Bent u in de war over wat AI is en wat machine learning is? Weet u niet zeker waarom meer weten u zal helpen bij uw werk in voorraadplanning? Wanhoop niet. Het komt wel goed met je, en we laten je zien hoe iets van wat het ook is, nuttig kan zijn.
Wat is en wat niet
Wat is AI en waarin verschilt het van ML? Wat doet iemand tegenwoordig als hij iets wil weten? Ze Googlen het. En als ze dat doen, begint de verwarring.
Eén bron zegt dat de neurale netmethodologie, deep learning genaamd, een subset is van machine learning, een subset van AI. Maar een andere bron zegt dat deep learning al een onderdeel is van AI, omdat het min of meer de manier nabootst waarop de menselijke geest werkt, terwijl machinaal leren dat niet probeert.
Eén bron zegt dat er twee soorten machinaal leren zijn: onder toezicht en zonder toezicht. Een ander zegt dat er vier zijn: onder toezicht, zonder toezicht, semi-onder toezicht en versterking.
Sommigen zeggen dat versterkend leren machinaal leren is; anderen noemen het AI.
Sommigen van ons, traditionalisten, noemen veel ervan ‘statistieken’, hoewel dat niet allemaal zo is.
Bij het benoemen van methoden is veel ruimte voor zowel emotie als verkoopvaardigheid. Als een softwareleverancier denkt dat je de term ‘AI’ wilt horen, kan het zijn dat hij/zij dat voor je zegt, alleen maar om je blij te maken.
Het is beter om je te concentreren op wat er uiteindelijk uitkomt
Je kunt een verwarrende hype vermijden als je je concentreert op het eindresultaat dat je krijgt van een analytische technologie, ongeacht het label ervan. Er zijn verschillende analytische taken die relevant zijn voor voorraadplanners en vraagplanners. Deze omvatten clustering, detectie van afwijkingen, detectie van regimeveranderingen en regressieanalyse. Alle vier de methoden worden gewoonlijk, maar niet altijd, geclassificeerd als methoden voor machinaal leren. Maar hun algoritmen kunnen rechtstreeks uit de klassieke statistiek komen.
Clustering
Clusteren betekent het groeperen van dingen die op elkaar lijken en het distantiëren ervan van dingen die niet op elkaar lijken. Soms is clusteren eenvoudig: om uw klanten geografisch te scheiden, sorteert u ze eenvoudigweg op staat of verkoopregio. Als het probleem niet zo voor de hand liggend is, kun je data- en clusteralgoritmen gebruiken om de klus automatisch te klaren, zelfs als je met enorme datasets te maken hebt.
Figuur 1 illustreert bijvoorbeeld een cluster van “vraagprofielen”, die in dit geval alle artikelen van een klant in negen clusters verdeelt, op basis van de vorm van hun cumulatieve vraagcurven. Cluster 1.1 linksboven bevat items waarvan de vraag is afgenomen, terwijl Cluster 3.1 linksonder items bevat waarvan de vraag is toegenomen. Clusteren kan ook op leveranciers. De keuze van het aantal clusters wordt doorgaans overgelaten aan het oordeel van de gebruiker, maar ML kan die keuze begeleiden. Een gebruiker kan de software bijvoorbeeld de opdracht geven om “mijn onderdelen in vier clusters op te splitsen”, maar het gebruik van ML kan aan het licht brengen dat er in werkelijkheid zes verschillende clusters zijn die de gebruiker moet analyseren.
