Degenen die prognoses maken, zijn het verschuldigd aan degenen die prognoses consumeren, en aan zichzelf, om zich bewust te zijn van de onzekerheid in hun prognoses. Deze notitie gaat over het schatten van prognoseonzekerheid en het gebruik van de schattingen in uw vraagplanningsproces. We richten ons op prognoses die zijn gemaakt ter ondersteuning van vraagplanning en op prognoses die inherent zijn aan voorraad optimaliseren beleid met betrekking tot bestelpunten, veiligheidsvoorraden en min/max-niveaus.
Als je dit leest, leer je over:
- Criteria voor het beoordelen van prognoses
-Bronnen van voorspellingsfout
- Berekening van de voorspellingsfout
-Voorspellingsfout omzetten in voorspellingsintervallen
-De relatie tussen vraagvoorspelling en voorraadoptimalisatie.
-Acties die u kunt ondernemen om deze concepten te gebruiken om de processen van uw bedrijf te verbeteren.
Criteria voor het beoordelen van prognoses
Voorspellingsfouten alleen zijn geen reden genoeg om prognoses als managementtool af te wijzen. Om een beroemd aforisme van George Box te verdraaien: "Alle voorspellingen zijn verkeerd, maar sommige zijn nuttig." Natuurlijk zullen zakelijke professionals altijd zoeken naar manieren om prognoses nuttiger te maken. Dit omvat meestal werk om prognosefouten te verminderen. Maar hoewel de nauwkeurigheid van prognoses het meest voor de hand liggende criterium is om prognoses te beoordelen, is het niet het enige. Hier is een lijst met criteria voor het evalueren van prognoses:
Nauwkeurigheid: Voorspellingen van toekomstige waarden zouden, achteraf bezien, heel dicht bij de werkelijke waarden moeten liggen die zich uiteindelijk zullen openbaren. Maar er kan een afnemend rendement zijn om nog een half procent nauwkeurigheid uit prognoses te persen die anders goed genoeg zijn om te gebruiken bij het nemen van beslissingen.
Tijdigheid: Gevechtspiloten verwijzen naar de OODA-lus (observeren, oriënteren, beslissen en handelen) en de "noodzaak om in de OODA-lus van de vijand te komen" zodat ze als eerste kunnen schieten. Ook bedrijven hebben beslissingscycli. Het leveren van een perfect nauwkeurige voorspelling de dag nadat het nodig was, is niet nuttig. Beter is een goede voorspelling die op tijd aankomt om bruikbaar te zijn.
Kosten: Het voorspellen van data, modellen, processen en mensen kosten allemaal geld. Een goedkopere prognose kan worden gevoed door gegevens die direct beschikbaar zijn; duurder zou een prognose zijn die draait op gegevens die moeten worden verzameld in een speciaal proces buiten de reikwijdte van de informatie-infrastructuur van een bedrijf. Een klassieke, kant-en-klare prognosetechniek zal minder duur zijn om aan te schaffen, te voeden en te exploiteren dan een complexe, op maat gemaakte, door een adviseur geleverde methode. Prognoses kunnen massaal worden geproduceerd door software onder supervisie van een enkele analist, of ze kunnen voortkomen uit een samenwerkingsproces dat tijd en inspanning vereist van grote groepen mensen, zoals districtsverkoopmanagers, productieteams en anderen. Technisch geavanceerde voorspellingstechnieken vereisen vaak het inhuren van personeel met gespecialiseerde technische expertise, zoals een masterdiploma in statistiek, dat doorgaans meer kost dan personeel met een minder geavanceerde opleiding.
Geloofwaardigheid: Uiteindelijk moet een leidinggevende elke prognose accepteren en ernaar handelen. Leidinggevenden hebben de neiging aanbevelingen te wantrouwen of te negeren die ze niet kunnen begrijpen of uitleggen aan de volgende persoon boven hen in de hiërarchie. Voor velen is geloven in een "zwarte doos" een te zware geloofsbeproeving, en zij verwerpen de voorspellingen van de zwarte doos ten gunste van iets transparanters.
Dat gezegd hebbende, zullen we ons nu concentreren op de voorspellingsnauwkeurigheid en de kwaadaardige tweeling, voorspellingsfout.
Bronnen van prognosefouten
Degenen die fouten willen verminderen, kunnen op drie plaatsen zoeken naar problemen:
1. De gegevens die in een prognosemodel gaan
2. Het model zelf
3. De context van de prognoseoefening
Er zijn verschillende manieren waarop gegevensproblemen kunnen leiden tot prognosefouten.
