Wordt veiligheidsvoorraad beschouwd als noodreserve of als dagelijkse buffer tegen pieken in de vraag? Het verschil kennen en uw ERP correct configureren, zal een groot verschil maken voor uw bedrijfsresultaten.
De Safety Stock veld in je ERP systeem kan heel verschillende dingen betekenen, afhankelijk van de configuratie. Het niet begrijpen van deze verschillen en hoe ze uw winst beïnvloeden, is een veelvoorkomend probleem dat we hebben gezien bij implementaties van onze software.
Het implementeren van software voor voorraadoptimalisatie begint met nieuwe klanten die de technische implementatie voltooien om de gegevensstroom op gang te brengen. Vervolgens krijgen ze gebruikerstraining en besteden ze weken aan het zorgvuldig configureren van hun initiële veiligheidsvoorraden, bestelniveaus en consensusvraagprognoses met Smart IP&O. Het team raakt vertrouwd met Smart's Key Performance Forecasts (KPP's) voor serviceniveaus, bestelkosten en beschikbare voorraad, die allemaal worden voorspeld met behulp van het nieuwe voorraadbeleid.
Maar wanneer ze het beleid en de prognoses opslaan in hun ERP-testsysteem, zijn de voorgestelde bestellingen soms veel groter en komen ze vaker voor dan ze hadden verwacht, wat de verwachte voorraadkosten opdrijft.
Wanneer dit gebeurt, is de primaire boosdoener de manier waarop het ERP is geconfigureerd om veiligheidsvoorraad te behandelen. Door op de hoogte te zijn van deze configuratie-instellingen kunnen planningsteams de verwachtingen beter stellen en de verwachte resultaten bereiken met minder inspanning (en reden tot ongerustheid!).
Dit zijn de drie veelvoorkomende voorbeelden van configuraties van ERP-veiligheidsvoorraden:
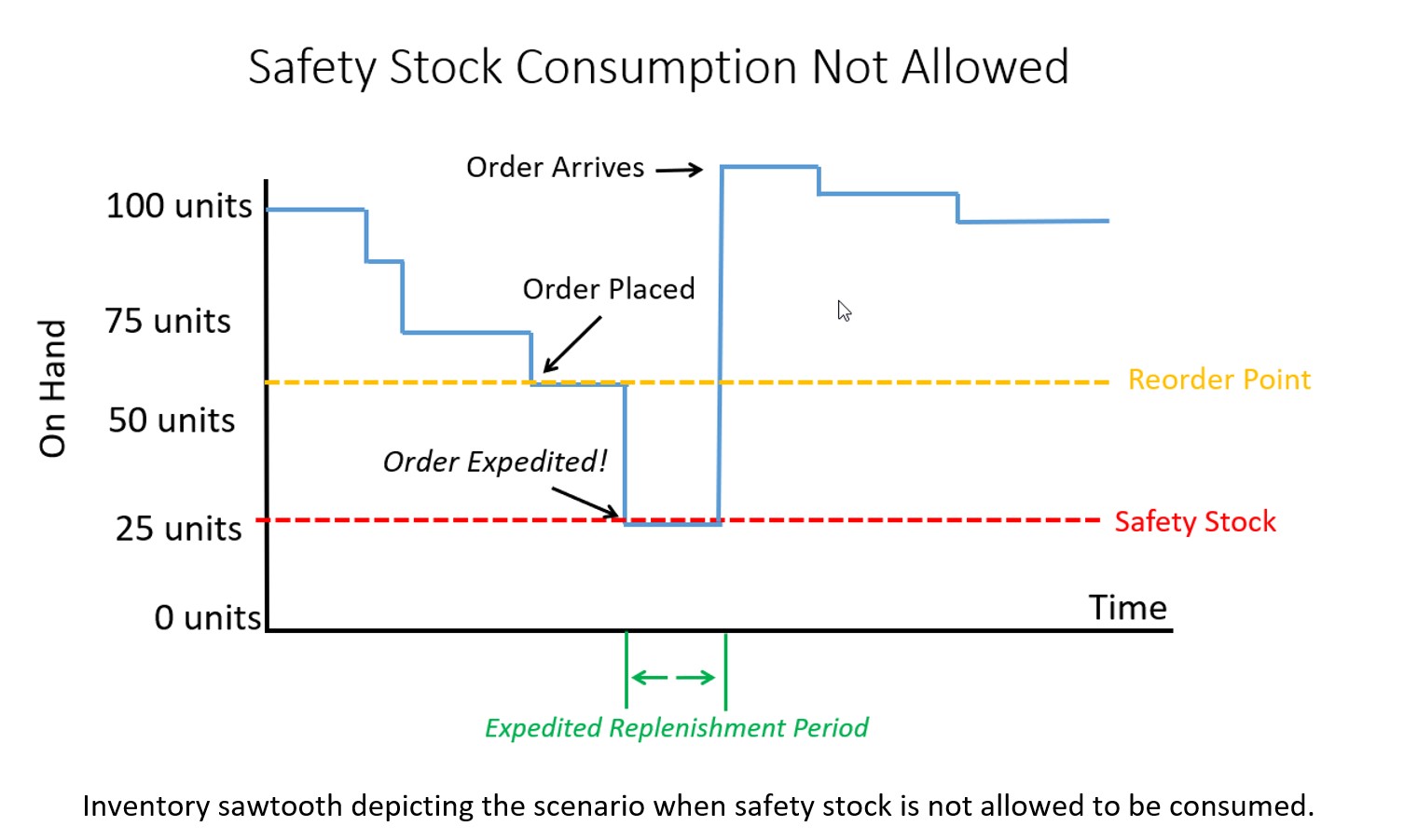
Configuratie 1. Veiligheidsvoorraad wordt behandeld als noodvoorraad dat kan niet geconsumeerd worden. Als een inbreuk op de veiligheidsvoorraad wordt voorspeld, dwingt het ERP-systeem een spoedprocedure af, ongeacht de kosten, zodat de aanwezige voorraad nooit onder de veiligheidsvoorraad komt, zelfs als een geplande ontvangst al in bestelling is en binnenkort zal aankomen.
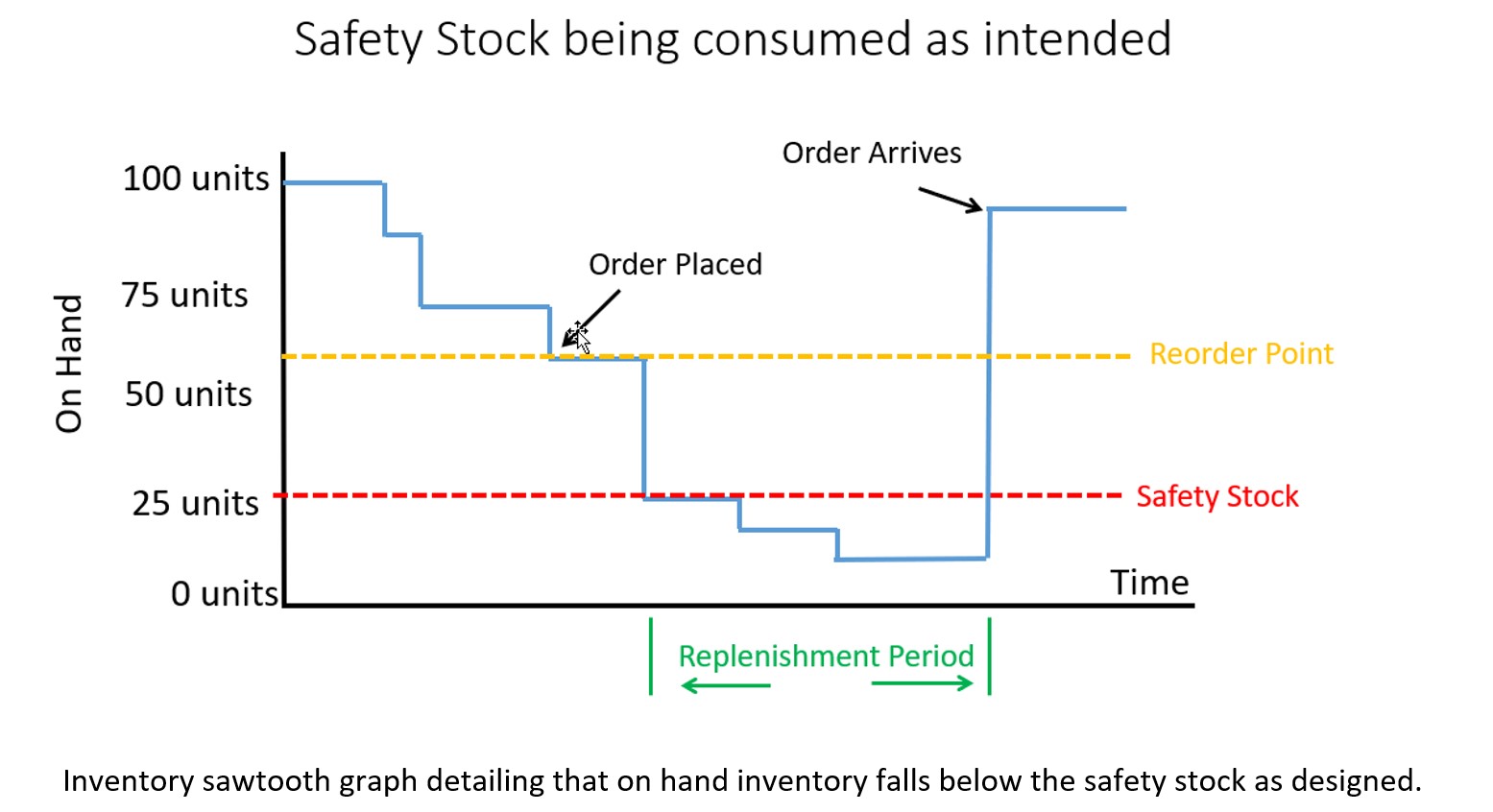
