Software voor vraagplanning en statistische prognoses speelt een cruciale rol in effectief bedrijfsbeheer door functies te integreren die de nauwkeurigheid van prognoses aanzienlijk verbeteren. Een belangrijk aspect is het gebruik van op afvlakking gebaseerde of extrapolatieve modellen, waardoor bedrijven snel voorspellingen kunnen doen die uitsluitend op historische gegevens zijn gebaseerd. Deze basis, geworteld in prestaties uit het verleden, is cruciaal voor het begrijpen van trends en patronen, vooral in variabelen zoals verkoop of productvraag. Voorspellingssoftware gaat verder dan louter data-analyse door de combinatie van professioneel oordeel met statistische voorspellingen mogelijk te maken, waarbij wordt erkend dat prognoses geen one-size-fits-all proces zijn. Deze flexibiliteit stelt bedrijven in staat menselijke inzichten en sectorkennis in het voorspellingsmodel op te nemen, waardoor een genuanceerdere en nauwkeurigere voorspelling wordt gegarandeerd.
Functies zoals het voorspellen van meerdere artikelen als groep, het rekening houden met promotiegestuurde vraag en het omgaan met intermitterende vraagpatronen zijn essentiële mogelijkheden voor bedrijven die te maken hebben met uiteenlopende productportfolio's en dynamische marktomstandigheden. Een juiste implementatie van deze toepassingen geeft bedrijven de beschikking over veelzijdige prognosetools, die aanzienlijk bijdragen aan geïnformeerde besluitvorming en operationele efficiëntie.
Extrapolatieve modellen
Onze oplossingen voor vraagvoorspelling ondersteunen een verscheidenheid aan voorspellingsbenaderingen, waaronder extrapolatieve of op afvlakking gebaseerde voorspellingsmodellen, zoals exponentiële afvlakking en voortschrijdende gemiddelden. De filosofie achter deze modellen is eenvoudig: ze proberen zich herhalende patronen in de historische gegevens te detecteren, kwantificeren en in de toekomst te projecteren.
Er zijn twee soorten patronen die in de historische gegevens kunnen worden aangetroffen:
- Trend
- Seizoensgebondenheid
Deze patronen worden in de volgende afbeelding geïllustreerd, samen met willekeurige gegevens.
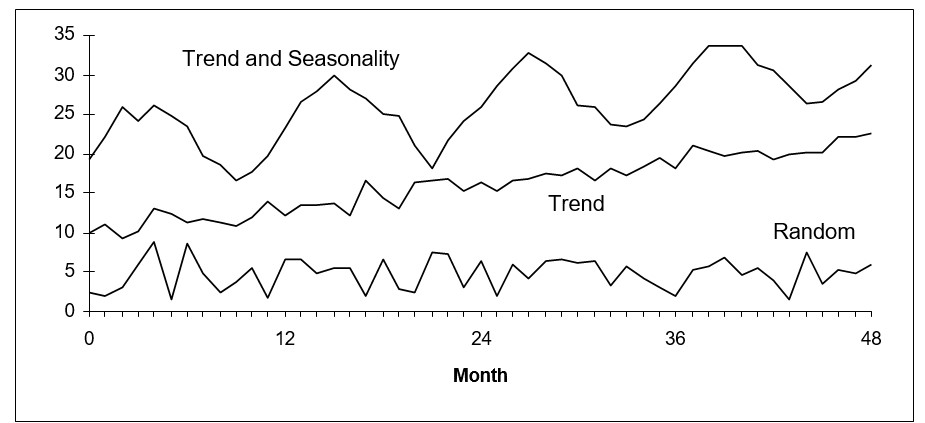
Ter illustratie van trend-, seizoens- en willekeurige tijdreeksgegevens
Als het patroon een trend is, schatten extrapolatieve modellen zoals dubbele exponentiële afvlakking en lineair voortschrijdend gemiddelde het tempo van de stijging of daling van het niveau van de variabele en projecteren dat tempo naar de toekomst.
Als het patroon seizoensgebonden is, schatten modellen zoals Winters en drievoudige exponentiële afvlakking seizoensvermenigvuldigers of seizoensgebonden optellingsfactoren en passen deze vervolgens toe op projecties van het niet-seizoensgebonden deel van de gegevens.
Heel vaak, vooral bij gegevens over detailhandelsverkopen, zijn zowel trend- als seizoenspatronen betrokken. Als deze patronen stabiel zijn, kunnen ze worden benut om zeer nauwkeurige voorspellingen te doen.
