Wat is al die heisa rond de term 'probabilistische prognoses'? Is het gewoon een recentere marketingterm die sommige softwareleveranciers en consultants hebben bedacht om innovatie te veinzen? Is er een echt tastbaar verschil in vergelijking met voorgaande "best passende" technieken? Zijn toch niet alle voorspellingen probabilistisch?
Om deze vraag te beantwoorden, is het nuttig om na te denken over wat de voorspelling u werkelijk vertelt in termen van kansen. Een "goede" voorspelling moet onbevooroordeeld zijn en daarom een 50/50 waarschijnlijkheid opleveren die hoger of lager is dan de werkelijke. Een "slechte" voorspelling zal subjectieve buffers inbouwen (of de voorspelling kunstmatig verlagen) en resulteren in een hoge of lage vraag. Overweeg een verkoper die opzettelijk zijn prognose verlaagt door geen verkopen te rapporteren die hij verwacht te sluiten als 'conservatief'. Hun voorspellingen zullen een negatieve voorspellingsbias hebben, aangezien de werkelijke waarden bijna altijd hoger zullen zijn dan wat ze voorspelden. Overweeg aan de andere kant een klant die een opgeblazen prognose aan zijn fabrikant geeft. Bezorgd over stockouts, overschatten ze de vraag om hun aanbod zeker te stellen. Hun voorspelling zal een positieve bias hebben, aangezien de werkelijke waarden bijna altijd lager zullen zijn dan wat ze voorspelden.
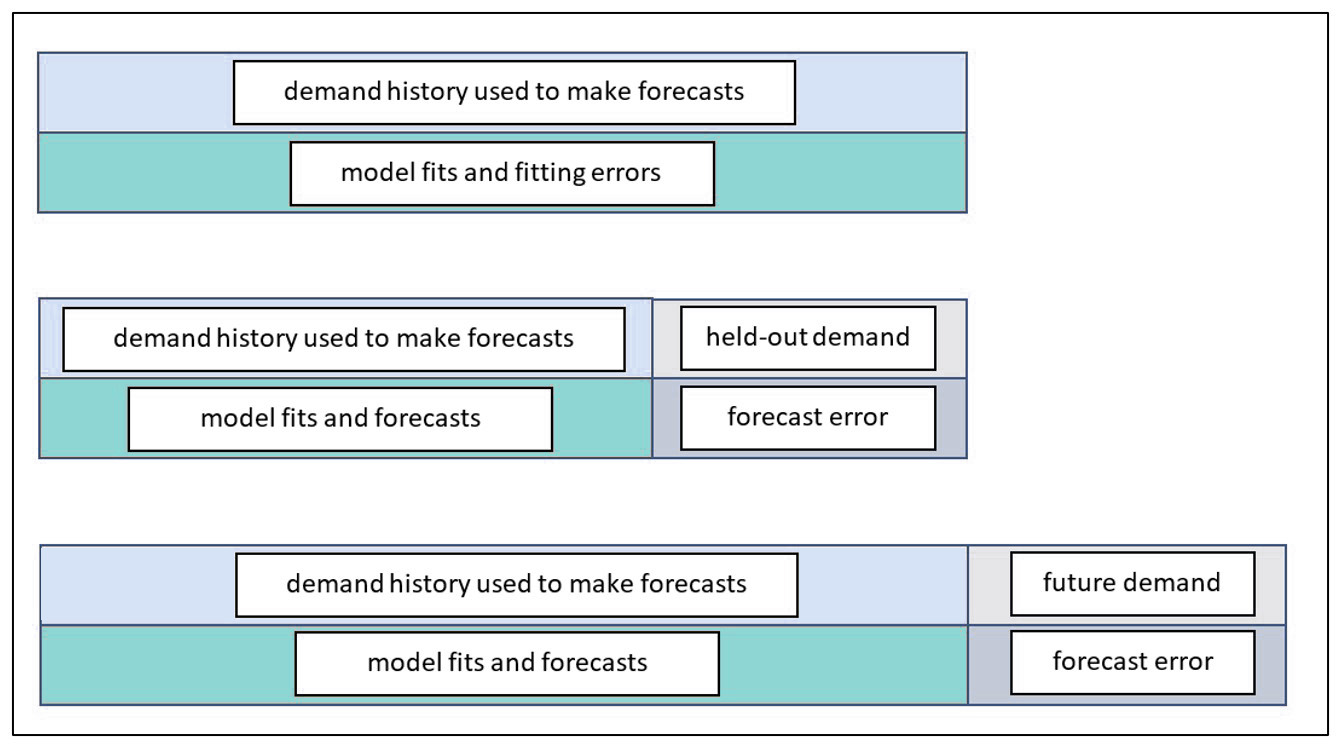
Dit soort ééncijferige voorspellingen die hierboven zijn beschreven, zijn problematisch. We verwijzen naar deze voorspellingen als "puntvoorspellingen", omdat ze één punt (of een reeks punten in de tijd) vertegenwoordigen op een plot van wat er in de toekomst zou kunnen gebeuren. Ze geven geen volledig beeld, want om effectieve zakelijke beslissingen te nemen, zoals het bepalen hoeveel voorraad er moet worden opgeslagen of het aantal werknemers dat beschikbaar moet zijn om aan de vraag te voldoen, is gedetailleerde informatie vereist over hoeveel lager of hoger de werkelijke waarde zal zijn! Met andere woorden, u hebt de kansen nodig voor elke mogelijke uitkomst die zich kan voordoen. Dus op zichzelf is de puntvoorspelling niet probabilistisch.