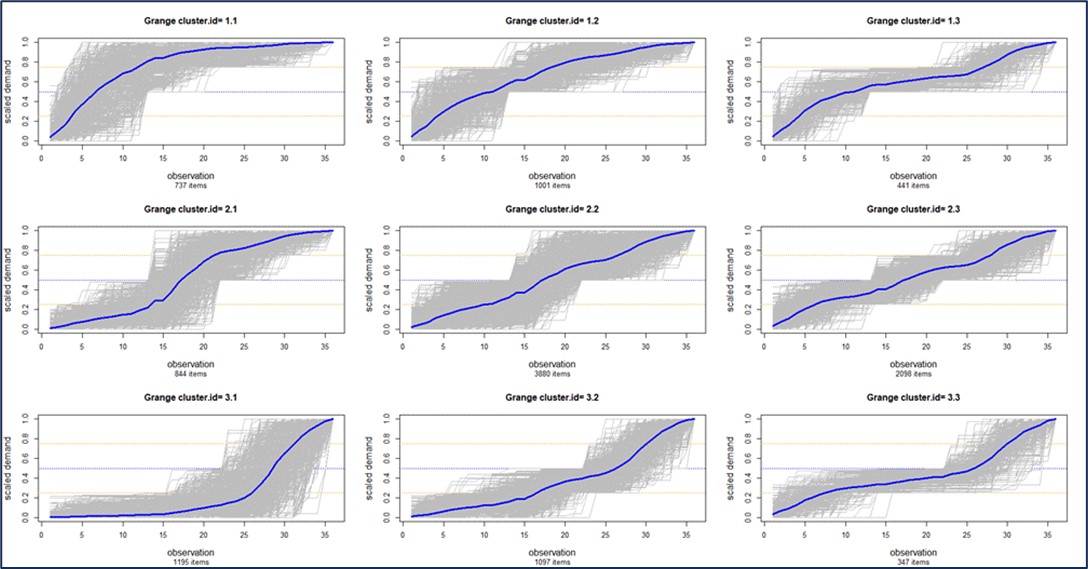
Figuur 1: Artikelen clusteren op basis van de vorm van hun cumulatieve vraag
Onregelmatigheidsdetectie
Vraagvoorspelling wordt traditioneel gedaan met behulp van tijdreeksextrapolatie. Eenvoudige exponentiële afvlakking werkt bijvoorbeeld om op elk moment het ‘midden’ van de vraagverdeling te vinden en dat niveau naar voren te projecteren. Als er in het recente verleden echter een plotselinge, eenmalige stijging of daling van de vraag heeft plaatsgevonden, kan die afwijkende waarde een aanzienlijk maar onwelkom effect hebben op de kortetermijnvoorspellingen. Net zo ernstig voor de voorraadplanning, kan de anomalie een buitensporig effect hebben op de schatting van de variabiliteit van de vraag, wat rechtstreeks doorgaat naar de berekening van de veiligheidsvoorraadvereisten.
Planners geven er misschien de voorkeur aan dergelijke afwijkingen op te sporen en te verwijderen (en misschien offline follow-up te doen om de reden voor de vreemdheid te achterhalen). Maar niemand die een grote klus te klaren heeft, zal duizenden vraagdiagrammen visueel willen scannen om uitschieters op te sporen, deze uit de vraaggeschiedenis te verwijderen en vervolgens alles opnieuw te berekenen. De menselijke intelligentie zou dat kunnen doen, maar het menselijk geduld zou spoedig ophouden. Algoritmen voor het detecteren van afwijkingen zouden het werk automatisch kunnen doen met behulp van relatief eenvoudige statistische methoden. Je zou dit ‘kunstmatige intelligentie’ kunnen noemen als je dat wilt.
Detectie van regimewijzigingen
Detectie van regimeveranderingen is als de grote broer van anomaliedetectie. Regimeverandering is een aanhoudende, in plaats van tijdelijke, verschuiving in een of meer aspecten van het karakter van een tijdreeks. Terwijl de detectie van afwijkingen zich gewoonlijk richt op plotselinge verschuivingen in de gemiddelde vraag, kan een regimeverandering verschuivingen in andere kenmerken van de vraag met zich meebrengen, zoals de volatiliteit of de verdelingsvorm ervan.
Figuur 2 illustreert een extreem voorbeeld van regimeverandering. Rond dag 120 daalde de vraag naar dit artikel op de bodem. Het voorraadbeheerbeleid en de vraagvoorspellingen op basis van de oudere gegevens zouden aan het einde van de vraaggeschiedenis enorm afwijken van de basis.