Grove fouten: Verkeerde data leveren verkeerde voorspellingen op. We hebben een geval gezien waarin computergegevens van de vraag naar producten een factor twee verkeerd waren! De betrokkenen zagen dat probleem meteen, maar een minder ernstige situatie kan er gemakkelijk doorheen glippen om het prognoseproces te vergiftigen. Sterker nog, het organiseren, verwerven en controleren van data is vaak de grootste bron van vertraging bij de implementatie van forecasting software. Veel gegevensproblemen lijken voort te komen uit het feit dat de gegevens onbelangrijk waren totdat een prognoseproject ze belangrijk maakte.
Afwijkingen: Zelfs met perfect samengestelde prognosedatabases, zijn er vaak gegevensproblemen van het type "naald in een hooiberg". In deze gevallen zijn het niet de gegevensfouten, maar vraagafwijkingen die bijdragen aan de voorspellingsfout. In een set van bijvoorbeeld 50.000 producten is het waarschijnlijk dat een bepaald aantal artikelen vreemde details heeft die prognoses kunnen vertekenen.
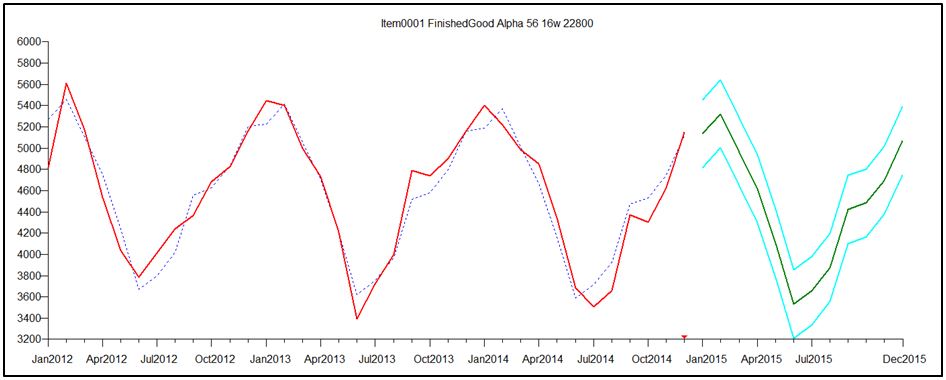
Holdout-analyse is een eenvoudige maar krachtige analysemethode. Om te zien hoe goed een methode voorspelt, gebruikt u deze met oudere bekende gegevens om nieuwere gegevens te voorspellen en ziet u vervolgens hoe het zou zijn uitgekomen! Stel dat u 36 maanden aan vraaggegevens heeft en 3 maanden vooruit moet voorspellen. U kunt het prognoseproces simuleren door de meest recente 3 maanden aan gegevens achter te houden (dwz te verbergen), prognoses te maken met alleen gegevens van maand 1 tot 33 en vervolgens de prognoses voor maanden 34-36 te vergelijken met de werkelijke waarden in maanden 34-36 . Glijdende simulatie herhaalt alleen de holdout-analyse en glijdt langs de vraaggeschiedenis. In het bovenstaande voorbeeld werden de gegevens van de eerste 33 maanden gebruikt om 3 schattingen van de voorspellingsfout te krijgen. Stel dat we het proces starten door de eerste 12 maanden te gebruiken om de volgende 3 te voorspellen. Dan schuiven we vooruit en gebruiken de eerste 13 maanden om de volgende 3 te voorspellen. We gaan door totdat we uiteindelijk de eerste 35 maanden gebruiken om de laatste maand te voorspellen, wat geeft ons nog een schatting van de fout die we maken bij het voorspellen van een maand vooruit. Een samenvatting van alle 1-stap vooruit, 2-stap vooruit en 3 stap vooruit voorspellingsfouten biedt een manier om voorspellingsintervallen te berekenen.
Voorspellingsintervallen berekenen
De laatste stap bij het berekenen van voorspellingsintervallen is het omzetten van de schattingen van de gemiddelde absolute fout in de boven- en ondergrenzen van het voorspellingsinterval. Het voorspellingsinterval op een willekeurig tijdstip in de toekomst wordt berekend als
Voorspellingsinterval = Voorspelling ± Vermenigvuldiger x Gemiddelde absolute fout.
De laatste stap is de keuze van de vermenigvuldiger. De typische benadering is om een kansverdeling van fouten rond de voorspelling voor te stellen en vervolgens de uiteinden van het voorspellingsinterval te schatten met behulp van de juiste percentielen van die verdeling. Gewoonlijk is de veronderstelde foutverdeling de normale verdeling, ook wel de Gaussische verdeling of de "klokvormige curve" genoemd.
