Een voorspelling is een voorspelling over de waarde van een tijdreeksvariabele op een bepaald moment in de toekomst. U kunt bijvoorbeeld een schatting willen maken van de verkoop of vraag naar een productartikel voor volgende maand. Een tijdreeks is een reeks getallen die met gelijke tijdsintervallen zijn geregistreerd; bijvoorbeeld de maandelijks geregistreerde verkoop per eenheid.
De doelstellingen die u nastreeft wanneer u prognoses maakt, zijn afhankelijk van de aard van uw baan en uw bedrijf. Elke voorspelling is onzeker; in feite is er een reeks mogelijke waarden voor elke variabele die u voorspeld. Waarden in het midden van dit bereik hebben een grotere kans om daadwerkelijk te voorkomen, terwijl waarden aan de uiteinden van het bereik minder waarschijnlijk voorkomen. De volgende afbeelding illustreert een typische verdeling van voorspelde waarden.
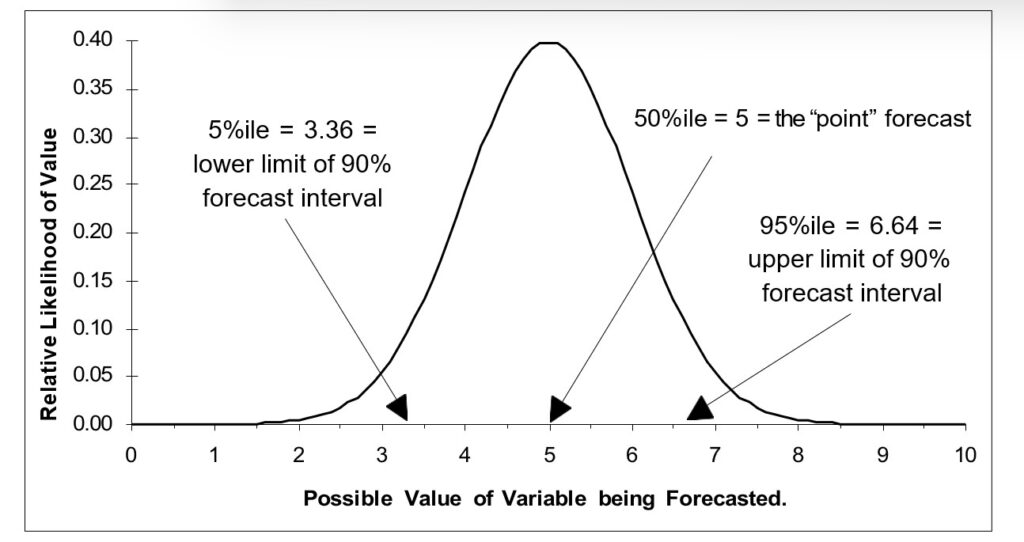
Ter illustratie van een voorspelde verdeling van voorspelde waarden
Punt voorspellingen
Het meest gebruikelijke gebruik van voorspellingen is het schatten van een reeks getallen die de meest waarschijnlijke toekomstige waarden van de betreffende variabele vertegenwoordigen. Stel dat u bijvoorbeeld een verkoop- en marketingplan voor uw bedrijf ontwikkelt. Mogelijk moet u twaalf cellen in een financieel spreadsheet invullen met schattingen van de totale inkomsten van uw bedrijf in de komende twaalf maanden. Dergelijke schattingen worden puntprognoses genoemd, omdat u voor elke prognoseperiode één enkel getal (gegevenspunt) wilt. De automatische prognosefunctie van Smart Demand Planner voorziet u automatisch van deze puntprognoses.
Intervalvoorspellingen
Hoewel puntvoorspellingen handig zijn, heeft u vaak meer profijt van intervalvoorspellingen. Intervalvoorspellingen tonen het meest waarschijnlijke bereik (interval) van waarden die zich in de toekomst kunnen voordoen. Deze zijn meestal nuttiger dan puntprognoses, omdat ze de hoeveelheid onzekerheid of risico weergeven die met een voorspelling gepaard gaat. Het prognose-intervalpercentage kan worden opgegeven in de verschillende prognosedialoogvensters in de Demand Planning Software. Met elk van de vele voorspellingsmethoden (automatisch, voortschrijdend gemiddelde, exponentiële afvlakking enzovoort) die beschikbaar zijn in Smart Demand Planner, kunt u een voorspellingsinterval instellen.
