Veel bedrijven die hun prognoseproces willen verbeteren, weten niet waar ze moeten beginnen. Het kan verwarrend zijn om te worstelen met het leren van nieuwe statistische methoden, ervoor zorgen dat gegevens correct zijn gestructureerd en bijgewerkt, het eens worden over wie "eigenaar" is van de prognose, definiëren wat eigendom betekent en meetnauwkeurigheid. Na meer dan veertig jaar oefenen hebben we deze blog geschreven om de belangrijkste focus te schetsen en om u aan te moedigen om het in het begin simpel te houden.
1. Objectiviteit. Begrijp en communiceer eerst dat het proces van vraagplanning en -prognose een oefening in objectiviteit is. De focus ligt op het verkrijgen van input uit verschillende bronnen (stakeholders, klanten, functioneel beheerders, databases, leveranciers, enz.) en het bepalen of die input waarde toevoegt. Als u bijvoorbeeld een statistische prognose overschrijft en 20% aan de projectie toevoegt, moet u er niet zomaar van uitgaan dat u het automatisch goed had. Wees in plaats daarvan objectief en controleer of die opheffing de prognosenauwkeurigheid heeft vergroot of verkleind. Als u merkt dat uw overrides de zaken erger hebben gemaakt, heeft u iets gewonnen: dit informeert het proces en u weet dat u in de toekomst override-beslissingen beter kunt onderzoeken.
2. Teamwerk. Erken dat prognoses en vraagplanning teamsporten zijn. Maak afspraken over wie het team zal aanvoeren. De kapitein is verantwoordelijk voor het maken van de statistische basisprognoses en het toezicht houden op het vraagplanningsproces. Maar de resultaten zijn afhankelijk van het feit of iedereen in het team een positieve bijdrage levert, gegevens verstrekt, alternatieve methoden voorstelt, aannames in twijfel trekt en aanbevolen acties uitvoert. De uiteindelijke resultaten zijn eigendom van het bedrijf en elke afzonderlijke belanghebbende.
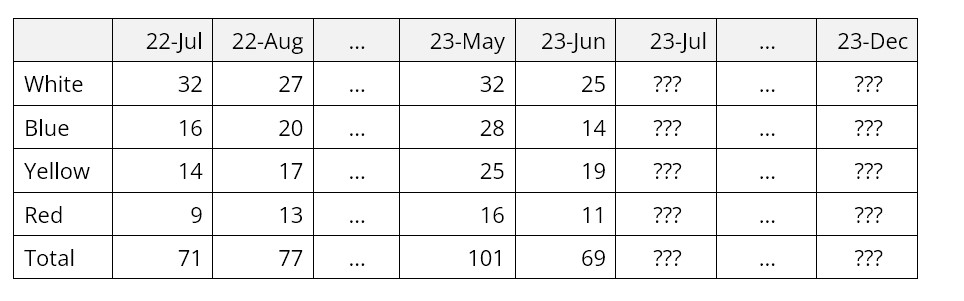
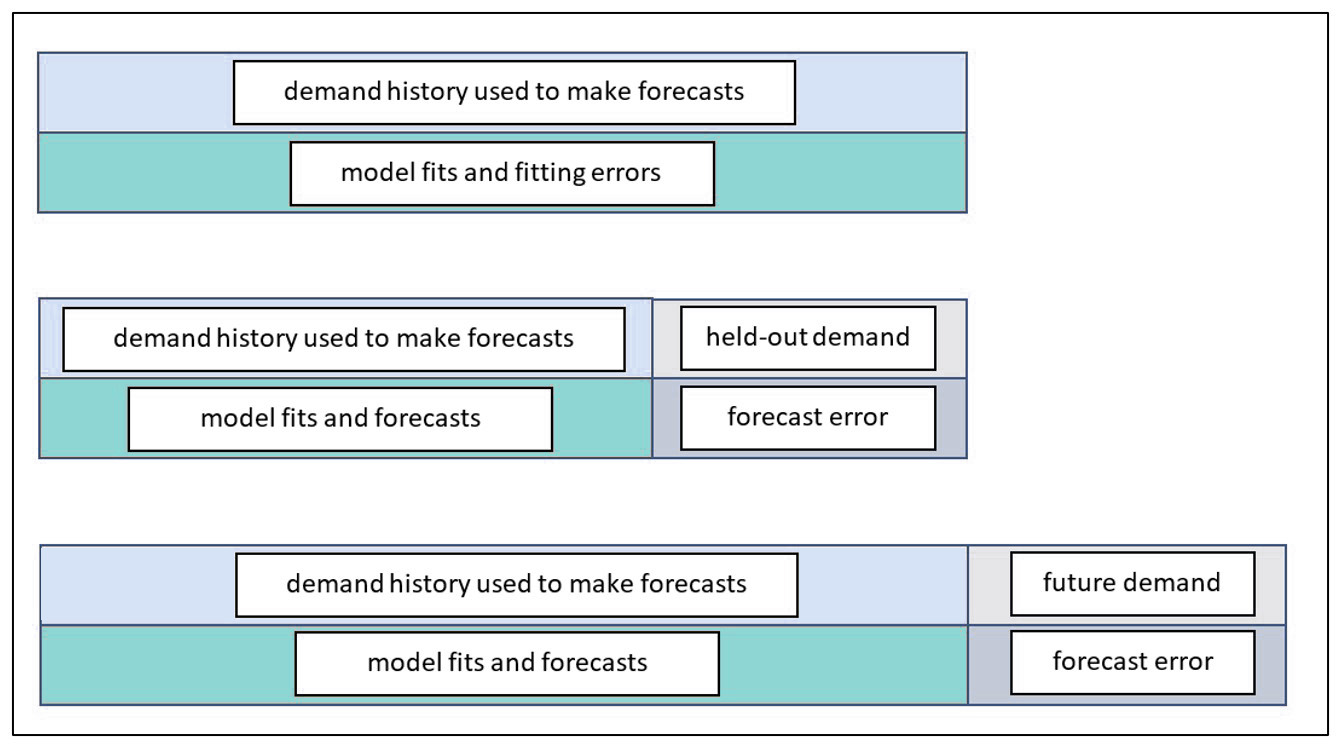
