Los escenarios probabilísticos son secuencias de puntos de datos generados para representar situaciones potenciales del mundo real. A diferencia de los escenarios de los juegos de guerra u otras simulaciones, se trata de series temporales sintéticas que se utilizan como datos de entrada para los modelos de sistemas o como generadores de intuición para los responsables de la toma de decisiones.
Por ejemplo, se pueden introducir escenarios de demanda futura de artículos en modelos de simulación Monte Carlo de sistemas de control de inventario, creando así un laboratorio virtual en el que explorar las consecuencias de las decisiones de gestión, como cambiar los puntos de reorden y/o las cantidades de los pedidos. Además, los gráficos de métricas como el inventario disponible o los desabastecimientos pueden ayudar a los planificadores de inventario a profundizar su “sensación” de la aleatoriedad inherente a sus operaciones.
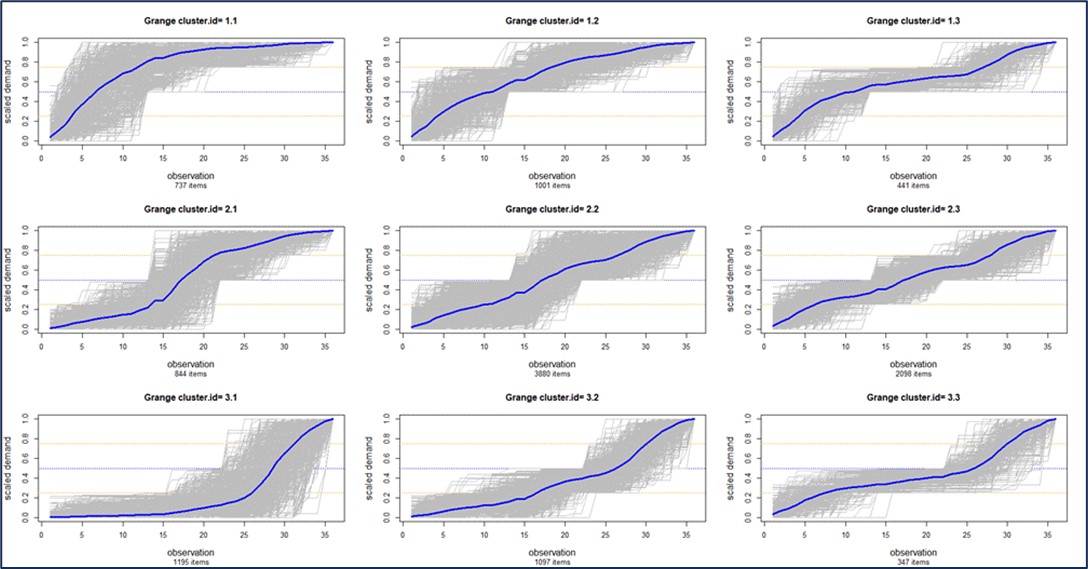
La Figura 1 muestra escenarios de demanda diaria generados a partir de una única serie de demanda observada registrada durante un año. Tenga en cuenta que el mismo proceso de generación de datos puede “verse muy diferente” en detalle de una muestra a otra. Esto imita la vida real.