Om een probabilistische voorspelling te krijgen, moet u de verdeling van mogelijke eisen rond die voorspelling kennen. Zodra u dit hebt berekend, wordt de voorspelling 'probabilistisch'. Hoe prognosesystemen en beoefenaars zoals vraagplanners, voorraadanalisten, materiaalmanagers en CFO's deze waarschijnlijkheden bepalen, is de kern van de vraag: "wat maakt een prognose probabilistisch?"
Normale verdelingen
De meeste prognoses en de systemen/software die ze produceren, beginnen met een voorspelling van de vraag. Vervolgens berekenen ze het bereik van mogelijke eisen rond die voorspelling door onjuiste theoretische aannames te doen over de verdeling. Als u ooit een "betrouwbaarheidsinterval" in uw voorspellingssoftware hebt gebruikt, is dit gebaseerd op een kansverdeling rond de voorspelling. De manier waarop dit vraagbereik wordt bepaald, is door uit te gaan van een bepaald type distributie. Meestal betekent dit dat we uitgaan van een klokvormige verdeling, ook wel bekend als een normale verdeling. Wanneer de vraag intermitterend is, kunnen sommige systemen voor voorraadoptimalisatie en vraagvoorspelling aannemen dat de vraag Poisson-vormig is.
Nadat de prognose is gemaakt, wordt de veronderstelde verdeling rond de vraagprognose gegooid en hebt u uw schatting van kansen voor elke mogelijke vraag - dat wil zeggen, een "probabilistische prognose". Deze schattingen van de vraag en de bijbehorende waarschijnlijkheden kunnen vervolgens worden gebruikt om desgewenst extreme waarden of iets daartussenin te bepalen. De extreme waarden in de bovenste percentielen van de distributie (dwz 92%, 95%, 99%, enz.) worden meestal gebruikt als invoer voor voorraadbeheermodellen. Bestelpunten voor kritieke reserveonderdelen in een elektriciteitsbedrijf kunnen bijvoorbeeld worden gepland op basis van een 99.5%-serviceniveau of zelfs hoger. Terwijl een niet-kritiek serviceonderdeel kan worden gepland op een 85%- of 90%-serviceniveau.
Het probleem met het maken van aannames over de verdeling is dat je deze kansen verkeerd zult interpreteren. Als de vraag bijvoorbeeld niet normaal verdeeld is, maar u een klokvormige/normale curve op de voorspelling afdwingt, hoe kan het dan dat de kansen onjuist zijn. In het bijzonder wilt u misschien het voorraadniveau weten dat nodig is om een 99%-kans te bereiken dat de voorraad niet opraakt en de normale distributie zal u vertellen om 200 eenheden in voorraad te hebben. Maar als je het vergelijkt met de daadwerkelijke vraag, kom je erachter dat 200 eenheden slechts in 40/50 waarnemingen volledig aan de vraag voldeden. Dus in plaats van een 99%-serviceniveau te krijgen, behaalde u alleen een 80%-serviceniveau! Dit is een gigantische misser die het gevolg is van het proberen een vierkante pin in een rond gat te passen. De misser zou ertoe hebben geleid dat u een onjuiste voorraadvermindering had genomen.
Empirisch geschatte verdelingen zijn slim
Om een slimme (lees nauwkeurige) probabilistische voorspelling te maken, moet u eerst de verdeling van de vraag empirisch schatten zonder enige naïeve aannames over de vorm van de verdeling. Smart Software doet dit door tienduizenden gesimuleerde vraag- en doorlooptijdscenario's uit te voeren. Onze oplossing maakt gebruik van gepatenteerde technieken die Monte Carlo-simulatie, statistische bootstrapping en andere methoden bevatten. De scenario's zijn ontworpen om reële onzekerheid en willekeur van zowel vraag als doorlooptijden te simuleren. Actuele historische waarnemingen worden gebruikt als de primaire invoer, maar de oplossing geeft u de mogelijkheid om ook te simuleren van niet-waargenomen waarden. Alleen al omdat 100 eenheden de historische piekvraag was, wil dat nog niet zeggen dat u in de toekomst gegarandeerd op 100 piekt. Nadat de scenario's zijn voltooid, weet u de exacte waarschijnlijkheid voor elke uitkomst. De "punt"-voorspelling wordt dan het middelpunt van die verdeling. Elke toekomstige periode in de tijd wordt uitgedrukt in termen van de kansverdeling die bij die periode hoort.
Leiders in probabilistische prognoses
Smart Software, Inc. was twintig jaar geleden het eerste bedrijf dat ooit statistische bootstrapping introduceerde als onderdeel van een commercieel verkrijgbaar softwaresysteem voor vraagvoorspelling. We kregen er destijds een Amerikaans patent voor en werden finalist genoemd in de APICS Corporate Awards of Excellence for Technological Innovation. Ons NSF gesponsord onderzoek die tot deze en andere ontdekkingen leidden, speelden een belangrijke rol bij het bevorderen van prognoses en voorraadoptimalisatie. Wij zetten ons in voor voortdurende innovatie, en dat kunt u ook vind hier meer informatie over ons meest recente patent.