Lidiar con el día a día de la gestión de inventario puede mantenerle ocupado. Existe el ritmo habitual de realizar pedidos, recibir, pronosticar y planificar, y mover cosas en el almacén. Luego están los tiempos frenéticos: escasez, trámites urgentes, llamadas de último momento para encontrar nuevos proveedores.
Toda esta actividad va en contra de tomarte un momento para ver cómo te va. Pero sabes que tienes que levantar la cabeza de vez en cuando para ver hacia dónde te diriges. Para eso, su software de inventario debe mostrarle métricas (y no solo una, sino un conjunto completo de métricas o KPI): indicadores clave de rendimiento.
Múltiples métricas
Dependiendo de su rol en su organización, diferentes métricas tendrán diferente importancia. Si usted está en el lado financiero de la casa, la inversión en inventario puede ser una prioridad: ¿cuánto efectivo está invertido en el inventario? Si está del lado de las ventas, la disponibilidad del artículo puede ser lo más importante: ¿cuál es la probabilidad de que pueda decir “sí” a un pedido? Si usted es responsable del reabastecimiento, ¿cuántas órdenes de compra tendrá que recortar su gente en el próximo trimestre?
Métricas de disponibilidad
Volvamos a la disponibilidad de artículos. ¿Cómo se le pone un número a eso? Las dos métricas de disponibilidad más utilizadas son el "nivel de servicio" y la "tasa de cumplimiento". ¿Cual es la diferencia? Es la diferencia entre decir “Ayer tuvimos un terremoto” y decir “Ayer tuvimos un terremoto y fue de 6,4 en la escala de Richter”. El nivel de servicio registra la frecuencia de los desabastecimientos sin importar su tamaño; la tasa de cumplimiento refleja su gravedad. Los dos pueden parecer apuntar en direcciones opuestas, lo que causa cierta confusión. Puede tener un buen nivel de servicio, digamos 90%, pero tener una tasa de cumplimiento vergonzosa, digamos 50%. O viceversa. Lo que los diferencia es la distribución del tamaño de la demanda. Por ejemplo, si la distribución está muy sesgada, por lo que la mayoría de las demandas son pequeñas pero algunas son enormes, es posible que obtenga la división 90%/50% mencionada anteriormente. Si su atención se centra en la frecuencia con la que debe realizar pedidos pendientes, el nivel de servicio es más relevante. Si su preocupación es qué tan grande puede llegar a ser un trámite urgente, la tasa de cumplimiento es más relevante.
Un gráfico para gobernarlos a todos
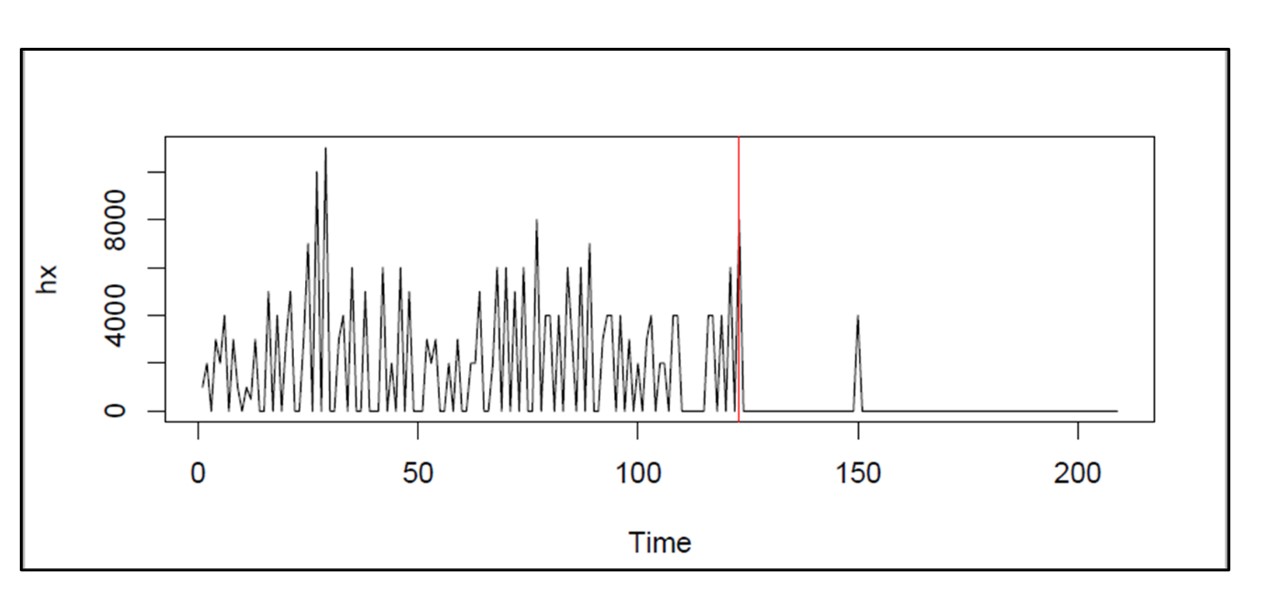
Un gráfico del inventario disponible puede proporcionar la base para calcular múltiples KPI. Considere la Figura 1, que muestra los datos disponibles cada día durante un año. Este gráfico tiene la información necesaria para calcular múltiples métricas: inversión en inventario, nivel de servicio, tasa de cumplimiento, tasa de reorden y otras métricas.