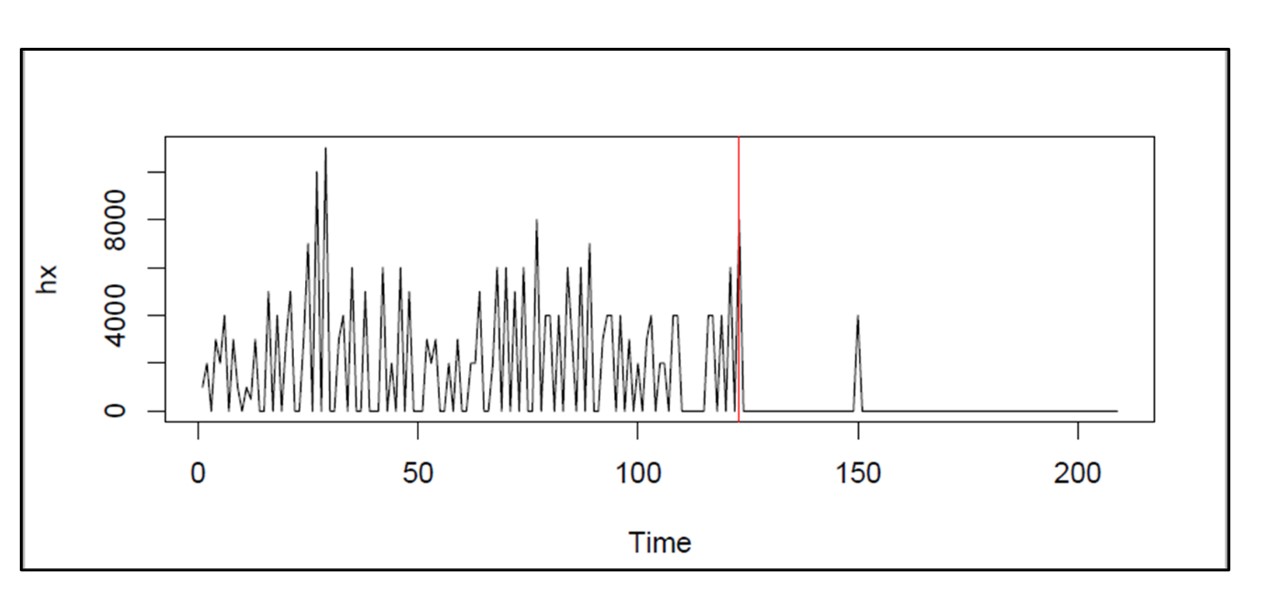
Figuur 2: Een voorbeeld van extreme regimeverandering in een artikel met een intermitterende vraag
Ook hier kunnen statistische algoritmen worden ontwikkeld om dit probleem op te lossen, en het zou eerlijk zijn om ze ‘machine learning’ of ‘kunstmatige intelligentie’ te noemen als ze daartoe gemotiveerd zijn. Door ML of AI te gebruiken om regimeveranderingen in de vraaggeschiedenis te identificeren, kan software voor vraagplanning automatisch alleen de relevante geschiedenis gebruiken bij het voorspellen, in plaats van handmatig de hoeveelheid geschiedenis te moeten kiezen die in het model moet worden geïntroduceerd.
Regressie analyse
Regressieanalyse relateert de ene variabele aan de andere via een vergelijking. De verkoop van kozijnen in één maand kan bijvoorbeeld worden voorspeld op basis van bouwvergunningen die een paar maanden eerder zijn afgegeven. Regressieanalyse wordt al meer dan een eeuw beschouwd als onderdeel van de statistiek, maar we kunnen zeggen dat het ‘machine learning’ is, aangezien een algoritme de precieze manier uitwerkt om kennis van de ene variabele om te zetten in een voorspelling van de waarde van een andere.
Overzicht
Het is redelijk om geïnteresseerd te zijn in wat er gebeurt op het gebied van machinaal leren en kunstmatige intelligentie. Hoewel de aandacht die aan ChatGPT en zijn concurrenten wordt besteed interessant is, is deze niet relevant voor de numerieke kant van vraagplanning of voorraadbeheer. De numerieke aspecten van ML en AI zijn potentieel relevant, maar je moet proberen de wolk van hype rond deze methoden te doorzien en je te concentreren op wat ze kunnen doen. Als u de klus kunt klaren met klassieke statistische methoden, kunt u dat misschien ook doen, en vervolgens uw optie uitoefenen om het ML-label op alles wat beweegt te plakken.

