Mensen die nieuw zijn in de functie van “vraagplanner” of “aanbodplanner” zullen waarschijnlijk vragen hebben over de verschillende prognosetermen en -methoden die in hun baan worden gebruikt. Deze notitie kan helpen door deze termen uit te leggen en te laten zien hoe ze verband houden.
Demand Planning
Vraagplanning gaat over hoeveel van wat u te verkopen heeft in de toekomst de deur uit zal gaan, bijvoorbeeld hoeveel wat niet u het volgende kwartaal zult verkopen. Hier volgen zes methodologieën die vaak worden gebruikt bij vraagplanning.
- Statistical Forecasting
- Deze methoden gebruiken de vraaggeschiedenis om toekomstige waarden te voorspellen. De twee meest gebruikelijke methoden zijn curve-fitting en data-afvlakking.
- Curve-aanpassing komt overeen met een eenvoudige wiskundige functie, zoals de vergelijking voor een rechte lijn (y= a +b∙t) of een rentecurve (y=a∙bT), naar de vraaggeschiedenis. Vervolgens breidt het die lijn of curve voorwaarts in de tijd uit als de voorspelling.
- Het gladmaken van gegevens resulteert daarentegen niet in een vergelijking. In plaats daarvan doorloopt het de geschiedenis van de vraag, waarbij gaandeweg de waarden worden gemiddeld, om een vloeiendere versie van de geschiedenis te creëren. Deze methoden worden exponentiële afvlakking en voortschrijdend gemiddelde genoemd. In het eenvoudigste geval (dat wil zeggen, bij afwezigheid van trends of seizoensinvloeden, waarvoor varianten bestaan), is het doel om het huidige gemiddelde vraagniveau te schatten en dat als voorspelling te gebruiken.
- Deze methoden produceren “puntvoorspellingen”, dit zijn schattingen op één getal voor elke toekomstige tijdsperiode (bijvoorbeeld: “De verkoop in maart zal 218 eenheden bedragen”). Soms komen ze met schattingen van potentiële voorspellingsfouten, die zijn gebaseerd op afzonderlijke modellen voor de variabiliteit van de vraag (“De verkoop in maart zal 218 ± 120 eenheden bedragen”).
- Probabilistic Forecasting
- Deze benadering maakt gebruik van de willekeur van de vraag en werkt hard om de prognoseonzekerheid in te schatten. Het beschouwt prognoses minder als een oefening in het verzamelen van specifieke cijfers en meer als een oefening in risicobeheer.
- Het modelleert expliciet de variabiliteit in de vraag en gebruikt die om resultaten te presenteren in de vorm van grote aantallen scenario's die zijn geconstrueerd om het volledige scala aan mogelijke vraagsequenties weer te geven. Deze zijn vooral handig bij taken op het gebied van tactische leveringsplanning, zoals het instellen van bestelpunten en bestelhoeveelheden.
- Causale voorspellingen
- Statistische voorspellingsmodellen gebruiken als input alleen de vraaggeschiedenis van het betreffende artikel in het verleden. Ze beschouwen de op en neer gaande bewegingen in het vraagdiagram als het eindresultaat van talloze niet nader genoemde factoren (rentetarieven, de prijs van thee in China, fasen van de maan, wat dan ook). Causale voorspellingen identificeren expliciet één of meer invloeden (rentetarieven, advertentie-uitgaven, prijzen van concurrenten, …) die op plausibele wijze de verkoop kunnen beïnvloeden. Vervolgens wordt een vergelijking opgesteld die de numerieke waarden van deze ‘drivers’ of ‘causale factoren’ relateert aan de verkoop van artikelen. De coëfficiënten van de vergelijking worden geschat door middel van “regressieanalyse”.
- Oordelende voorspellingen
- Gouden Darm. Ondanks de algemene beschikbaarheid van klodders data, besteden sommige bedrijven weinig aandacht aan de cijfers en hechten ze meer gewicht aan de subjectieve oordelen van een leidinggevende die wordt geacht een ‘Gouden Buik’ te hebben, waardoor hij of zij ‘onderbuikgevoel’ kan gebruiken om te voorspellen wat de toekomstige vraag zal zijn. Als die persoon veel ervaring heeft, een carrière lang naar de cijfers heeft gekeken en niet vatbaar is voor wensdenken of andere vormen van cognitieve vooringenomenheid, kan de Gouden Darm een goedkope, snelle manier van plannen zijn. Maar er zijn goede aanwijzingen uit studies van bedrijven die op deze manier worden uitgevoerd, dat vertrouwen op de Gouden Gut riskant is.
