastructuur die in de loop van de tijd goed moet worden onderhouden, bijgewerkt en geüpgraded. Het maximaliseren van de uptime van bedrijfsmiddelen en de betrouwbaarheid van de fysieke infrastructuur vereist effectief voorraadbeheer, prognoses van reserveonderdelen en leveranciersbeheer. Een nutsbedrijf dat deze processen effectief uitvoert, presteert beter dan zijn concurrenten, levert een beter rendement op voor zijn investeerders en hogere serviceniveaus voor zijn klanten, terwijl het zijn impact op het milieu vermindert. […]
Toekomstbestendige hulpprogramma's: geavanceerde analyses voor optimalisatie van de supply chainNutsvoorzieningen op het gebied van elektriciteit, aardgas, stedelijk water en telecommunicatie zijn allemaal activa-intensief en afhankelijk van fysieke infrastructuur die in de loop van de tijd goed moet worden onderhouden, bijgewerkt en geüpgraded. Het maximaliseren van de uptime van bedrijfsmiddelen en de betrouwbaarheid van de fysieke infrastructuur vereist effectief voorraadbeheer, prognoses van reserveonderdelen en leveranciersbeheer. Een nutsbedrijf dat deze processen effectief uitvoert, presteert beter dan zijn concurrenten, levert een beter rendement op voor zijn investeerders en hogere serviceniveaus voor zijn klanten, terwijl het zijn impact op het milieu vermindert. […] Centreringswet: timing, prijzen en betrouwbaarheid van reserveonderdelenIn dit artikel begeleiden we u bij het opstellen van een voorraadplan voor reserveonderdelen, waarbij prioriteit wordt gegeven aan beschikbaarheidsstatistieken zoals serviceniveaus en vulpercentages, terwijl de kostenefficiëntie wordt gewaarborgd. We zullen ons concentreren op een benadering van voorraadplanning genaamd Service Level-Driven Inventory Optimization. Vervolgens bespreken we hoe u kunt bepalen welke onderdelen u in uw inventaris moet opnemen en welke onderdelen mogelijk niet nodig zijn. Ten slotte onderzoeken we manieren om uw op serviceniveau gebaseerde voorraadplan consistent te verbeteren. […]
Centreringswet: timing, prijzen en betrouwbaarheid van reserveonderdelenIn dit artikel begeleiden we u bij het opstellen van een voorraadplan voor reserveonderdelen, waarbij prioriteit wordt gegeven aan beschikbaarheidsstatistieken zoals serviceniveaus en vulpercentages, terwijl de kostenefficiëntie wordt gewaarborgd. We zullen ons concentreren op een benadering van voorraadplanning genaamd Service Level-Driven Inventory Optimization. Vervolgens bespreken we hoe u kunt bepalen welke onderdelen u in uw inventaris moet opnemen en welke onderdelen mogelijk niet nodig zijn. Ten slotte onderzoeken we manieren om uw op serviceniveau gebaseerde voorraadplan consistent te verbeteren. […]