Gebruik van voorspellingsintervallen
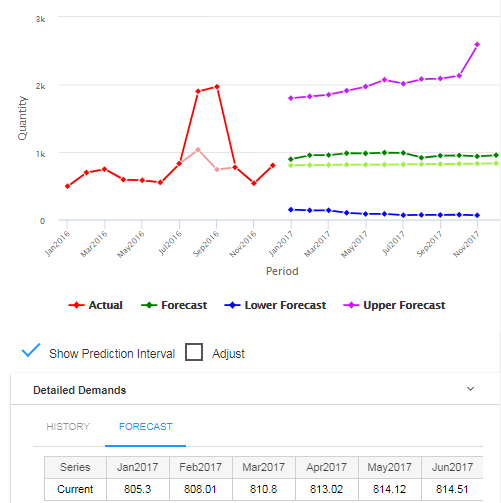
Het meest directe, informele gebruik van voorspellingsintervallen is om een idee te geven van hoe "squishy" een voorspelling is. Voorspellingsintervallen die breed zijn in vergelijking met de omvang van de prognoses wijzen op een grote onzekerheid.
Er zijn twee meer formele toepassingen bij vraagprognoses: het afdekken van uw weddenschappen over de toekomstige vraag en het begeleiden van prognoseaanpassingen.
Uw weddenschappen afdekken: De prognosewaarden zelf benaderen de meest waarschijnlijke waarden van de toekomstige vraag. Een meer onheilspellende manier om hetzelfde te zeggen is dat er een kans van ongeveer 50% is dat de werkelijke waarde boven (of onder) de voorspelling zal liggen. Als de prognose wordt gebruikt om toekomstige productie te plannen (of de aankoop of aanwerving van grondstoffen), wilt u misschien een buffer inbouwen om te voorkomen dat u tekort komt als de vraag piekt (ervan uitgaande dat onderbouw erger is dan overbouw). Als de prognose wordt geconverteerd van eenheden naar dollars voor omzetprognoses, wilt u misschien een waarde onder de prognose gebruiken om conservatief te zijn bij het projecteren van de cashflow. In beide gevallen moet u eerst de dekking van het voorspellingsinterval kiezen. Een 90%-voorspellingsinterval is een bereik van waarden dat 90% van de mogelijkheden dekt. Dit impliceert dat er een kans van 5% is dat een waarde boven de bovengrens van het 90%-voorspellingsinterval valt. Met andere woorden, de bovengrens van een 90%-voorspellingsinterval markeert het 95e percentiel van de verdeling van de voorspelde vraag in die periode. Evenzo is er een kans van 5% om onder de ondergrens te vallen, wat het 5e percentiel van de vraagverdeling markeert.
Begeleidende voorspellingsaanpassing: Het komt vrij vaak voor dat statistische prognoses worden herzien door een of ander samenwerkingsproces. Deze aanpassingen zijn gebaseerd op informatie die niet is vastgelegd in de vraaggeschiedenis van een item, zoals informatie over acties van concurrenten. Soms zijn ze gebaseerd op een meer vluchtige bron, zoals het optimisme van het verkoopteam. Wanneer de aanpassingen op het scherm worden aangebracht zodat iedereen ze kan zien, bieden de voorspellingsintervallen een nuttige referentie: als iemand de voorspellingen buiten de voorspellingsintervallen wil verplaatsen, overschrijden ze een op feiten gebaseerde grens en moeten ze een goed verhaal hebben om hun argument dat de dingen in de toekomst echt anders zullen zijn.
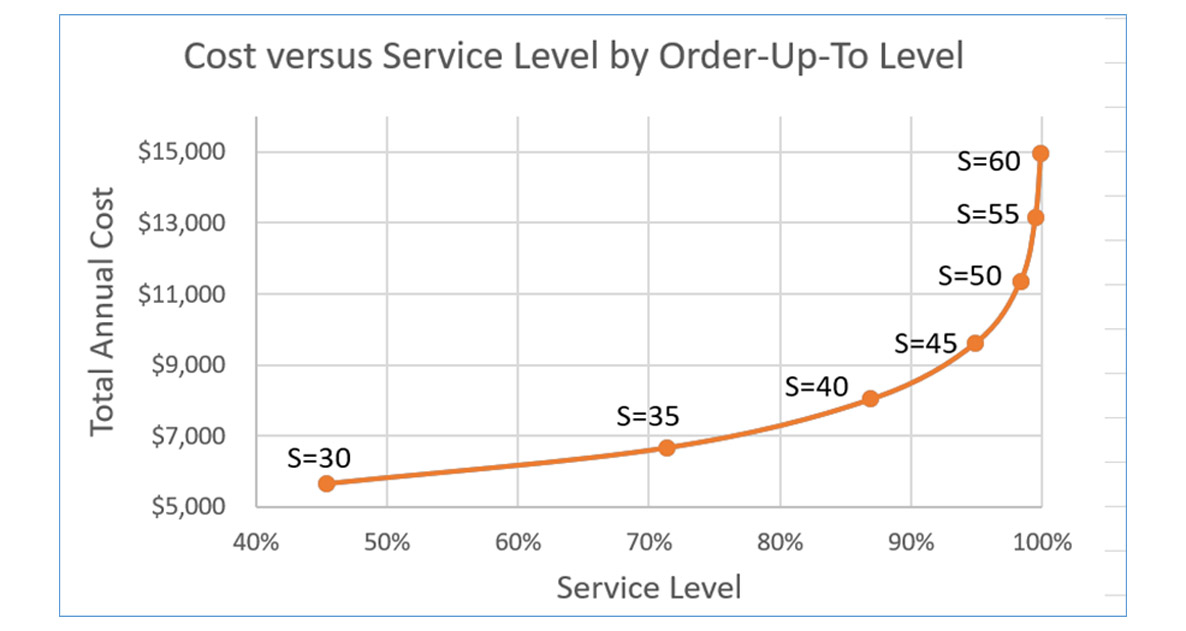
Voorspellingsintervallen en voorraadoptimalisatie
Ten slotte speelt het concept achter voorspellingsintervallen een essentiële rol in een probleem met betrekking tot vraagvoorspelling: Voorraad optimalisatie.