- Groepsconsensus. Vaker is een proces waarbij gebruik wordt gemaakt van een periodieke bijeenkomst om tot een groepsconsensusvoorspelling te komen. De groep zal toegang hebben tot gedeelde objectieve gegevens en voorspellingen, maar de leden zullen ook kennis hebben van factoren die mogelijk niet goed of helemaal niet worden gemeten, zoals het consumentenvertrouwen of de verhalen van verkopers. Het is nuttig om voor deze discussies een gedeeld, objectief uitgangspunt te hebben dat bestaat uit een soort objectieve statistische analyse. Vervolgens kan de groep overwegen om de statistische voorspelling aan te passen. Dit proces verankert de voorspelling in de objectieve realiteit, maar maakt gebruik van alle andere informatie die beschikbaar is buiten de voorspellingsdatabase.
- Scenariogeneratie. Soms ontmoeten meerdere mensen elkaar en bespreken ze ‘strategische wat-als’-vragen. “Wat als we onze Australische klanten verliezen?” “Wat als de uitrol van onze nieuwe producten met zes maanden wordt uitgesteld?” "Wat als onze verkoopmanager voor het Midden-Westen naar een concurrent springt?" Deze vragen over het grotere geheel kunnen implicaties hebben voor itemspecifieke prognoses en kunnen worden toegevoegd aan elke bijeenkomst over prognoses voor groepsconsensus.
- Prognose van nieuwe producten
- Nieuwe producten hebben per definitie geen verkoopgeschiedenis die statistische, waarschijnlijkheids- of causale voorspellingen ondersteunt. Hier kunnen altijd subjectieve voorspellingsmethoden worden gebruikt, maar deze berusten vaak op een gevaarlijke verhouding tussen hoop en feiten. Gelukkig bestaat er op zijn minst gedeeltelijke steun voor objectieve voorspellingen in de vorm van curve-fitting.
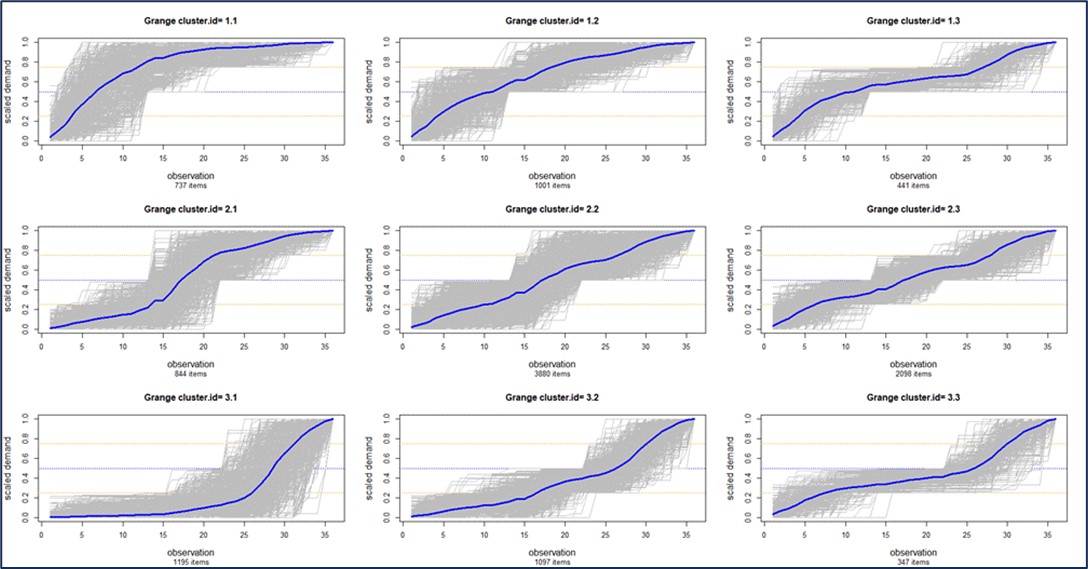
- Een grafiek van de cumulatieve verkoop van een artikel beschrijft vaak een soort “S-curve”, dat wil zeggen een grafiek die begint bij nul, zich opbouwt en vervolgens afvlakt tot de totale totale verkoop gedurende de uiteindelijke levensduur. De curve dankt zijn naam aan het feit dat hij lijkt op een letter S die op de een of andere manier naar rechts is uitgesmeerd en uitgerekt. Nu zijn er een oneindig aantal S-curves, dus voorspellers kiezen doorgaans een vergelijking en specificeren subjectief enkele belangrijke parameterwaarden, zoals wanneer de omzet 25%, 50% en 75% van de totale levenslange omzet zal bereiken en wat dat uiteindelijke niveau zal zijn. Dit is ook openlijk subjectief, maar het levert gedetailleerde voorspellingen per periode op die kunnen worden bijgewerkt naarmate de ervaring toeneemt. Ten slotte worden S-curven soms gevormd om overeen te komen met de bekende geschiedenis van een soortgelijk voorgangerproduct ("De verkoop voor onze laatste gizmo zag er zo uit, dus laten we dat als sjabloon gebruiken.").
