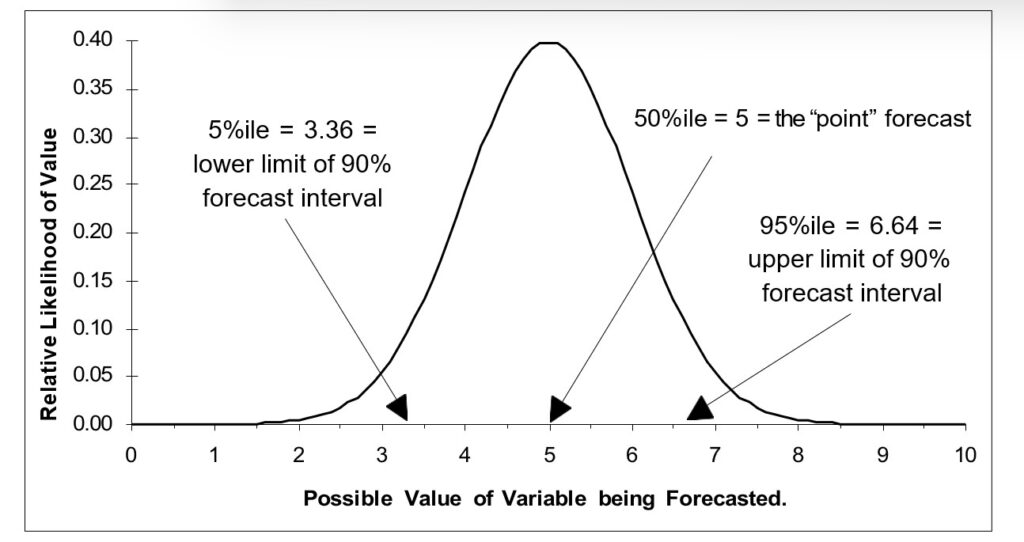
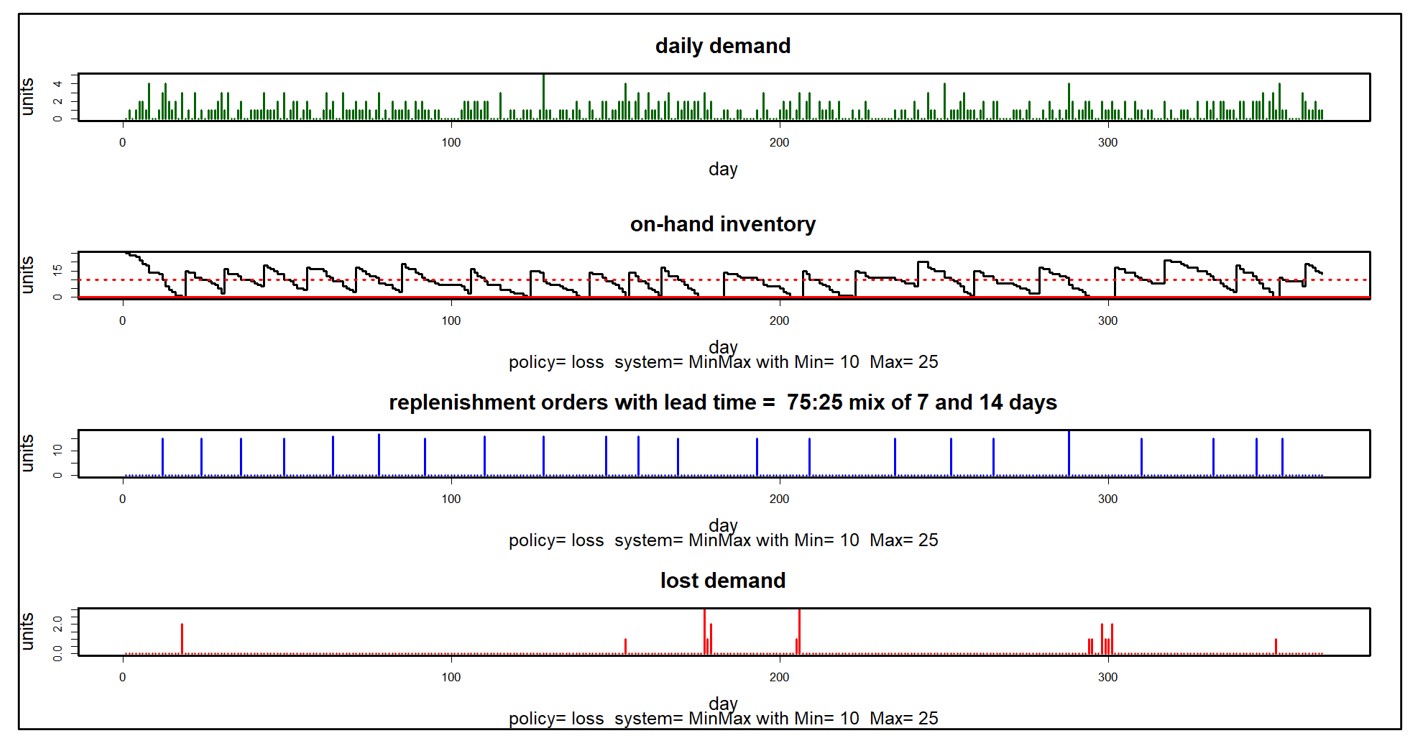
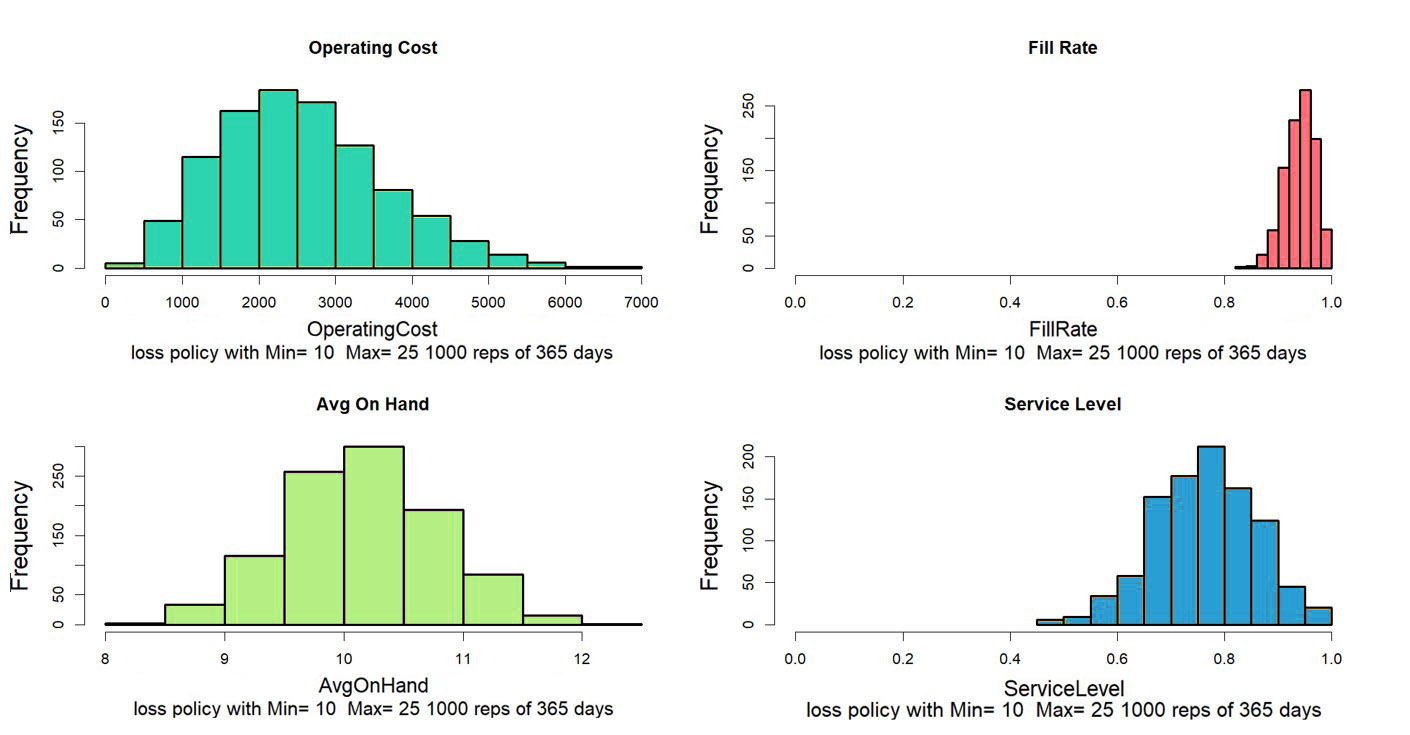
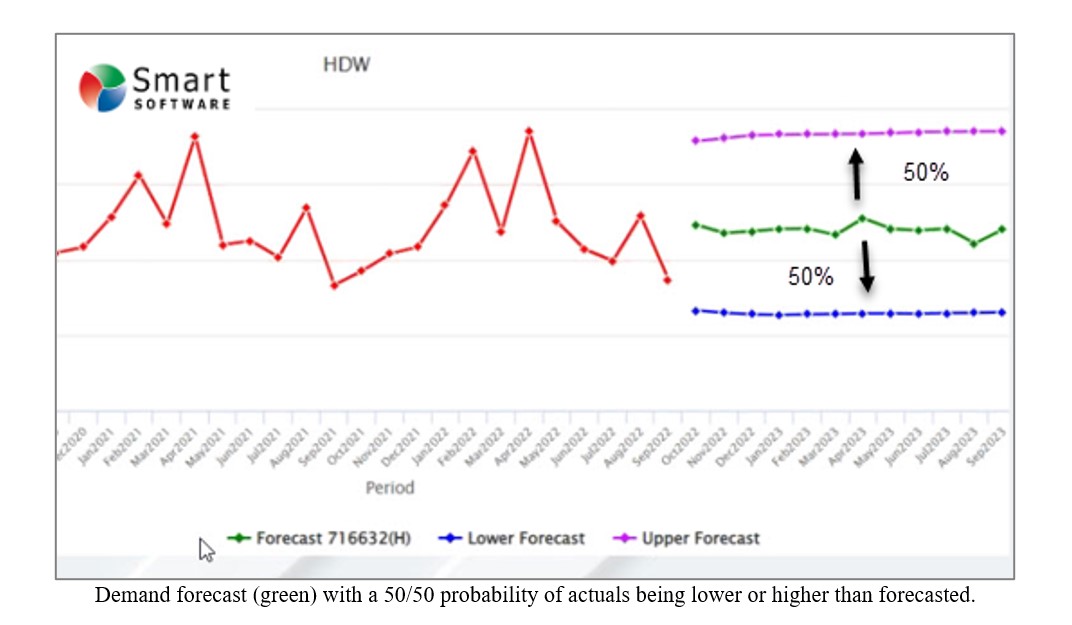
Op elk gebied, inclusief voorspellingen, wordt volkswijsheid verzameld die zich uiteindelijk voordoet als ‘best practices’. Deze best practices zijn vaak verstandig, althans gedeeltelijk, maar missen vaak context en zijn mogelijk niet geschikt voor bepaalde klanten, sectoren of bedrijfssituaties. Er zit vaak een addertje onder het gras: een ‘ja, maar’. Deze opmerking gaat over zes doorgaans juiste voorspellingen, die niettemin hun kanttekeningen plaatsen.
