We hebben onlangs een ontmoeting gehad met het IT-team bij een van onze klanten om de gegevensvereisten en de installatie van onze API-gebaseerde integratie te bespreken die gegevens zou halen uit hun lokale installatie van hun ERP-systeem. De IT-manager en de analist uitten allebei hun grote bezorgdheid over het verstrekken van deze gegevens en vroegen zich serieus af waarom ze überhaupt moesten worden verstrekt. Ze uitten zelfs hun bezorgdheid dat hun gegevens zouden kunnen worden doorverkocht aan hun concurrentie. Hun reactie was een grote verrassing voor ons. We hebben deze blog geschreven met hen in gedachten en om het voor anderen gemakkelijker te maken om te communiceren waarom bepaalde gegevens nodig zijn om een effectief vraagplanningsproces te ondersteunen.
Houd er rekening mee dat als u een prognoseanalist, vraagplanner of supply chain-professional bent, het meeste van wat u hieronder zult lezen voor de hand ligt. Maar wat deze bijeenkomst me heeft geleerd, is dat wat voor de ene groep specialisten vanzelfsprekend is, dat niet zal zijn voor een andere groep specialisten op een heel ander gebied.
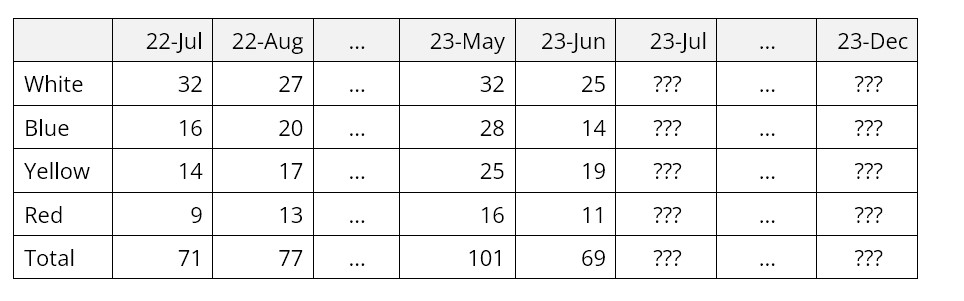
De vier belangrijkste soorten gegevens die nodig zijn, zijn:
- Historische transacties, zoals verkooporders en verzendingen.
- Taakgebruik transacties, zoals welke componenten nodig zijn om eindproducten te produceren
- Voorraadoverdrachttransacties, zoals welke inventaris van de ene locatie naar de andere is verzonden.
- Prijzen, kosten en attributen, zoals de eenheidskosten betaald aan de leverancier, de eenheidsprijs betaald door de klant en verschillende metagegevens zoals productfamilie, klasse, enz.
Hieronder volgt een korte uitleg waarom deze gegevens nodig zijn om de implementatie van software voor vraagplanning door een bedrijf te ondersteunen.
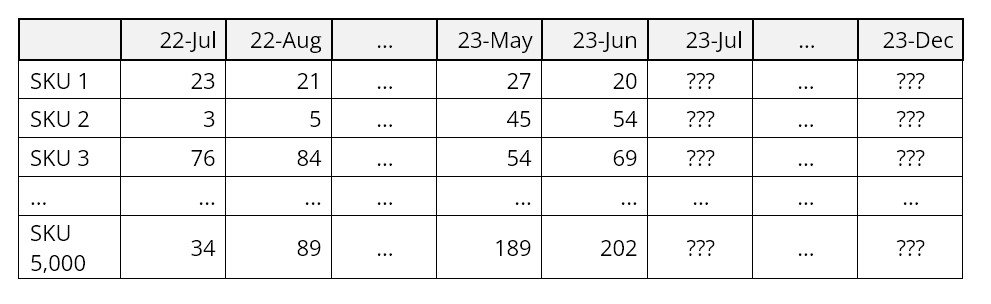
Transactiegegevens van historische verkopen en verzendingen per klant
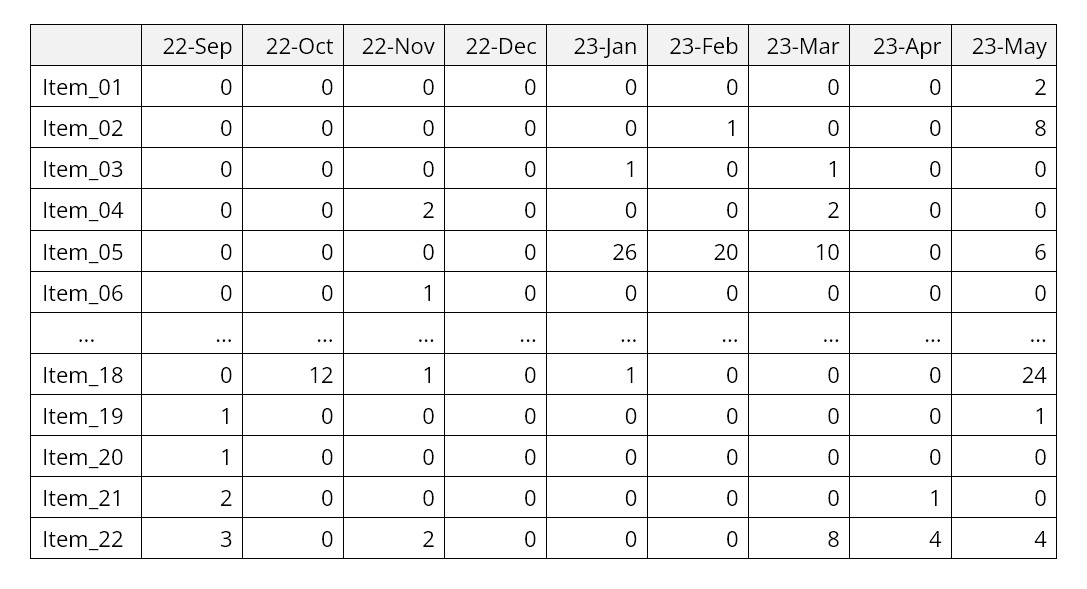
Denk aan wat uit de inventaris werd gehaald als de "grondstof" die nodig is voor software voor vraagplanning. Dit kan zijn wat aan wie en wanneer is verkocht of wat u aan wie en wanneer hebt verzonden. Of welke grondstoffen of halffabrikaten zijn verbruikt in werkorders en wanneer. Of wat er wanneer vanuit een distributiecentrum aan een satellietmagazijn wordt geleverd.
