Degenen onder u die actuele onderwerpen volgen, zullen bekend zijn met de term ‘digitale tweeling’. Degenen die het te druk hebben gehad met hun werk, willen misschien verder lezen en bijpraten.
Wat is een digitale tweeling?
Hoewel er verschillende definities van digital twin zijn, is er een die goed werkt:
Een digitale tweeling is een dynamiek virtuele kopie van een fysiek bezit, proces, systeem of omgeving die er hetzelfde uitziet en zich identiek gedraagt als zijn tegenhanger in de echte wereld. Een digitale tweeling neemt gegevens op en repliceert processen dus dat kan mogelijke prestatieresultaten voorspellen en problemen die het echte product zou kunnen ondergaan. [Bron: Unity.com]. Voor meer achtergrondinformatie kunt u terecht op Mckinsey.com.
Wat is het verschil tussen een digital twin (hierna DT) en een model? In de eerste plaats wordt een ODC verbonden met realtime gegevens om het model te behouden als een actuele weergave van het systeem waarmee u werkt.
Onze huidige producten zouden we “slow-motion DT's” kunnen noemen, omdat ze meestal worden gebruikt met niet-realtime gegevens (maar geen verouderde gegevens, omdat deze van de ene op de andere dag worden bijgewerkt) en worden toegepast op problemen zoals het plannen van de grondstoffenaankopen voor het volgende kwartaal of het instellen van voorraadparameters voor een maand of langer.
Gebruiken mensen digital twins in mijn branche?
Mijn indruk is dat de penetratie van DT's wellicht het hoogst is in de lucht- en ruimtevaart- en nucleaire industrie. De meeste van onze klanten bevinden zich elders: in de productie, distributie en openbare voorzieningen zoals transport en energie. Binnenkort