Soms zijn er echter geen duidelijke patronen, zodat de plots van de gegevens op willekeurige ruis lijken. Soms zijn patronen duidelijk zichtbaar, maar ze veranderen in de loop van de tijd en er kan niet op worden vertrouwd dat ze zich herhalen. In deze gevallen proberen de extrapolatieve modellen geen patronen te kwantificeren en te projecteren. In plaats daarvan proberen ze de ruis te middelen en goede schattingen te maken van het midden van de verdeling van gegevenswaarden. Deze typische waarden worden dan de voorspellingen. Wanneer gebruikers een historisch plot met veel ups en downs zien, maken ze zich soms zorgen omdat de voorspelling deze ups en downs niet repliceert. Normaal gesproken hoeft dit geen reden tot bezorgdheid te zijn. Dit gebeurt wanneer de historische patronen niet sterk genoeg zijn om het gebruik van een voorspellingsmethode te rechtvaardigen die het patroon repliceert. U wilt er zeker van zijn dat uw prognoses niet lijden onder het “wiebeleffect” dat hierin wordt beschreven blogpost.
Het verleden als voorspeller van de toekomst
De belangrijkste aanname die inherent is aan extrapolatieve modellen is dat het verleden een goede leidraad is voor de toekomst. Deze veronderstelling kan echter mislukken. Sommige historische gegevens kunnen verouderd zijn. De gegevens kunnen bijvoorbeeld een bedrijfsomgeving beschrijven die niet meer bestaat. Of de wereld die het model vertegenwoordigt, kan binnenkort veranderen, waardoor alle gegevens overbodig worden. Vanwege dergelijke complicerende factoren zijn de risico's van extrapolatieve voorspellingen kleiner als er slechts korte tijd in de toekomst wordt voorspeld.
Extrapolatieve modellen hebben het praktische voordeel dat ze goedkoop zijn en gemakkelijk te bouwen, te onderhouden en te gebruiken. Ze vereisen alleen nauwkeurige registraties van waarden uit het verleden van de variabelen die u moet voorspellen. Naarmate de tijd verstrijkt, voegt u eenvoudigweg de nieuwste gegevenspunten toe aan de tijdreeks en maakt u een nieuwe voorspelling. De hieronder beschreven causale modellen vereisen daarentegen meer denkwerk en meer gegevens. De eenvoud van extrapolatieve modellen wordt het meest op prijs gesteld als u met een enorm voorspellingsprobleem kampt, zoals het maken van nachtelijke prognoses van de vraag naar alle 30.000 artikelen die in een magazijn op voorraad zijn.
Oordelende aanpassingen
Extrapolatieve modellen kunnen met Demand Planner volledig automatisch worden uitgevoerd, zonder dat tussenkomst vereist is. Causale modellen vereisen inhoudelijk oordeel voor een verstandige selectie van onafhankelijke variabelen. Beide soorten statistische modellen kunnen echter worden verbeterd door oordelende aanpassingen. Beiden kunnen profiteren van uw inzichten.
Zowel causale als extrapolatieve modellen zijn gebaseerd op historische gegevens. Het is echter mogelijk dat u over aanvullende informatie beschikt die niet wordt weerspiegeld in de cijfers in het historische record. U weet bijvoorbeeld misschien dat de concurrentieomstandigheden binnenkort zullen veranderen, misschien als gevolg van prijskortingen of trends in de sector, of de opkomst van nieuwe concurrenten, of de aankondiging van een nieuwe generatie van uw eigen producten. Als deze gebeurtenissen plaatsvinden tijdens de periode waarvoor u voorspellingen doet, kunnen ze de nauwkeurigheid van puur statistische voorspellingen aantasten. Met de grafische aanpassingsfunctie van Smart Demand Planner kunt u deze extra factoren in uw prognoses opnemen via het proces van grafische aanpassing op het scherm.
Houd er rekening mee dat het toepassen van gebruikersaanpassingen op de prognose een tweesnijdend zwaard is. Als het op de juiste manier wordt gebruikt, kan het de nauwkeurigheid van voorspellingen verbeteren door gebruik te maken van een rijkere reeks informatie. Als het promiscue wordt gebruikt, kan het extra ruis aan het proces toevoegen en de nauwkeurigheid verminderen. Wij raden u aan spaarzaam om te gaan met oordelende aanpassingen, maar nooit blindelings de voorspellingen van een puur statistische voorspellingsmethode te aanvaarden. Het is ook erg belangrijk om de verwachte toegevoegde waarde te meten. Dat wil zeggen de waarde die door elke incrementele stap aan het prognoseproces wordt toegevoegd. Als u bijvoorbeeld aanpassingen toepast op basis van bedrijfskennis, is het belangrijk om te meten of deze aanpassingen waarde toevoegen door de nauwkeurigheid van de prognoses te verbeteren. Smart Demand Planner ondersteunt het meten van de verwachte toegevoegde waarde door elke overwogen prognose bij te houden en de nauwkeurigheidsrapporten van de prognoses te automatiseren. U kunt statistische prognoses selecteren, de fouten ervan meten en deze vergelijken met de overschreven voorspellingen. Door dit te doen informeert u het prognoseproces, zodat in de toekomst betere beslissingen kunnen worden genomen.