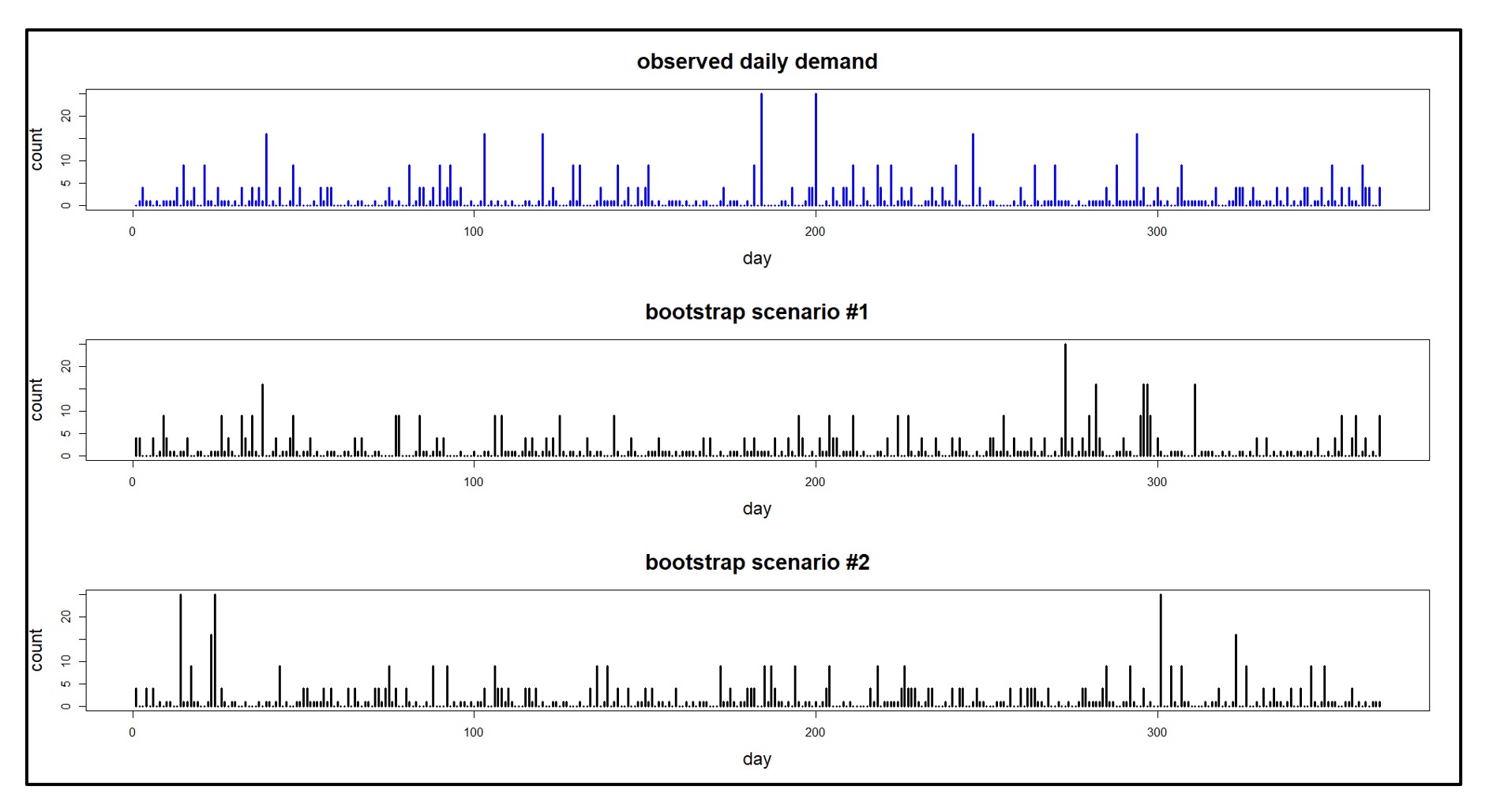
Figura 1: Secuencia de demanda observada y escenarios de demanda derivados de ella.
La Figura 2 muestra dos escenarios de demanda y sus consecuencias para el stock disponible en un sistema de control de inventario particular. La diferencia entre los dos gráficos de inventario ilustra el grado en que la aleatoriedad en la demanda domina el problema. El gráfico superior muestra dos episodios de desabastecimiento, mientras que el gráfico inferior muestra nueve. El promedio de muchos escenarios aclarará los valores típicos de las métricas clave de rendimiento (KPI), como el número promedio de desabastecimientos asociados con cualquier elección de punto de pedido y cantidad de pedido (que son 10 y 25, respectivamente, en la Figura 2).