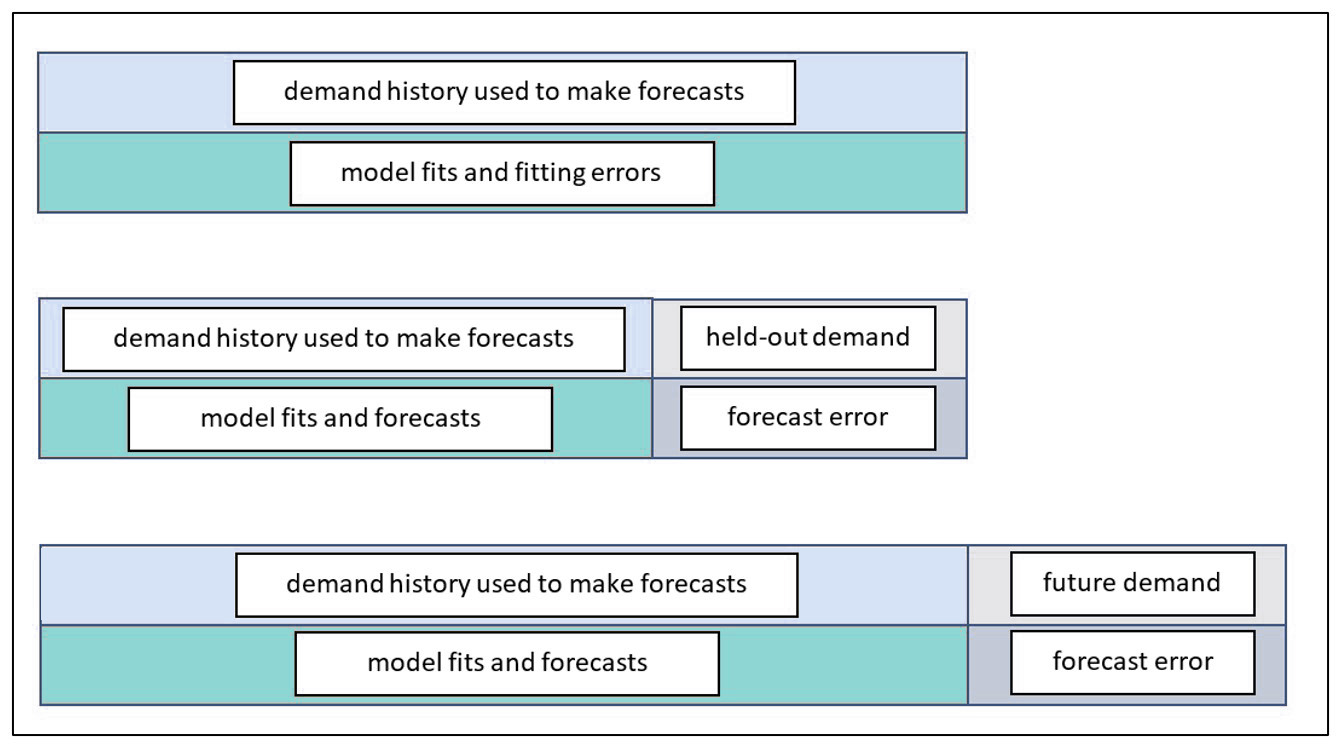
De geschiedenis van deze transacties wordt door de software geanalyseerd en gebruikt om statistische prognoses te produceren die waargenomen patronen extrapoleren. De gegevens worden geëvalueerd om patronen zoals trend, seizoensinvloeden, cyclische patronen bloot te leggen en om potentiële uitschieters te identificeren die zakelijke aandacht vereisen. Als deze gegevens niet algemeen toegankelijk zijn of onregelmatig worden bijgewerkt, is het bijna onmogelijk om een goede voorspelling van de toekomstige vraag te maken. Ja, je zou zakelijke kennis of onderbuikgevoel kunnen gebruiken, maar dat schaalt niet en introduceert bijna altijd vertekening in de prognose (dwz consequent te hoog of te laag voorspellen).