Configuratie 2. Veiligheidsvoorraad wordt behandeld als Buffervoorraad die is ontworpen om te worden geconsumeerd. Het ERP-systeem zal een bestelling plaatsen wanneer een inbreuk op de veiligheidsvoorraad wordt voorspeld, maar de voorhanden voorraad mag onder de veiligheidsvoorraad dalen. De buffervoorraad beschermt tegen stockout tijdens de bevoorradingsperiode (dwz de doorlooptijd).
Configuratie 3. Veiligheidsvoorraad wordt door het systeem genegeerd en behandeld als een visuele weergave planningshulp of vuistregel. Het wordt genegeerd door de berekeningen van de leveringsplanning, maar wordt door de planner gebruikt om handmatige beoordelingen te maken van wanneer er besteld moet worden.
Opmerking: we raden nooit aan om het veiligheidsvoorraadveld te gebruiken zoals beschreven in Configuratie 3. In de meeste gevallen waren deze configuraties niet bedoeld, maar het resultaat van jarenlange improvisatie die ertoe hebben geleid dat het ERP op een niet-standaard manier werd gebruikt. Over het algemeen zijn deze velden ontworpen om de aanvullingsberekeningen programmatisch te beïnvloeden. De focus van ons gesprek zal dus liggen op configuraties 1 en 2.