zullen we nieuwe producten aanbieden die dichter bij de strikte definitie van een DT komen die nauw verbonden is met het systeem dat hij vertegenwoordigt.
DT-voorbeeld
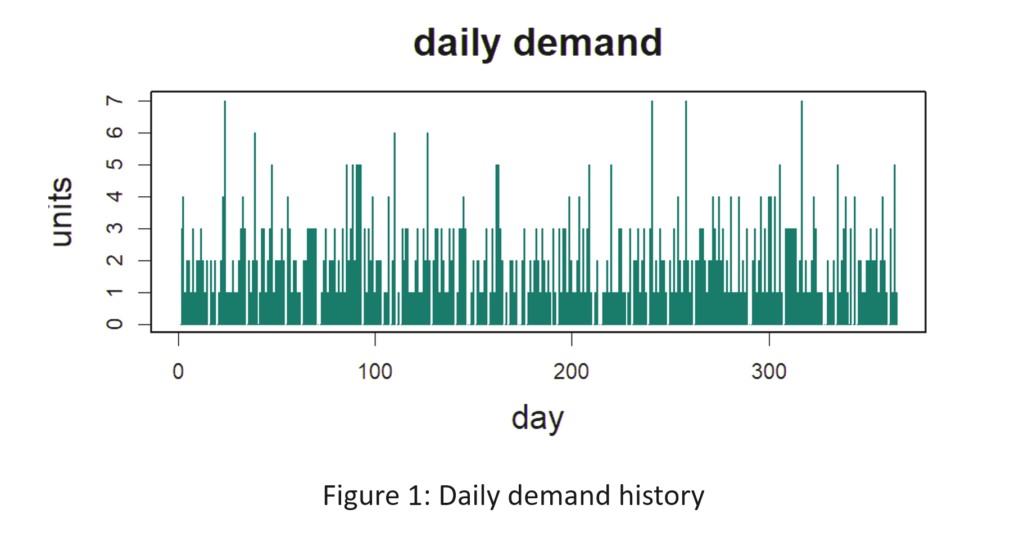
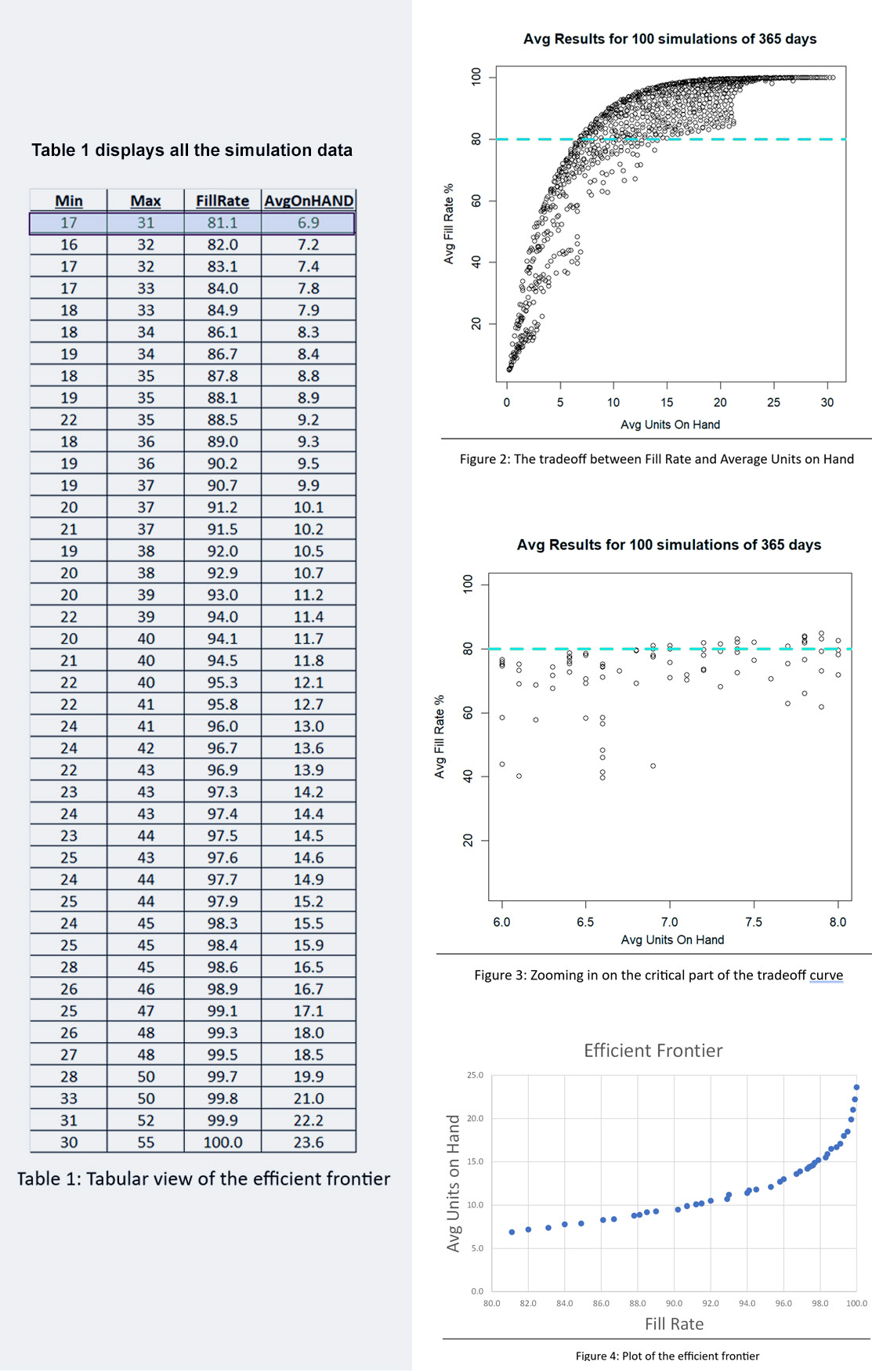
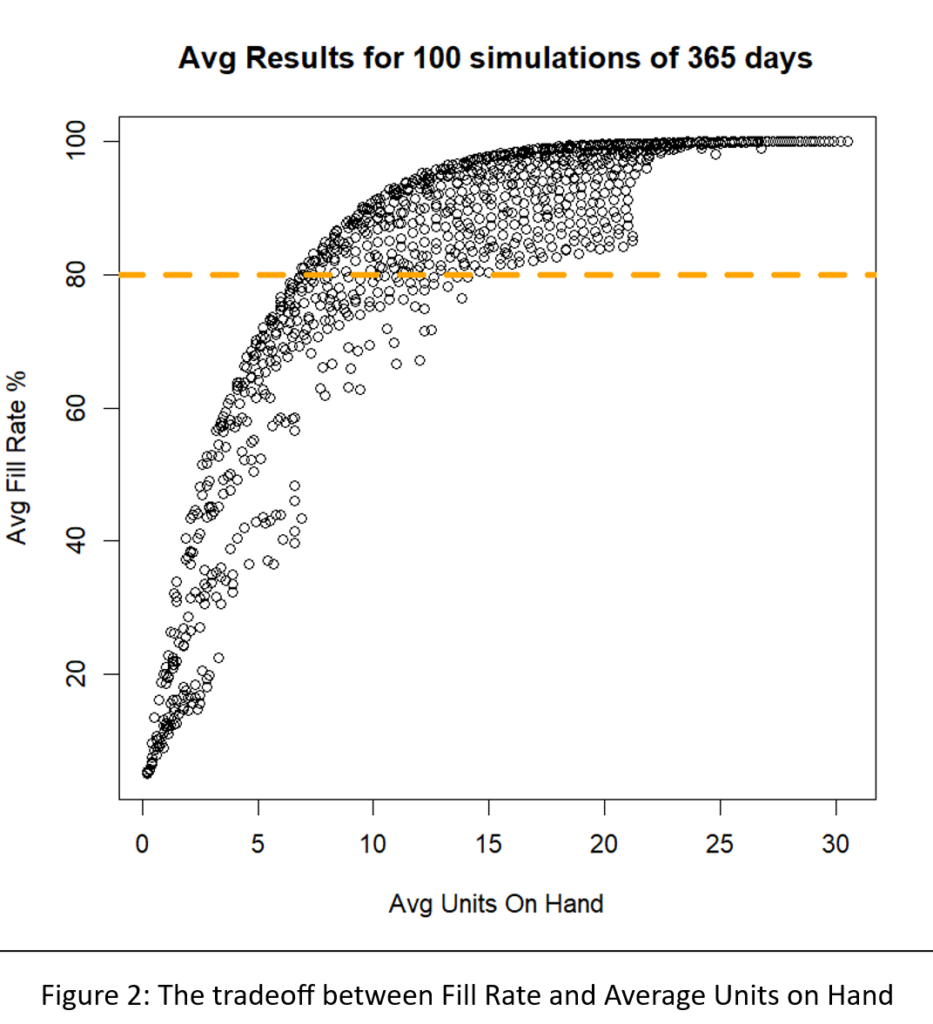
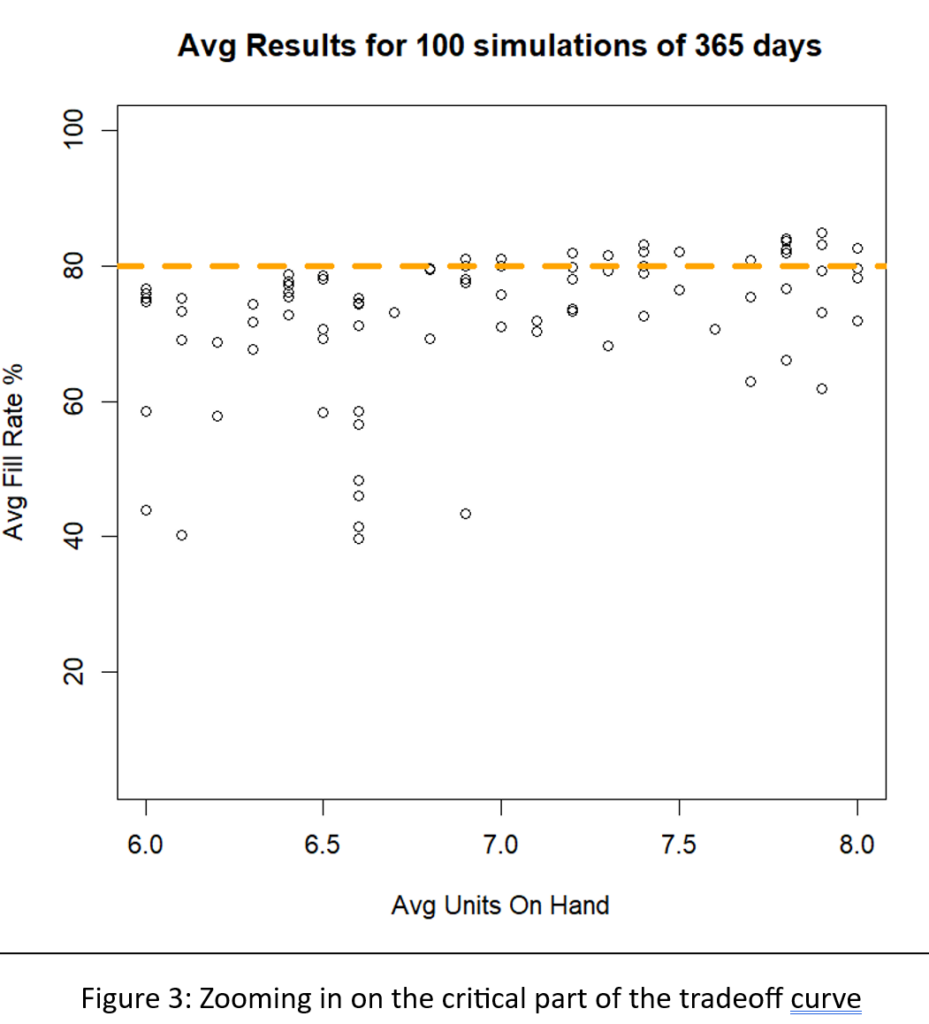
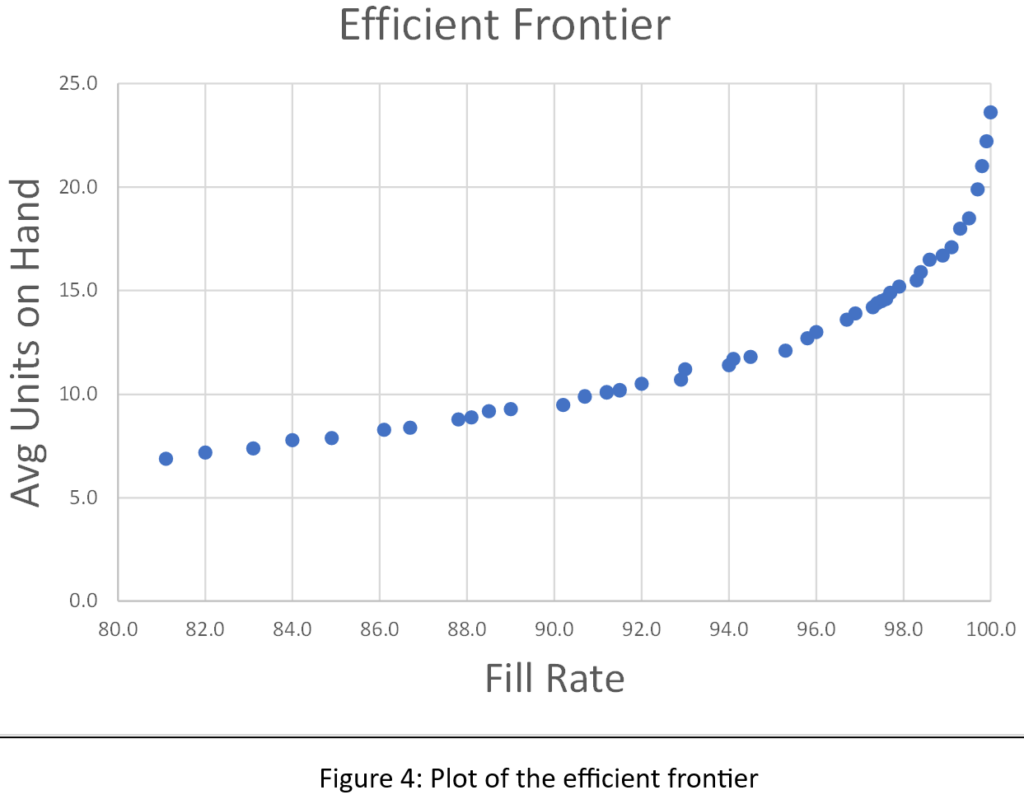
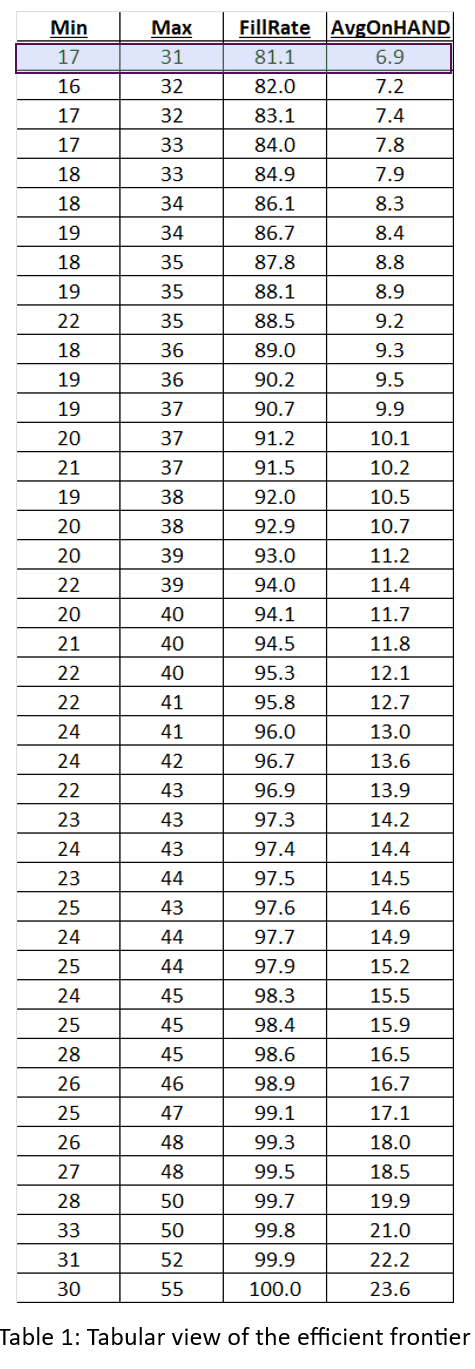
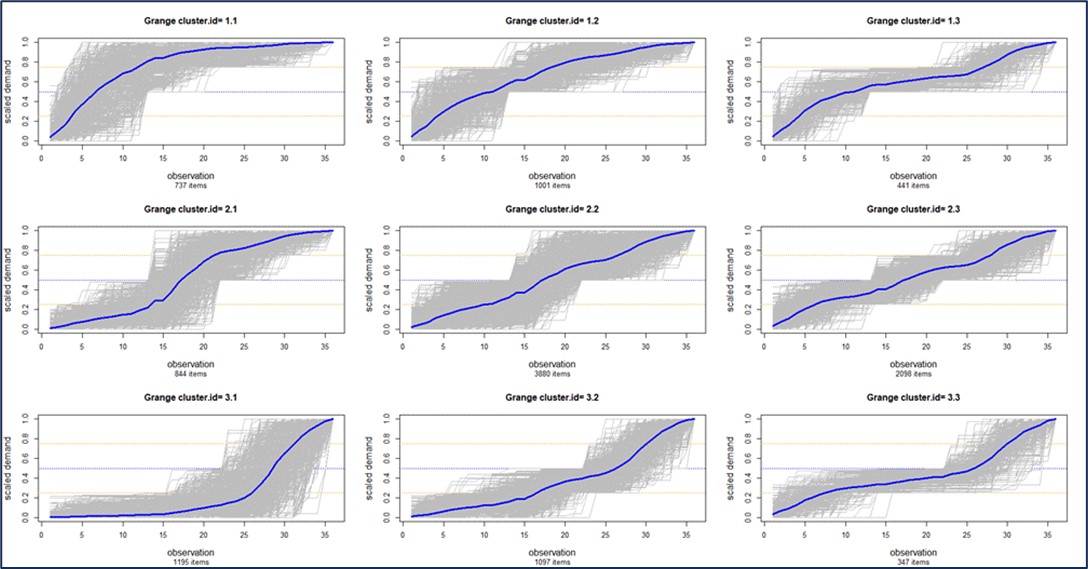
De meeste gebruikers van Smart Inventory Optimization™ (SIO) voer de applicatie periodiek uit, meestal maandelijks. SIO analyseert de huidige vraag naar voorraadartikelen en recente doorlooptijden van leveranciers en zet deze om in respectievelijk vraag- en aanbodscenario's. Vervolgens stellen gebruikers interactief (voor individuele artikelen) of automatisch (op schaal) parameters voor voorraadbeheer in die de gewenste gemiddelde prestaties op lange termijn opleveren, waarbij de concurrerende doelen van het minimaliseren van de voorraad in evenwicht worden gebracht en tegelijkertijd een voldoende niveau van artikelbeschikbaarheid wordt gegarandeerd.