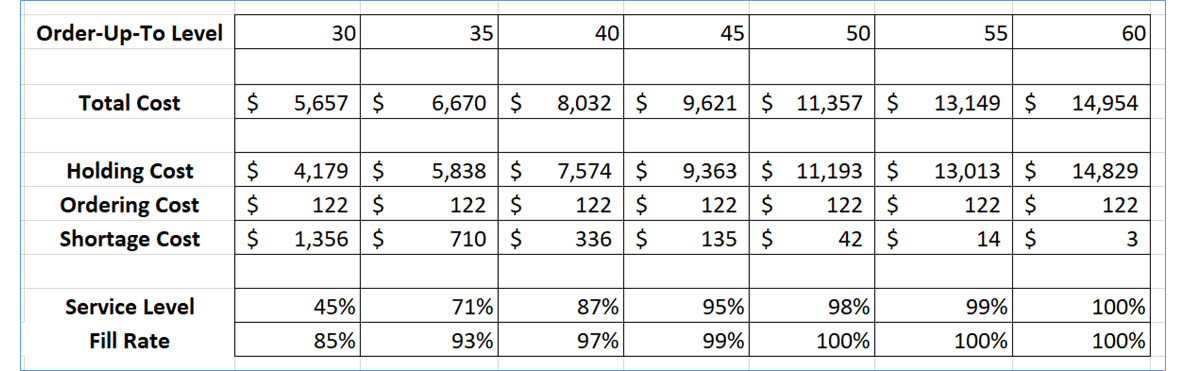
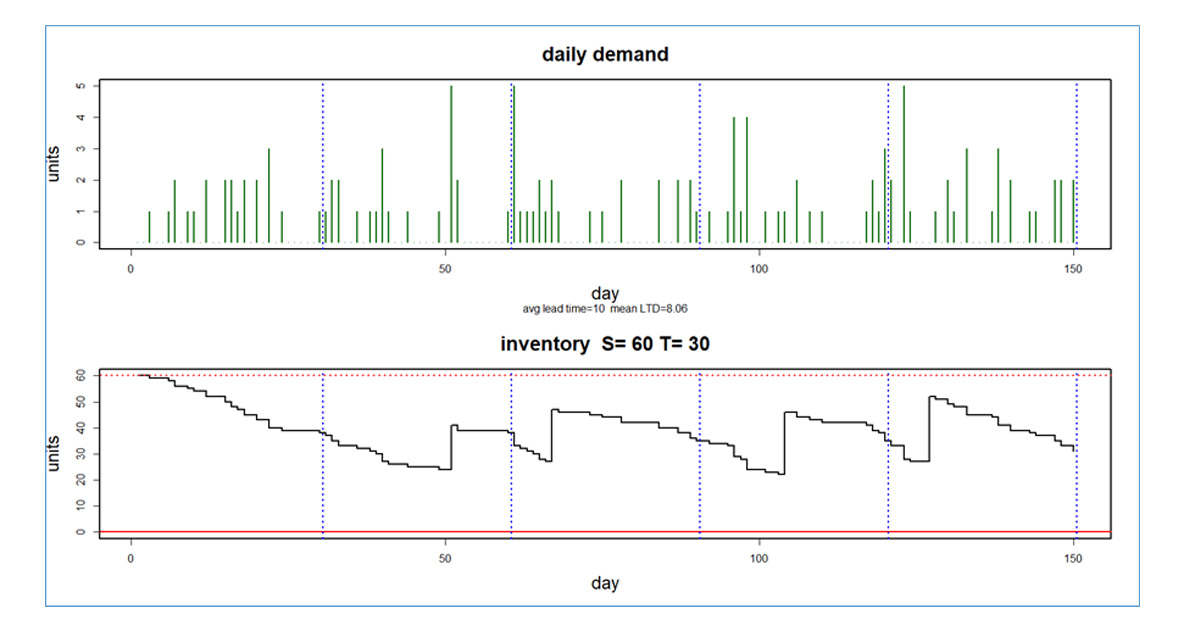
De belangrijkste analytische taak bij het instellen van bestelpunten (ook wel Mins genoemd) is het voorspellen van de totale vraag over een doorlooptijd voor aanvulling. Dit totaal wordt de doorlooptijdvraag genoemd. Wanneer de voorhanden voorraad daalt tot of onder het bestelpunt, wordt een aanvullingsorder geactiveerd. Als het bestelpunt hoog genoeg is, is er een acceptabel klein risico op voorraaduitval, dat wil zeggen dat de doorlooptijdvraag de voorraad onder nul brengt en leidt tot verloren verkopen of nabestellingen.