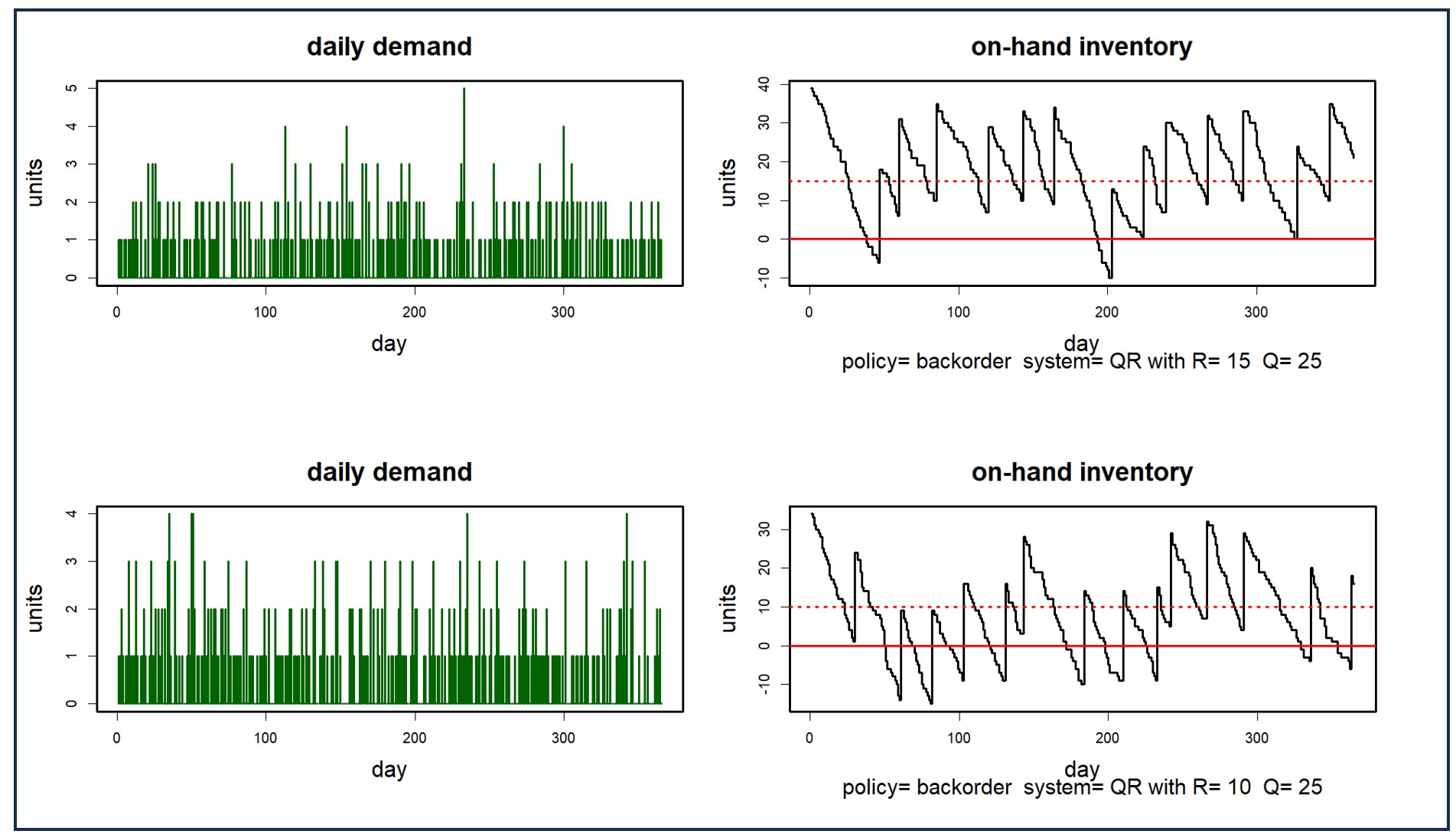
Figura 2: Dos escenarios de demanda y sus consecuencias para el inventario disponible
En esta nota, describiremos técnicas para crear escenarios y enumeraremos criterios para evaluar generadores de escenarios.