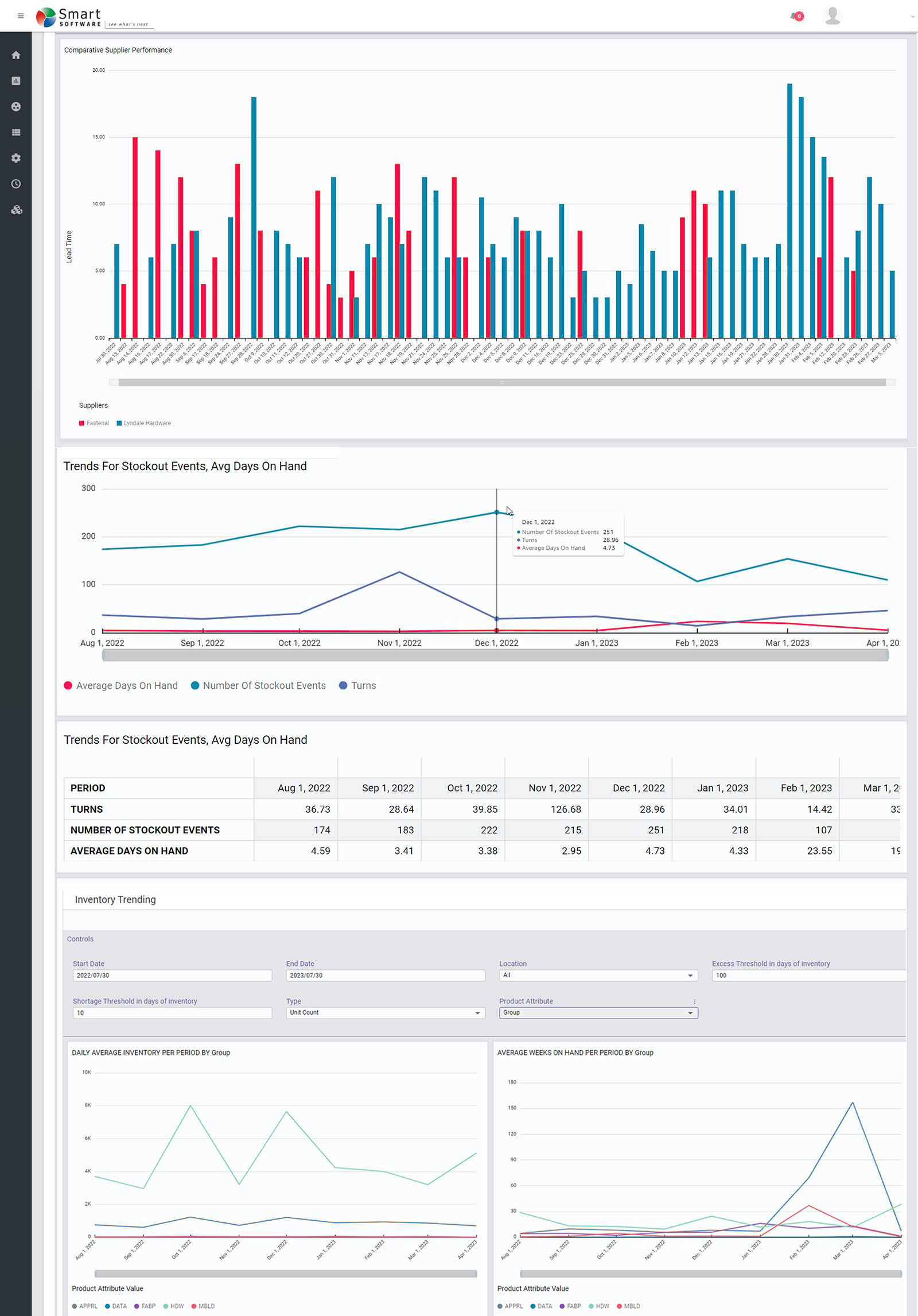
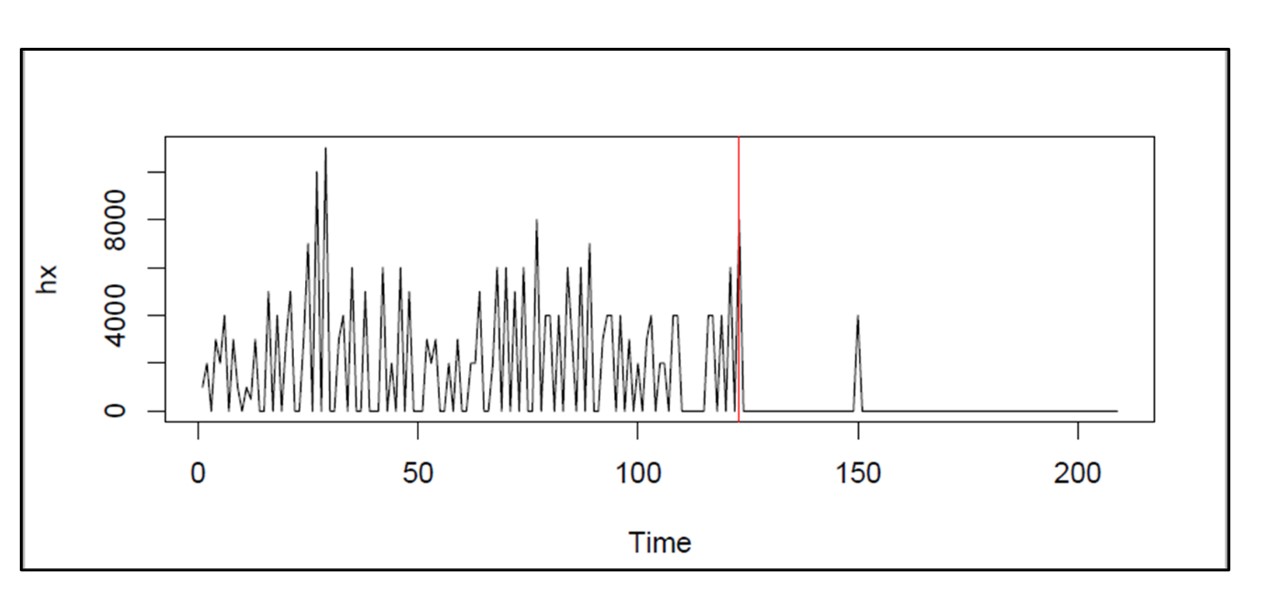
Smart Supply Planner (SSP) reageert op een directere manier op onvoorziene gebeurtenissen. Elke dag kan er een abnormale bestelling plaatsvinden die de vraag doet toenemen, bijvoorbeeld wanneer een nieuwe klant een verrassende eerste voorraadbestelling plaatst. Of een belangrijke leverancier kan een probleem ervaren in zijn fabriek en gedwongen worden de verzending van uw geplande aanvullingsorders uit te stellen. Op de lange termijn worden deze onvoorziene omstandigheden gemiddeld en rechtvaardigen ze de aanbevelingen die uit SIO komen. SSP biedt u echter een manier om op de korte termijn te reageren en kansen te grijpen of kogels te ontwijken.
In de kern werkt SSP als SIO, in die zin dat het scenariogestuurd is. De verschillen zijn dat het korte planningshorizon gebruikt