Voorspellingen op meerdere niveaus
Een andere veel voorkomende situatie betreft prognoses op meerdere niveaus, waarbij er meerdere items als groep worden voorspeld of er zelfs meerdere groepen kunnen zijn, waarbij elke groep meerdere items bevat. We zullen dit soort prognoses over het algemeen Multilevel Forecasting noemen. Het belangrijkste voorbeeld is de productlijnprognose, waarbij elk artikel lid is van een artikelfamilie en het totaal van alle artikelen in de familie een betekenisvolle hoeveelheid is.
U heeft bijvoorbeeld, zoals in de volgende afbeelding, mogelijk een lijn tractoren en u wilt verkoopprognoses voor elk type tractor en voor de gehele tractorlijn.
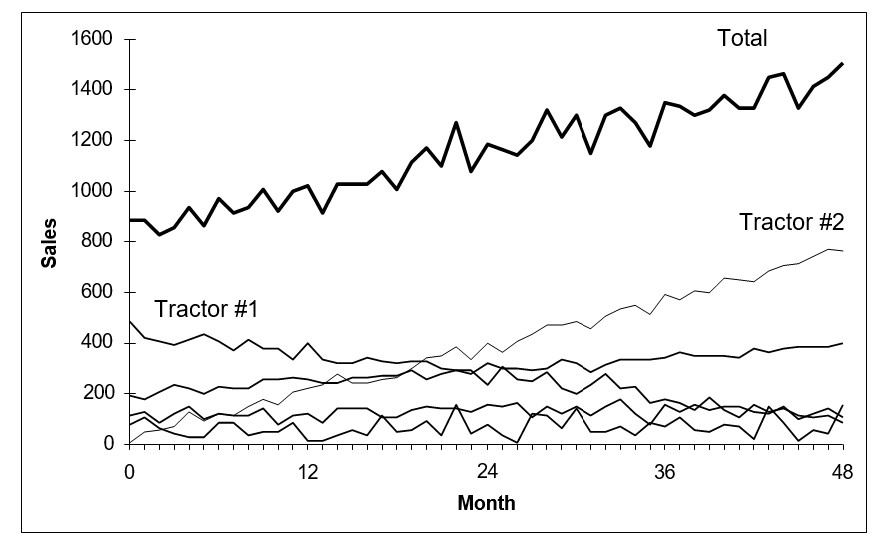
Ter illustratie van productprognoses op meerdere niveaus
Smart Demand Planner biedt roll-up/roll-down-prognoses. Deze functie is cruciaal voor het verkrijgen van uitgebreide prognoses van alle productartikelen en hun groepstotaal. De Roll Down/Roll Up-methode binnen deze functie biedt twee opties voor het verkrijgen van deze prognoses:
Samenvatten (Bottom-Up): Deze optie voorspelt in eerste instantie elk item afzonderlijk en voegt vervolgens de prognoses op itemniveau samen om een prognose op familieniveau te genereren.
Roll-down (van boven naar beneden): Als alternatief begint de roll-down-optie met het vormen van het historische totaal op familieniveau, voorspelt het en wijst het totaal vervolgens proportioneel toe tot op itemniveau.
Wanneer u Roll Down/Roll Up gebruikt, heeft u toegang tot het volledige scala aan prognosemethoden van Smart Demand Planner, zowel op artikel- als op familieniveau. Dit zorgt voor flexibiliteit en nauwkeurigheid bij het voorspellen, waarbij wordt voldaan aan de specifieke behoeften van uw bedrijf op verschillende hiërarchische niveaus.
Onderzoek naar prognoses heeft geen duidelijke voorwaarden geschapen die de voorkeur geven aan een top-down- of bottom-up-benadering van prognoses. De bottom-up benadering lijkt echter de voorkeur te hebben als de geschiedenis van items stabiel is en de nadruk ligt op de trends en seizoenspatronen van de individuele items. Top-down is normaal gesproken een betere keuze als sommige items een zeer luidruchtige geschiedenis hebben of als de nadruk ligt op prognoses op groepsniveau. Omdat Smart Demand Planner het snel en gemakkelijk maakt om zowel een bottom-up als een top-down benadering te proberen, moet u beide methoden proberen en de resultaten vergelijken. U kunt de functie 'Hold back on Current' van Smart Demand Planner in 'Prognose vs. Actueel' gebruiken om beide benaderingen op uw eigen gegevens te testen en te zien welke een nauwkeurigere voorspelling voor uw bedrijf oplevert.