De standaardconfiguratie in Smart Demand Planner biedt 90%-voorspellingsintervallen. Interpreteer deze intervallen als het bereik waarbinnen de werkelijke waarden 90% van de tijd zullen vallen. Als de intervallen groot zijn, is er veel onzekerheid verbonden aan de puntvoorspellingen. Als de intervallen smal zijn, kunt u meer vertrouwen hebben. Als u een planningsfunctie uitvoert en op verschillende tijdstippen in de toekomst best-case- en worst-case-waarden wilt voor de variabelen die van belang zijn, kunt u voor dat doel de boven- en ondergrenzen van de prognose-intervallen gebruiken, waarbij de enkele puntschatting de meest waarschijnlijke waarde. In de vorige afbeelding strekt het voorspellingsinterval van 90% zich uit van 3,36 tot 6,64.
Bovenste percentielen
Bij voorraadbeheer kan het uw doel zijn om goede schattingen te maken van een hoog percentiel van de vraag naar een productitem. Met deze schattingen kunt u omgaan met de afweging tussen enerzijds het minimaliseren van de kosten voor het aanhouden en bestellen van voorraad, en anderzijds het minimaliseren van het aantal verloren of nabestelde verkopen als gevolg van een voorraadtekort. Om deze reden wilt u misschien het 99e percentiel of het serviceniveau van de vraag weten, aangezien de kans om dat niveau te overschrijden slechts 1% is.
Houd er bij het voorspellen van individuele variabelen met functies zoals automatische prognoses rekening mee dat de bovengrens van een 90%-voorspellingsinterval het 95e percentiel vertegenwoordigt van de voorspelde verdeling van de vraag naar die variabele. (Als u het 5e percentiel van het 95e percentiel aftrekt, blijft er een interval over met 95%-5% = 90% van de mogelijke waarden.) Dit betekent dat u de bovenste percentielen kunt schatten door de waarde van het voorspellingsinterval te wijzigen. In de figuur ‘Illustratie van een prognoseverdeling’ is het 95e percentiel 6,64.
Om het voorraadbeleid op het gewenste serviceniveau te optimaliseren of om het systeem te laten adviseren welk voorraadbeleid en serviceniveau het beste rendement oplevert, kunt u Smart Inventory Optimization overwegen. Het is ontworpen om wat-als-scenario's te ondersteunen die voorspelde afwegingen laten zien tussen verschillende voorraadbeleidslijnen, waaronder verschillende serviceniveaudoelen.
Lagere percentielen
Soms maakt u zich misschien zorgen over de onderkant van de voorspelde verdeling voor een variabele. Dergelijke gevallen doen zich vaak voor bij financiële toepassingen, waarbij een laag percentiel van een inkomstenraming een onvoorziene gebeurtenis vertegenwoordigt die financiële reserves vereist. U kunt Smart Demand Planner in dit geval gebruiken op een manier die analoog is aan het voorspellen van de bovenste percentielen. In de figuur ‘Illustratie van een prognoseverdeling’ is het 5e percentiel 3,36.
Kortom, bij voorspellen gaat het om het voorspellen van toekomstige waarden, waarbij puntvoorspellingen afzonderlijke schattingen bieden en intervalvoorspellingen die waarschijnlijke waardebereiken bieden. Smart Demand Planner automatiseert puntprognoses en stelt gebruikers in staat intervallen in te stellen, wat helpt bij het inschatten van de onzekerheid. Voor voorraadbeheer vergemakkelijkt de tool het begrijpen van de bovenste (bijvoorbeeld 99e percentiel) en lagere (bijvoorbeeld 5e percentiel) percentielen. Om het voorraadbeleid en de serviceniveaus te optimaliseren ondersteunt Smart Inventory Optimization 'wat-als'-scenario's, waardoor een effectieve besluitvorming wordt gegarandeerd over hoeveel u op voorraad moet hebben, gegeven het risico dat u bereid bent een voorraad op te geven.