Ruim veertig jaar geleden bestond Smart Software uit drie vrienden die in de kelder van een kerk een bedrijf begonnen te starten. Tegenwoordig is ons team uitgebreid en opereert vanuit meerdere locaties in Massachusetts, New Hampshire en Texas, met teamleden in Engeland, Spanje, Armenië en India. Net als velen van u in uw functie hebben wij manieren gevonden om gedistribueerde teams voor ons en voor u te laten werken.
Deze notitie gaat over een ander soort teamwerk: de samenwerking tussen u en onze software die binnen handbereik plaatsvindt. Ik schrijf vaak over de software zelf en wat er ‘onder de motorkap’ gebeurt. Deze keer is mijn onderwerp hoe je het beste met de software kunt samenwerken.
Onze softwaresuite, Smart Inventory Planning and Optimization (Smart IP&O™) is in staat tot zeer gedetailleerde berekeningen van de toekomstige vraag en de voorraadcontroleparameters (bijvoorbeeld bestelpunten en bestelhoeveelheden) die die vraag het meest effectief zouden beheren. Maar om al die kracht optimaal te kunnen benutten, is uw inbreng nodig. Je moet samenwerken met de algoritmen.
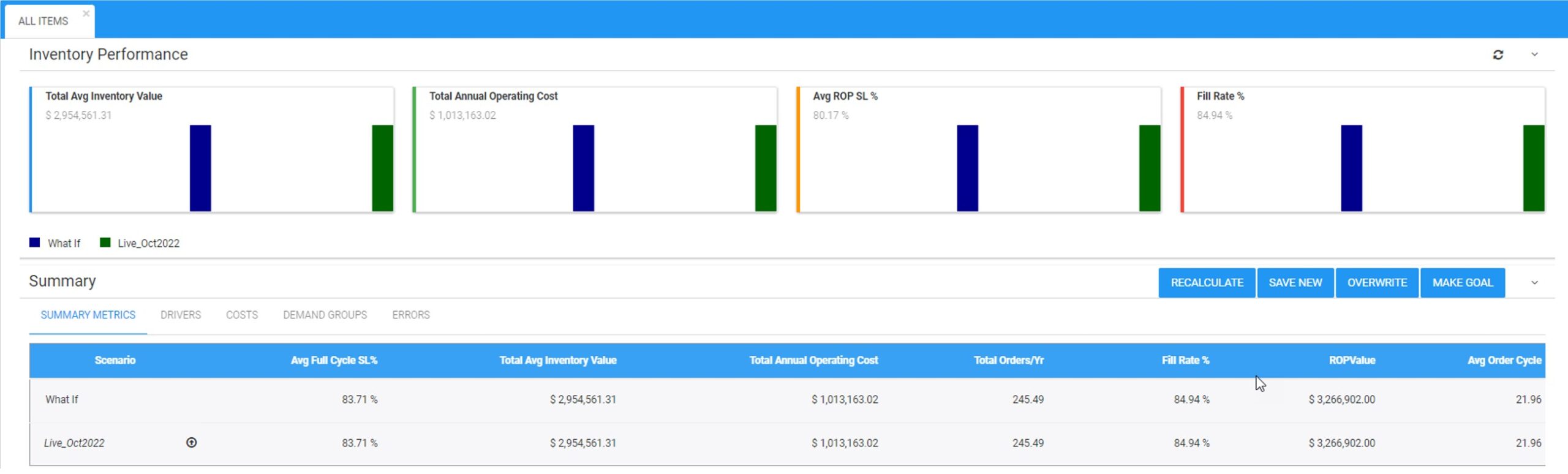
Die interactie kan verschillende vormen aannemen. U kunt beginnen door simpelweg te beoordelen hoe het nu met u gaat. De rapportschrijffuncties in Smart IP&O (Smart Operational Analytics™) kunnen al uw transactiegegevens verzamelen en analyseren om uw Key Performance Indicators (KPI's) te meten, zowel financieel (bijvoorbeeld voorraadinvesteringen) als operationeel (bijvoorbeeld opvullingspercentages).
De volgende stap zou kunnen zijn om SIO (Smart Inventory Optimization™), de inventarisanalyse binnen SIP&O, te gebruiken om ‘wat-als’-spelletjes met de software te spelen. U kunt zich bijvoorbeeld afvragen: 'Wat als we de bestelhoeveelheid voor artikel 1234 verlagen van 50 naar 40?' De software vermaalt de cijfers om u te laten weten hoe dat zou uitpakken, waarna u reageert. Dit kan handig zijn, maar wat als u 50.000 items moet overwegen? Je zou wat-als-spellen willen doen voor een paar cruciale items, maar niet voor allemaal.
De echte kracht zit hem in het gebruik van de automatische optimalisatiemogelijkheden in SIO. Hier kunt u op grote schaal samenwerken met de algoritmen. Op basis van uw zakelijke oordeel kunt u “groepen” creëren, dat wil zeggen verzamelingen van items die enkele cruciale kenmerken gemeen hebben. U kunt bijvoorbeeld een groep maken voor 'kritieke reserveonderdelen voor klanten van elektriciteitsbedrijven', bestaande uit 1.200 onderdelen. Vervolgens kunt u, opnieuw op basis van uw zakelijk oordeel, specificeren welke standaard voor de beschikbaarheid van artikelen moet gelden voor alle artikelen in die groep (bijvoorbeeld: “minstens 95% kans dat de voorraad binnen een jaar niet op voorraad is”). Nu kan de software het overnemen en automatisch de beste bestelpunten en bestelhoeveelheden voor elk van deze artikelen berekenen om de gewenste artikelbeschikbaarheid tegen de laagst mogelijke totale kosten te bereiken. En dat, beste lezer, is krachtig teamwerk.