Nieuwe statistische methoden, en we kunnen effectiever gaan plannen.
De prognosetaak is het bepalen van alle mogelijke waarden van de cumulatieve vraag over de doorlooptijd en hun bijbehorende kansen van optreden. Met andere woorden, de basistaak is het bepalen van een voorspellingsinterval voor een toekomstige willekeurige variabele. Stel dat u een 90%-voorspellingsinterval hebt berekend voor de doorlooptijdvraag. Dan vertegenwoordigt de bovenkant van het interval het 95e percentiel van de verdeling. Door het bestelpunt op dit niveau in te stellen, is er plaats voor 95% van de mogelijke vraagwaarden voor de doorlooptijd, wat betekent dat er slechts een kans van 5% is dat de voorraad is uitgeput voordat de voorraad wordt aangevuld om de schappen opnieuw te bevoorraden. Er is dus een nauw verband tussen voorspellingsintervallen bij vraagprognoses en de berekening van bestelpunten bij voorraadoptimalisatie.
5 aanbevelingen voor de praktijk
1. Stel verwachtingen over fouten: Soms hebben managers onredelijke verwachtingen over het terugbrengen van prognosefouten tot nul. U kunt erop wijzen dat fouten slechts één van de dimensies is waarop een prognoseproces moet worden beoordeeld; het kan goed gaan met zowel tijdigheid als kosten. Wijs er ook op dat nul fouten evenmin een realistischer doel is dan 100% conversie van prospects naar klanten, perfecte leveranciersprestaties of nul volatiliteit van aandelenkoersen.
2. Spoor bronnen van fouten op: controleer de nauwkeurigheid van vraaggeschiedenissen. Gebruik statistische methoden om uitschieters in vraaggeschiedenissen te identificeren en gepast te reageren, geverifieerde anomalieën te vervangen door meer typische waarden en gegevens weg te laten van vóór grote veranderingen in de aard van de vraag. Als u een gezamenlijk prognoseproces gebruikt, vergelijkt u de nauwkeurigheid ervan met een puur statistische benadering om items te identificeren waarvoor samenwerking de fouten niet vermindert.
3. Evalueer de fout van alternatieve statistische methoden: er kunnen kant-en-klare technieken zijn die het beter doen dan uw huidige methoden, of het beter doen voor sommige subsets van uw items. De sleutel is om empirisch te zijn, gebruikmakend van het idee van holdout-analyse. Verzamel uw gegevens en doe een "bake off" tussen verschillende methoden om te zien welke voor u beter werken. Als u nog geen statistische prognosemethoden gebruikt, vergelijk ze dan met de "gouden buik" van uw huidige standaard. Gebruik de naïeve voorspelling als maatstaf in de vergelijkingen.
4. Onderzoek het gebruik van nieuwe gegevensbronnen: Vooral als u items heeft die veel gepromoot worden, test u statistische methoden die promotionele gegevens opnemen in het prognoseproces. Ga ook na of er misbruik kan worden gemaakt van informatie van buiten uw bedrijf; kijk bijvoorbeeld of macro-economische indicatoren voor uw sector kunnen worden gecombineerd met bedrijfsgegevens om de nauwkeurigheid van prognoses te verbeteren (dit wordt meestal gedaan met behulp van een methode die meervoudige regressieanalyse wordt genoemd).
5. Gebruik voorspellingsintervallen: Plots van voorspellingsintervallen kunnen uw gevoel voor de onzekerheid in uw prognoses verbeteren, waardoor u items kunt selecteren voor extra onderzoek. Hoewel het waar is dat wat je niet weet je pijn kan doen, is het ook waar dat weten wat je niet weet je kan helpen.