Criterios para escenarios
Como veremos a continuación, hay varias formas de crear escenarios. Independientemente de la fuente, ¿qué criterios definen un escenario “bueno”? Hay cuatro criterios principales: fidelidad, variedad, cantidad y costo. Fidelidad Resume con qué precisión un escenario imita situaciones del mundo real. La alta fidelidad significa que los escenarios reflejan fielmente los acontecimientos reales, proporcionando una base sólida para el análisis y la toma de decisiones. Variedad describe la diversidad de escenarios que un generador puede crear. Un generador versátil puede simular una amplia gama de situaciones potenciales, lo que permite una exploración exhaustiva de posibilidades y riesgos. Cantidad Se refiere a cuántos escenarios puede producir un generador. Un generador que puede crear una gran cantidad de escenarios proporciona amplios datos para el análisis. Costo considera tanto los recursos computacionales como humanos necesarios para producir los escenarios. Un generador de escenarios eficiente equilibra la calidad con el uso de recursos, garantizando que el esfuerzo esté justificado por el valor y la precisión de los resultados.
Generación de escenarios
Nuevamente, piense en un escenario como una serie de tiempo. ¿Cómo se crean los escenarios?
- Taller de Geppetto: Este enfoque implica la elaboración manual de escenarios por parte de expertos. Si bien puede producir alta fidelidad (realismo), requiere muchos recursos y no puede generar variedad fácilmente, lo que requiere una gran cantidad de escenarios.
- Día de la Marmota: Este método implica el uso repetido de una única situación del mundo real como entrada. Si bien es realista por definición y rentable (no se utilizan recursos más allá del registro de los datos), este enfoque carece de variedad y, por lo tanto, no puede reflejar con precisión la diversidad de escenarios del mundo real.
- Modelos paramétricos: Ejemplos de modelos paramétricos son los clásicos estudiados en las clases de Estadística 101: el Normal, exponencial, Poisson, etc. Los gráficos de demanda en la Figura 2 se generan paramétricamente, siendo los cuadrados de variables aleatorias de Poisson. Estos modelos generan una cantidad ilimitada de escenarios de bajo costo con buena variedad, pero es posible que no siempre capturen la complejidad de los datos del mundo real, lo que podría comprometer la fidelidad. Cuando la realidad es más complicada, estos modelos generan escenarios demasiado simplificados.
- Bootstraps de series temporales no paramétricas: Este enfoque puede obtener buenos resultados en todos los criterios: fidelidad, variedad, cantidad y costo. Es un método versátil que sobresale en la creación de una gran cantidad de escenarios realistas. Los historiales de demanda sintéticos en la Figura 1 son muestras de arranque simples basadas en los valores observados en el gráfico superior. (Para obtener algunos detalles esenciales sobre la generación de escenarios, consulte los enlaces a continuación).
Escenarios de explotación
Los escenarios demuestran su valor de dos maneras: como insumos para la toma de decisiones y como generadores de intuición. Por ejemplo, cuando los escenarios de demanda se utilizan como datos de entrada para los modelos de simulación, permiten realizar pruebas de estrés y estimar el rendimiento para el diseño del sistema. Los escenarios también pueden servir como generadores de intuición para los tomadores de decisiones o los operadores de sistemas. Su representación visual ayuda a desarrollar una visión y apreciación de los riesgos involucrados en la toma de decisiones operativas, ya sea para el pronóstico de la demanda o la gestión de inventario.
El análisis basado en escenarios requiere mucha informática, especialmente cuando los escenarios se generan mediante arranque. En Smart Software, la computación se realiza en la nube. Imagine la carga computacional involucrada en determinar los puntos de reorden y las cantidades de los pedidos para cada una de las decenas de miles de artículos del inventario utilizando cientos o miles de simulaciones de demanda para cada artículo. Imagine además que el software no sólo evalúa un par de punto de reorden/cantidad de pedido específico propuesto, sino que recorre todo el “espacio de diseño” de pares para encontrar el mejor par de parámetros de control para cada artículo. Para que esto sea práctico, aprovechamos el poder de procesamiento paralelo de la nube. Esencialmente, a cada artículo del inventario se le asigna su propia computadora para usar en los cálculos, de modo que todos esos cálculos puedan ocurrir simultáneamente en lugar de secuencialmente. Ahora podemos soltarnos y realmente brindarle los resultados que necesita.
Aprendiendo más
Aquellos interesados en más detalles técnicos y referencias pueden encontrar más información aquí.
¿Qué constituye un pronóstico probabilístico?
Pronóstico Probabilístico y Demanda Intermitente