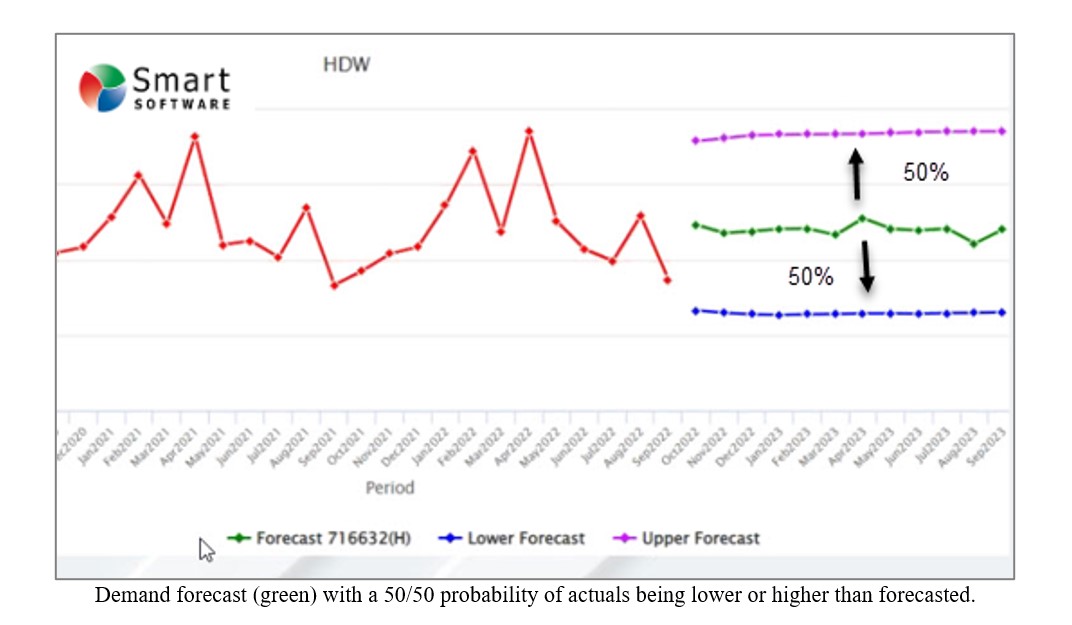
Systemen voor prognoses en inventarisoptimalisatie zijn ontworpen om prognoses te berekenen die anticiperen op voorraadafname en vervolgens veiligheidsvoorraden te berekenen die voldoende zijn om bescherming te bieden tegen variabiliteit in vraag en aanbod. Dit betekent dat de veiligheidsvoorraad bedoeld is om te worden gebruikt als een beschermende buffer (configuratie 2) en niet als noodsituatie schaars (configuratie 3). Het is ook belangrijk om te begrijpen dat, door het ontwerp, de veiligheidsvoorraad zal worden geconsumeerd ongeveer 50% van die tijd.
Waarom 50%? Omdat werkelijke bestellingen de helft van de tijd een onbevooroordeelde prognose zullen overschrijden. Zie onderstaande afbeelding om dit te illustreren. Een "goede" prognose zou de waarde moeten opleveren die het dichtst bij de werkelijke vraag komt, zodat de werkelijke vraag hoger of lager zal zijn zonder vooringenomenheid in beide richtingen.
Als u uw ERP-systeem zo heeft geconfigureerd dat het verbruik van veiligheidsvoorraad correct is toegestaan, dan kan de voorhanden voorraad er uitzien zoals in de onderstaande grafiek. Houd er rekening mee dat een deel van de veiligheidsvoorraad is verbruikt, maar een stockout is vermeden. Het serviceniveau dat u nastreeft bij het berekenen van de veiligheidsvoorraad, bepaalt hoe vaak u uw voorraad moet aanvullen voordat de aanvullingsorder arriveert. De gemiddelde voorraad is in dit scenario ongeveer 60 eenheden over de tijdshorizon.
Als uw ERP-systeem is geconfigureerd om niet het verbruik van de veiligheidsvoorraad toestaat en de ingevoerde hoeveelheid in het veld voor de veiligheidsvoorraad meer behandelt als noodreserves, dan heb je een enorme overvoorraad! Uw beschikbare voorraad ziet er uit als in de onderstaande grafiek, waarbij bestellingen worden versneld zodra een inbreuk op de veiligheidsvoorraad wordt verwacht. De gemiddelde voorraad is ongeveer 90 eenheden, een toename van 50% in vergelijking met toen u toestond dat veiligheidsvoorraad werd verbruikt.