gerelateerde berichten

Je moet samenwerken met de algoritmen
Dit artikel gaat over de echte kracht die voortkomt uit de samenwerking tussen u en onze software die binnen handbereik plaatsvindt. We schrijven vaak over de software zelf en wat er ‘onder de motorkap’ gebeurt. Deze keer is het onderwerp hoe je het beste met de software kunt samenwerken.

Het gebruik van belangrijke prestatievoorspellingen om het voorraadbeleid te plannen
Ik kan me niet voorstellen dat ik een voorraadplanner ben op het gebied van reserveonderdelen, distributie of productie en dat ik veiligheidsvoorraden, bestelpunten en bestelsuggesties moet creëren zonder gebruik te maken van belangrijke prestatievoorspellingen van serviceniveaus, opvullingspercentages en voorraadkosten.

Belangrijkste verschillen tussen voorraadplanning voor eindproducten en voor MRO en reserveonderdelen
In het huidige competitieve zakelijke landschap zijn bedrijven voortdurend op zoek naar manieren om hun operationele efficiëntie te verbeteren en meer inkomsten te genereren. Het optimaliseren van het beheer van serviceonderdelen is een vaak over het hoofd gezien aspect dat een aanzienlijke financiële impact kan hebben. Bedrijven kunnen de algehele efficiëntie verbeteren en aanzienlijke financiële opbrengsten genereren door de voorraad reserveonderdelen effectief te beheren. Dit artikel gaat in op de economische implicaties van geoptimaliseerd beheer van serviceonderdelen en hoe investeren in software voor voorraadoptimalisatie en vraagplanning een concurrentievoordeel kan opleveren.
recente berichten
 Het beheren van de voorraad reserveonderdelen: beste praktijkenIn this blog, we’ll explore several effective strategies for managing spare parts inventory, emphasizing the importance of optimizing stock levels, maintaining service levels, and using smart tools to aid in decision-making. Managing spare parts inventory is a critical component for businesses that depend on equipment uptime and service reliability. Unlike regular inventory items, spare parts often have unpredictable demand patterns, making them more challenging to manage effectively. An efficient spare parts inventory management system helps prevent stockouts that can lead to operational downtime and costly delays while also avoiding overstocking that unnecessarily ties up capital and increases holding costs. […]
Het beheren van de voorraad reserveonderdelen: beste praktijkenIn this blog, we’ll explore several effective strategies for managing spare parts inventory, emphasizing the importance of optimizing stock levels, maintaining service levels, and using smart tools to aid in decision-making. Managing spare parts inventory is a critical component for businesses that depend on equipment uptime and service reliability. Unlike regular inventory items, spare parts often have unpredictable demand patterns, making them more challenging to manage effectively. An efficient spare parts inventory management system helps prevent stockouts that can lead to operational downtime and costly delays while also avoiding overstocking that unnecessarily ties up capital and increases holding costs. […] 5 manieren om de snelheid van beslissingen in de toeleveringsketen te verbeterenDe belofte van een digitale supply chain heeft de manier waarop bedrijven opereren getransformeerd. In de kern kan het snelle, datagestuurde beslissingen nemen en tegelijkertijd kwaliteit en efficiëntie in de hele bedrijfsvoering garanderen. Het gaat echter niet alleen om toegang tot meer data. Organisaties hebben de juiste tools en platforms nodig om die data om te zetten in bruikbare inzichten. Dit is waar besluitvorming cruciaal wordt, vooral in een landschap waar nieuwe digitale supply chain-oplossingen en AI-gestuurde platforms u kunnen ondersteunen bij het stroomlijnen van veel processen binnen de beslissingsmatrix. […]
5 manieren om de snelheid van beslissingen in de toeleveringsketen te verbeterenDe belofte van een digitale supply chain heeft de manier waarop bedrijven opereren getransformeerd. In de kern kan het snelle, datagestuurde beslissingen nemen en tegelijkertijd kwaliteit en efficiëntie in de hele bedrijfsvoering garanderen. Het gaat echter niet alleen om toegang tot meer data. Organisaties hebben de juiste tools en platforms nodig om die data om te zetten in bruikbare inzichten. Dit is waar besluitvorming cruciaal wordt, vooral in een landschap waar nieuwe digitale supply chain-oplossingen en AI-gestuurde platforms u kunnen ondersteunen bij het stroomlijnen van veel processen binnen de beslissingsmatrix. […] 12 Oorzaken van Overstocking en Praktische OplossingenEffectief voorraadbeheer is cruciaal voor het behouden van een gezonde balans en het verzekeren dat middelen optimaal worden toegewezen. Hier is een diepgaande verkenning van de belangrijkste oorzaken van overstocking, hun implicaties en mogelijke oplossingen. […]