- Organiseer uw bedrijf rond een prognose van één getal. Dat klinkt verstandig: het is goed om een gedeelde visie te hebben. Maar elk onderdeel van het bedrijf zal zijn eigen idee hebben over welk getal het getal is. De financiële sector wil misschien kwartaalomzet, de marketing wil misschien websitebezoeken, de verkoop wil misschien een verloop, het onderhoud wil misschien een langere tijd tot het misgaat. Overigens heeft elke eenheid waarschijnlijk een handvol belangrijke statistieken. U heeft geen slogan nodig, u moet uw werk gedaan krijgen.
- Integreer bedrijfskennis in een gezamenlijk prognoseproces. Dit is een goede algemene regel, maar als uw samenwerkingsproces gebrekkig is, kan het knoeien met een statistische prognose via managementoverschrijvingen de nauwkeurigheid verminderen. Je hebt geen slogan nodig; je moet de nauwkeurigheid van alle methoden meten en vergelijken en de winnaars volgen.
- Voorspelling met behulp van causale modellering. Extrapolatieve prognosemethoden houden geen rekening met de onderliggende krachten die uw verkopen aandrijven, ze werken alleen met de resultaten. Causale modellering brengt u dieper in de fundamentele drijfveren en kan zowel de nauwkeurigheid als het inzicht verbeteren. Causale modellen (geïmplementeerd door middel van regressieanalyse) kunnen echter minder nauwkeurig zijn, vooral als ze voorspellingen van de drijvende krachten vereisen (“voorspellingen van de voorspellers”) in plaats van simpelweg de geregistreerde waarden van vertraagde voorspellende variabelen in te pluggen. Je hebt geen slogan nodig: je hebt een onderlinge vergelijking nodig.
- Voorspel de vraag in plaats van verzendingen. Vraag is wat je echt wilt, maar het ‘opstellen van een vraagsignaal’ kan lastig zijn: wat doe je met interne overboekingen? Eenmalige? Verloren omzet? Bovendien kunnen vraaggegevens worden gemanipuleerd. Als klanten bijvoorbeeld opzettelijk geen bestellingen plaatsen of proberen hun bestellingen te misleiden door te lang van tevoren te bestellen, zal de bestelgeschiedenis niet beter zijn dan de verzendgeschiedenis. Althans met verzendgeschiedenis, het klopt: u weet wat u heeft verzonden. Prognoses van verzendingen zijn geen voorspellingen van de ‘vraag’, maar vormen een solide uitgangspunt.
- Gebruik Machine Learning-methoden. Ten eerste is ‘Machine learning’ een elastisch concept dat een steeds groter aantal alternatieven omvat. Onder de motorkap van veel door ML geadverteerde modellen bevindt zich slechts een automatisch kiezen een extrapolatieve voorspellingsmethode (dat wil zeggen: de beste pasvorm) die, hoewel uitstekend in het voorspellen van de normale vraag, al bestaat sinds de jaren tachtig (Smart Software was het eerste bedrijf dat een automatische selectiemethode voor de pc uitbracht). ML-modellen zijn data-hogs die grotere datasets nodig hebben dan u mogelijk ter beschikking heeft. Het op de juiste manier kiezen en trainen van een ML-model vereist een niveau van statistische expertise dat ongebruikelijk is in veel productie- en distributiebedrijven. Misschien wil je iemand vinden die je hand vasthoudt voordat je dit spel gaat spelen.
- Door uitschieters te verwijderen, ontstaan betere voorspellingen. Hoewel het waar is dat zeer ongebruikelijke pieken of dalen in de vraag onderliggende vraagpatronen, zoals trends of seizoensinvloeden, zullen maskeren, is het niet altijd waar dat u de pieken moet wegnemen. Vaak weerspiegelen deze pieken in de vraag de onzekerheid die willekeurig uw bedrijfsvoering kan verstoren en waarmee dus rekening moet worden gehouden. Het verwijderen van dit soort gegevens uit uw vraagvoorspellingsmodel kan de gegevens op papier voorspelbaarder maken, maar u zult verrast zijn als dit opnieuw gebeurt. Wees dus voorzichtig met het verwijderen van uitschieters massaal.