3. Meting. Fixeer u niet op benchmarks voor de nauwkeurigheid van prognoses in de branche. Elke SKU heeft zijn eigen niveau van "voorspelbaarheid", en u kunt een aantal moeilijke items beheren. Creëer in plaats daarvan uw eigen benchmarks op basis van een reeks steeds geavanceerdere prognosemethoden. Geavanceerde statistische prognoses lijken in het begin misschien ontmoedigend ingewikkeld, dus begin eenvoudig met een basismethode, zoals het voorspellen van de historische gemiddelde vraag. Meet vervolgens hoe dicht die simpele voorspelling de werkelijk waargenomen vraag benadert. Werk van daaruit verder naar technieken die te maken hebben met complicaties zoals trend en seizoensinvloeden. Meet de voortgang met behulp van nauwkeurigheidsstatistieken die door uw software zijn berekend, zoals de gemiddelde absolute procentuele fout (MAPE). Hierdoor kan uw bedrijf elke prognosecyclus een beetje beter worden.
4. Tempo. Richt u vervolgens op het maken van prognoses tot een op zichzelf staand proces dat niet wordt gecombineerd met het complexe proces van voorraadoptimalisatie. Voorraadbeheer is gebaseerd op een solide vraagvoorspelling, maar is gericht op andere onderwerpen: wat te kopen, wanneer te kopen, minimale bestelhoeveelheden, veiligheidsvoorraden, voorraadniveaus, doorlooptijden van leveranciers, enz. Laat voorraadbeheer later verder gaan . Bouw eerst "voorspellingskracht" op door het voorspellingsproces te creëren, te herzien en te ontwikkelen om een regelmatige cadans te hebben. Wanneer uw proces voldoende volwassen is, kunt u de toenemende snelheid van het bedrijfsleven bijbenen door het tempo van uw prognoseproces te verhogen tot ten minste een maandelijks tempo.
Opmerkingen
Het herzien van het prognoseproces van een bedrijf kan een grote stap zijn. Soms gebeurt het als er personeelsverloop is, soms als er een nieuw ERP-systeem is, soms als er nieuwe prognosesoftware is. Wat de overhaaste gebeurtenis ook is, deze verandering is een kans om het proces dat je eerder had te heroverwegen en te verfijnen. Maar proberen de hele olifant in één keer op te eten is een vergissing. In deze blog hebben we enkele discrete stappen uiteengezet die u kunt nemen om een succesvolle evolutie naar een beter prognoseproces te maken.