Supply Planning
Vraagplanning wordt meegenomen in de aanbodplanning door toekomstige verkopen (bijvoorbeeld voor eindproducten) of gebruik (bijvoorbeeld voor reserveonderdelen) te voorspellen. Vervolgens is het aan de leveringsplanning om ervoor te zorgen dat de betreffende artikelen beschikbaar zijn voor verkoop of gebruik.
- Afhankelijke vraag
- Afhankelijke vraag is de vraag die kan worden bepaald door de relatie ervan met de vraag naar een ander artikel. Uit een stuklijst kan bijvoorbeeld blijken dat een rood wagentje bestaat uit een carrosserie, een trekstang, vier wielen, twee assen en diverse bevestigingsmiddelen om de wielen op de assen te houden en de trekstang met de carrosserie te verbinden. Dus als je 10 kleine rode wagons hoopt te verkopen, kun je er beter 10 maken, wat betekent dat je 10×2 = 20 assen, 10×4 = 40 wielen, enz. nodig hebt. De afhankelijke vraag regelt de aankoop van grondstoffen, de aankoop van componenten en subsystemen, zelfs personeel inhuren (voor 10 wagons is één middelbare scholier nodig om ze in een dienst van een uur in elkaar te zetten).
- Als u meerdere producten heeft met gedeeltelijk overlappende stuklijsten, heeft u de keuze uit twee prognosebenaderingen. Stel dat u niet alleen kleine rode wagentjes verkoopt, maar ook kleine blauwe kinderwagens, die allebei dezelfde assen gebruiken. Om het aantal assen te voorspellen dat u nodig heeft, kunt u (1) de afhankelijke vraag naar assen van elk product voorspellen en de prognoses toevoegen, of (2) de totale vraaggeschiedenis naar assen als zijn eigen tijdreeks bekijken en die afzonderlijk voorspellen. Wat beter werkt, is een empirische vraag die kan worden getest.
- Voorraadbeheer
- Voorraadbeheer omvat veel verschillende taken. Deze omvatten het instellen van parameters voor voorraadbeheer, zoals bestelpunten en bestelhoeveelheden, het reageren op onvoorziene omstandigheden zoals voorraadtekorten en het versnellen van bestellingen, het instellen van personeelsbezetting en het selecteren van leveranciers.
- Bij de eerste drie speelt forecasting een rol. Het aantal aanvulbestellingen dat in een jaar voor elk product wordt gedaan, bepaalt hoeveel mensen er nodig zijn om inkooporders te verlagen. Het aantal en de ernst van stockouts in een jaar bepalen het aantal onvoorziene gebeurtenissen dat moet worden afgehandeld. Het aantal inkooporders en stockouts in een jaar zal willekeurig zijn, maar wordt bepaald door de keuze van de parameters voor voorraadbeheer. De implicaties van dergelijke keuzes kunnen worden gemodelleerd door inventarissimulaties. Deze simulaties zullen worden aangestuurd door gedetailleerde vraagscenario's die worden gegenereerd door probabilistische voorspellingen.