Er zijn gegevens nodig op transactieniveau om nauwkeurigere prognoses op wekelijks of zelfs dagelijks niveau te ondersteunen. Als een bedrijf bijvoorbeeld het drukke seizoen ingaat, wil het misschien beginnen met wekelijkse prognoses om de productie beter af te stemmen op de vraag. Dat lukt niet zonder de transactiegegevens in een goed gestructureerd datawarehouse te hebben.
Het kan ook zo zijn dat bepaalde soorten transacties niet in de vraaggegevens moeten worden opgenomen. Dit kan gebeuren wanneer de vraag het gevolg is van een forse korting of een andere omstandigheid waarvan het supply chain-team weet dat deze de resultaten zal vertekenen. Als de gegevens geaggregeerd worden verstrekt, is het veel moeilijker om deze uitzonderingen te scheiden. Bij Smart Software noemen we het proces om uit te zoeken welke transacties (en bijbehorende transactiekenmerken) in het vraagsignaal moeten worden meegeteld "vraagsignaalsamenstelling". Door toegang te hebben tot alle transacties kan een bedrijf zijn vraagsignaal in de loop van de tijd naar behoefte aanpassen binnen de software. Slechts het verstrekken van een deel van de gegevens resulteert in een veel rigidere vraagsamenstelling die alleen kan worden verholpen met extra implementatiewerk.
Prijzen en kosten
De prijs waarvoor u uw producten heeft verkocht en de kosten die u hebt betaald om ze (of grondstoffen) te kopen, zijn van cruciaal belang om inkomsten of kosten te kunnen voorspellen. Een belangrijk onderdeel van het vraagplanningsproces is het verkrijgen van zakelijke kennis van klanten en verkoopteams. Verkoopteams denken vaak aan de vraag per klant of productcategorie en spreken in de taal van dollars. Het is dus belangrijk om een prognose in dollars uit te drukken. Het vraagplanningssysteem kan dat niet als de prognose alleen in eenheden wordt weergegeven.
Vaak wordt de vraagprognose gebruikt om een groter planning- en budgetteringsproces aan te sturen of op zijn minst te beïnvloeden, en de belangrijkste input voor een budget is een omzetprognose. Wanneer vraagprognoses worden gebruikt om het S&OP-proces te ondersteunen, moet de software voor vraagplanning de gemiddelde prijs over alle transacties berekenen of "tijdgefaseerde" conversies toepassen die rekening houden met de op dat moment verkochte prijs. Zonder de onbewerkte gegevens over prijsstelling en kosten kan het vraagplanningsproces nog steeds functioneren, maar zal het ernstig worden belemmerd.
Productkenmerken, klantgegevens en locaties
Productattributen zijn nodig zodat voorspellers prognoses kunnen verzamelen voor verschillende productfamilies, groepen, goederencodes, enz. Het is handig om te weten hoeveel eenheden en de totale geprojecteerde gedollariseerde vraag voor verschillende categorieën. Zakelijke kennis over wat de vraag in de toekomst zou kunnen zijn, is vaak niet bekend op productniveau, maar wel op productfamilieniveau, klantniveau of regionaal niveau. Met de toevoeging van productkenmerken aan uw datafeed voor vraagplanning, kunt u eenvoudig prognoses "oprollen" van artikelniveau naar familieniveau. U kunt prognoses op deze niveaus omzetten in dollars en beter samenwerken aan hoe de prognose moet worden aangepast.
Zodra de kennis is toegepast in de vorm van een prognose-override, zal de software de wijziging automatisch afstemmen op alle individuele items waaruit de groep bestaat. Zo hoeft een forecast analist niet elk onderdeel apart aan te passen. Ze kunnen op geaggregeerd niveau een wijziging aanbrengen en de software voor vraagplanning de afstemming voor hen laten doen.
Groepering voor gemakkelijke analyse is ook van toepassing op klantkenmerken, zoals een toegewezen verkoper of de voorkeurslocatie van een klant voor verzending. En locatieattributen kunnen handig zijn, zoals toegewezen regio. Soms hebben attributen betrekking op een product- en locatiecombinatie, zoals voorkeursleverancier of toegewezen planner, die voor hetzelfde product kan verschillen, afhankelijk van het magazijn.
Een laatste opmerking over vertrouwelijkheid
Bedenk dat onze klant bezorgd was dat we hun gegevens aan een concurrent zouden verkopen. Dat zouden we nooit doen. Al tientallen jaren gebruiken we klantgegevens voor trainingsdoeleinden en om onze producten te verbeteren. We zijn nauwgezet in het beschermen van klantgegevens en het anonimiseren van alles wat bijvoorbeeld kan worden gebruikt om een punt in een blogpost te illustreren.