en real-time initiële omstandigheden gebruikt als basis voor zijn simulaties van de prestaties van voorraadsystemen. Vervolgens zal het realtime aanbevelingen doen voor interventies die de verstoring veroorzaakt door de onvoorziene gebeurtenissen compenseren. Dit omvat onder meer het annuleren of versnellen van aanvullingsorders.
Overzicht
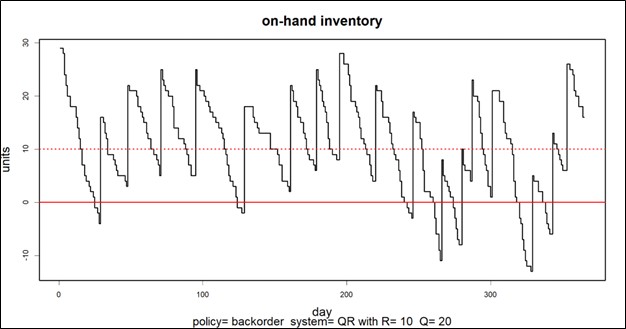
Met Digital Twins kunt u plannen ‘in silico’ uitproberen voordat u ze in de fabriek of het magazijn implementeert. De kern bestaat uit wiskundige modellen van uw bedrijfsvoering, maar verbonden met realtime gegevens. Ze bieden een ‘digitale sandbox’ waarin u ideeën kunt uitproberen en direct voorspellingen kunt krijgen over hoe goed ze zullen werken. Veel meer dan een spreadsheet zullen DT's binnenkort het belangrijkste hulpmiddel zijn in uw gereedschapskist voor voorraadplanning.