12 Oorzaken van Overstocking en Praktische OplossingenEffectief voorraadbeheer is cruciaal voor het behouden van een gezonde balans en het verzekeren dat middelen optimaal worden toegewezen. Hier is een diepgaande verkenning van de belangrijkste oorzaken van overstocking, hun implicaties en mogelijke oplossingen. […] FAQ: Slimme IP&O voor beter voorraadbeheer.Effectief supply chain- en voorraadbeheer zijn essentieel voor het bereiken van operationele efficiëntie en klanttevredenheid. Deze blog biedt duidelijke en beknopte antwoorden op enkele basisvragen en andere veelvoorkomende vragen van onze Smart IP&O-klanten, en biedt praktische inzichten om typische uitdagingen te overwinnen en uw voorraadbeheerpraktijken te verbeteren. Met de focus op deze belangrijke gebieden helpen we u complexe voorraadproblemen om te zetten in strategische, beheersbare acties die kosten verlagen en de algehele prestaties verbeteren met Smart IP&O. […]
FAQ: Slimme IP&O voor beter voorraadbeheer.Effectief supply chain- en voorraadbeheer zijn essentieel voor het bereiken van operationele efficiëntie en klanttevredenheid. Deze blog biedt duidelijke en beknopte antwoorden op enkele basisvragen en andere veelvoorkomende vragen van onze Smart IP&O-klanten, en biedt praktische inzichten om typische uitdagingen te overwinnen en uw voorraadbeheerpraktijken te verbeteren. Met de focus op deze belangrijke gebieden helpen we u complexe voorraadproblemen om te zetten in strategische, beheersbare acties die kosten verlagen en de algehele prestaties verbeteren met Smart IP&O. […] 7 belangrijke trends in vraagplanning die de toekomst vormgevenVraagplanning gaat verder dan alleen het voorspellen van productbehoeften; het gaat erom ervoor te zorgen dat uw bedrijf nauwkeurig, efficiënt en kosteneffectief aan de vraag van klanten voldoet. De nieuwste technologie voor vraagplanning pakt belangrijke uitdagingen aan, zoals nauwkeurigheid van voorspellingen, voorraadbeheer en marktresponsiviteit. In deze blog introduceren we kritieke trends voor vraagplanning, waaronder datagestuurde inzichten, probabilistische voorspellingen, consensusplanning, voorspellende analyses, scenariomodellering, realtime zichtbaarheid en multilevel voorspellingen. Deze trends helpen u om voorop te blijven lopen, uw toeleveringsketen te optimaliseren, kosten te verlagen en de klanttevredenheid te verbeteren, waardoor uw bedrijf op de lange termijn succesvol wordt. […]
7 belangrijke trends in vraagplanning die de toekomst vormgevenVraagplanning gaat verder dan alleen het voorspellen van productbehoeften; het gaat erom ervoor te zorgen dat uw bedrijf nauwkeurig, efficiënt en kosteneffectief aan de vraag van klanten voldoet. De nieuwste technologie voor vraagplanning pakt belangrijke uitdagingen aan, zoals nauwkeurigheid van voorspellingen, voorraadbeheer en marktresponsiviteit. In deze blog introduceren we kritieke trends voor vraagplanning, waaronder datagestuurde inzichten, probabilistische voorspellingen, consensusplanning, voorspellende analyses, scenariomodellering, realtime zichtbaarheid en multilevel voorspellingen. Deze trends helpen u om voorop te blijven lopen, uw toeleveringsketen te optimaliseren, kosten te verlagen en de klanttevredenheid te verbeteren, waardoor uw bedrijf op de lange termijn succesvol wordt. […]

Voorraadoptimalisatie voor fabrikanten, distributeurs en MRO
- Het beheren van de voorraad reserveonderdelen: beste praktijkenIn this blog, we’ll explore several effective strategies for managing spare parts inventory, emphasizing the importance of optimizing stock levels, maintaining service levels, and using smart tools to aid in decision-making. Managing spare parts inventory is a critical component for businesses that depend on equipment uptime and service reliability. Unlike regular inventory items, spare parts often have unpredictable demand patterns, making them more challenging to manage effectively. An efficient spare parts inventory management system helps prevent stockouts that can lead to operational downtime and costly delays while also avoiding overstocking that unnecessarily ties up capital and increases holding costs. […]