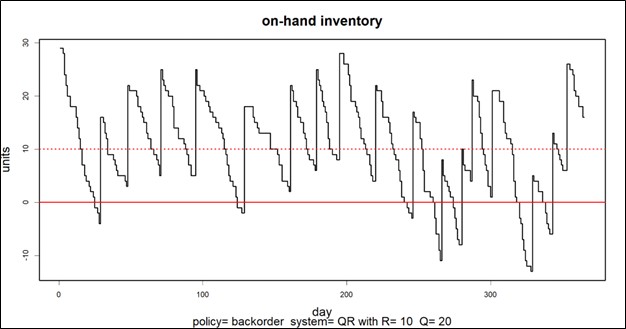
Inversión en inventario: la altura promedio del gráfico cuando es superior a cero, cuando se multiplica por el costo unitario del artículo del inventario, da el valor en dólares trimestral.
Nivel de servicio: la fracción de ciclos de inventario que terminan por encima de cero es el nivel de servicio. Los ciclos de inventario están marcados por los movimientos ascendentes ocasionados por la llegada de pedidos de reabastecimiento.
Tasa de cumplimiento: la cantidad en la que el inventario cae por debajo de cero y cuánto tiempo permanece allí se combinan para determinar la tasa de cumplimiento.
En este caso, el número promedio de unidades disponibles fue 10,74, el nivel de servicio fue 54% y la tasa de cumplimiento fue 91%.
KPI y KPP
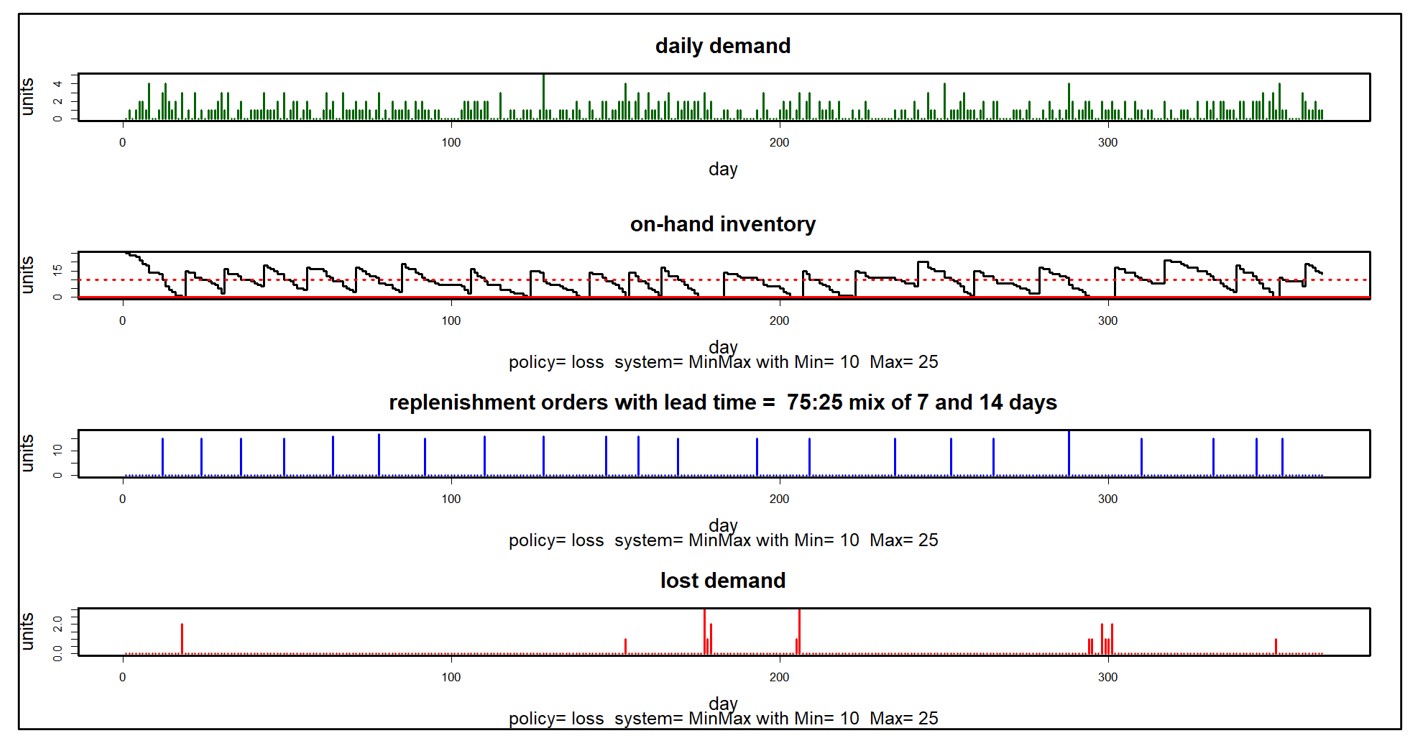
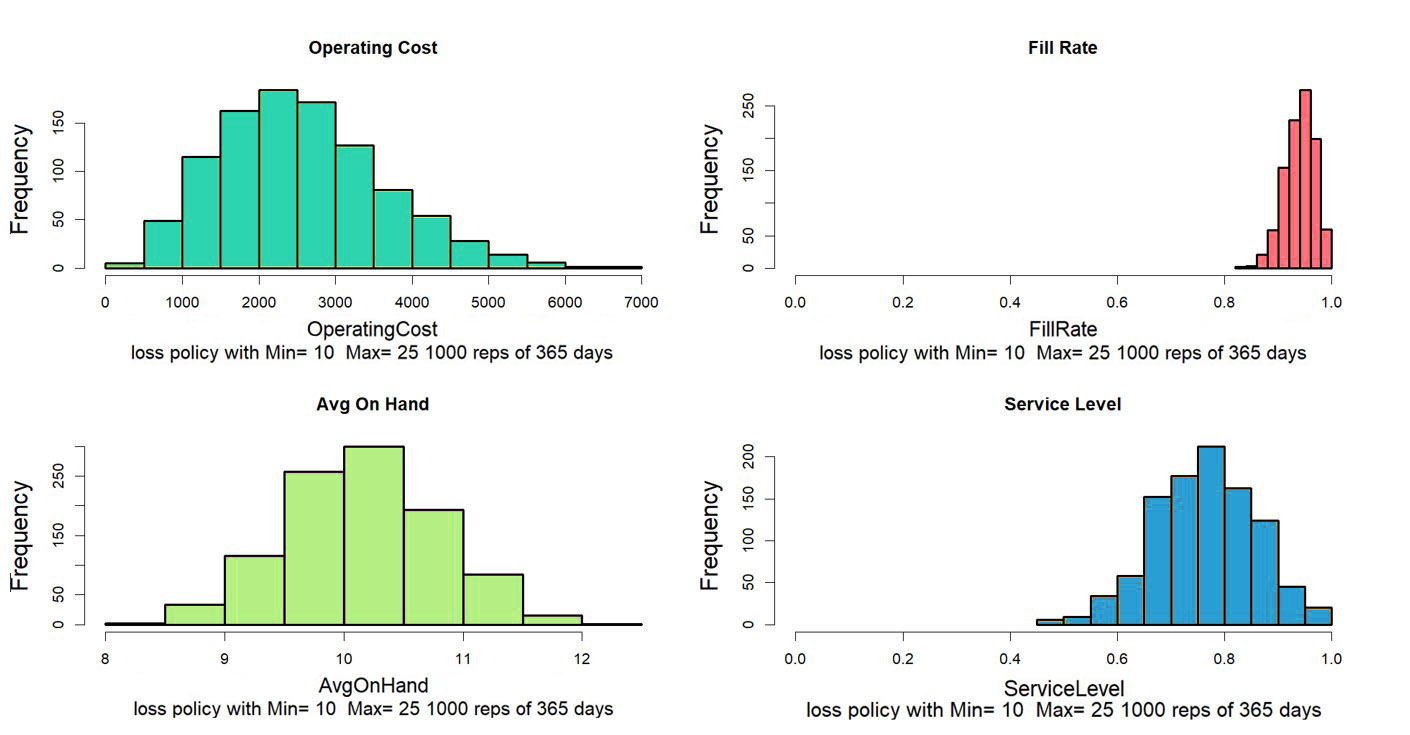
En los más de cuarenta años transcurridos desde que fundamos Smart Software, nunca he visto a un cliente producir un gráfico como el de la Figura 1. Aquellos que están más avanzados en su desarrollo sí producen y prestan atención a informes que enumeran sus KPI en forma tabular, pero no No mires ese gráfico. Sin embargo, ese gráfico tiene valor para desarrollar información sobre los ritmos aleatorios del inventario a medida que sube y baja.
Donde resulta especialmente útil es en la prospectiva. Dada la volatilidad del mercado, variables clave como los plazos de entrega de los proveedores, la demanda promedio y la variabilidad de la demanda cambian con el tiempo. Esto implica que los parámetros de control clave, como los puntos de reorden y las cantidades de los pedidos, deben ajustarse a estos cambios. Por ejemplo, si un proveedor dice que tendrá que aumentar su tiempo de entrega promedio en 2 días, esto afectará negativamente sus métricas y es posible que deba aumentar su punto de reorden para compensar. ¿Pero aumentarlo en cuánto?
Aquí es donde entra en juego el software de inventario moderno. Le permitirá proponer un ajuste y luego ver cómo se desarrollarán las cosas. Gráficos como el de la Figura 1 permiten ver y tener una idea del nuevo régimen. Y los gráficos se pueden analizar para calcular KPP (predicciones clave de rendimiento).
La ayuda del KPP elimina las conjeturas a la hora de realizar ajustes. Puede simular lo que sucederá con sus KPI si los cambia en respuesta a cambios en su entorno operativo y qué tan mal se pondrán las cosas si no realiza cambios.