 Innovatie van de OEM-aftermarket met AI-gestuurde voorraadoptimalisatieDe aftermarketsector biedt OEM's een beslissend voordeel door een stabiele inkomstenstroom te bieden en de loyaliteit van klanten te bevorderen door de betrouwbare en tijdige levering van serviceonderdelen. Het beheren van inventaris en het voorspellen van de vraag in de aftermarket gaat echter gepaard met uitdagingen, waaronder onvoorspelbare vraagpatronen, enorme productassortimenten en de noodzaak van snelle doorlooptijden. Traditionele methoden schieten vaak tekort vanwege de complexiteit en variabiliteit van de vraag in de aftermarket. De nieuwste technologieën kunnen grote datasets analyseren om de toekomstige vraag nauwkeuriger te voorspellen en voorraadniveaus te optimaliseren, wat leidt tot betere service en lagere kosten. […]
Innovatie van de OEM-aftermarket met AI-gestuurde voorraadoptimalisatieDe aftermarketsector biedt OEM's een beslissend voordeel door een stabiele inkomstenstroom te bieden en de loyaliteit van klanten te bevorderen door de betrouwbare en tijdige levering van serviceonderdelen. Het beheren van inventaris en het voorspellen van de vraag in de aftermarket gaat echter gepaard met uitdagingen, waaronder onvoorspelbare vraagpatronen, enorme productassortimenten en de noodzaak van snelle doorlooptijden. Traditionele methoden schieten vaak tekort vanwege de complexiteit en variabiliteit van de vraag in de aftermarket. De nieuwste technologieën kunnen grote datasets analyseren om de toekomstige vraag nauwkeuriger te voorspellen en voorraadniveaus te optimaliseren, wat leidt tot betere service en lagere kosten. […] Toekomstbestendige hulpprogramma's: geavanceerde analyses voor optimalisatie van de supply chainNutsvoorzieningen op het gebied van elektriciteit, aardgas, stedelijk water en telecommunicatie zijn allemaal activa-intensief en afhankelijk van fysieke infrastructuur die in de loop van de tijd goed moet worden onderhouden, bijgewerkt en geüpgraded. Het maximaliseren van de uptime van bedrijfsmiddelen en de betrouwbaarheid van de fysieke infrastructuur vereist effectief voorraadbeheer, prognoses van reserveonderdelen en leveranciersbeheer. Een nutsbedrijf dat deze processen effectief uitvoert, presteert beter dan zijn concurrenten, levert een beter rendement op voor zijn investeerders en hogere serviceniveaus voor zijn klanten, terwijl het zijn impact op het milieu vermindert. […]
Toekomstbestendige hulpprogramma's: geavanceerde analyses voor optimalisatie van de supply chainNutsvoorzieningen op het gebied van elektriciteit, aardgas, stedelijk water en telecommunicatie zijn allemaal activa-intensief en afhankelijk van fysieke infrastructuur die in de loop van de tijd goed moet worden onderhouden, bijgewerkt en geüpgraded. Het maximaliseren van de uptime van bedrijfsmiddelen en de betrouwbaarheid van de fysieke infrastructuur vereist effectief voorraadbeheer, prognoses van reserveonderdelen en leveranciersbeheer. Een nutsbedrijf dat deze processen effectief uitvoert, presteert beter dan zijn concurrenten, levert een beter rendement op voor zijn investeerders en hogere serviceniveaus voor zijn klanten, terwijl het zijn impact op het milieu vermindert. […] Centreringswet: timing, prijzen en betrouwbaarheid van reserveonderdelenIn dit artikel begeleiden we u bij het opstellen van een voorraadplan voor reserveonderdelen, waarbij prioriteit wordt gegeven aan beschikbaarheidsstatistieken zoals serviceniveaus en vulpercentages, terwijl de kostenefficiëntie wordt gewaarborgd. We zullen ons concentreren op een benadering van voorraadplanning genaamd Service Level-Driven Inventory Optimization. Vervolgens bespreken we hoe u kunt bepalen welke onderdelen u in uw inventaris moet opnemen en welke onderdelen mogelijk niet nodig zijn. Ten slotte onderzoeken we manieren om uw op serviceniveau gebaseerde voorraadplan consistent te verbeteren. […]
Centreringswet: timing, prijzen en betrouwbaarheid van reserveonderdelenIn dit artikel begeleiden we u bij het opstellen van een voorraadplan voor reserveonderdelen, waarbij prioriteit wordt gegeven aan beschikbaarheidsstatistieken zoals serviceniveaus en vulpercentages, terwijl de kostenefficiëntie wordt gewaarborgd. We zullen ons concentreren op een benadering van voorraadplanning genaamd Service Level-Driven Inventory Optimization. Vervolgens bespreken we hoe u kunt bepalen welke onderdelen u in uw inventaris moet opnemen en welke onderdelen mogelijk niet nodig zijn. Ten slotte onderzoeken we manieren om uw op serviceniveau gebaseerde voorraadplan consistent te verbeteren. […]