Hier zijn voorbeelden van prognoseproblemen die SmartForecasts kan oplossen, samen met de soorten bedrijfsgegevens die representatief zijn voor elk.
Een item voorspellen op basis van het patroon
Welke omzet kunt u, gegeven de volgende zes kwartaalverkoopcijfers, verwachten voor het derde en vierde kwartaal van 2023?

Verkoop per kwartaal
SmartForecasts biedt u vele manieren om dit probleem aan te pakken. U kunt uw eigen statistische prognoses maken met een van de zes verschillende Exponential smoothing en Moving average methoden. Of, zoals de meeste niet-technische voorspellers, kunt u de tijdbesparende automatische opdracht gebruiken, die is geprogrammeerd om automatisch de meest nauwkeurige methode voor uw gegevens te selecteren en te gebruiken. Ten slotte kunt u, om uw zakelijke oordeel in het prognoseproces op te nemen, elk statistisch prognoseresultaat grafisch aanpassen met behulp van SmartForecasts' "oogbol" aanpassing mogelijkheden.
Een item voorspellen op basis van zijn relatie met andere variabelen.
Gezien de volgende historische relatie tussen de verkoop per eenheid en het aantal vertegenwoordigers, welke verkoopniveaus kunt u verwachten wanneer de geplande toename van het verkooppersoneel plaatsvindt in de laatste twee kwartalen van 2023?

Verkoop en verkoopvertegenwoordigers per kwartaal
U kunt een vraag als deze beantwoorden met behulp van het krachtige SmartForecasts Regressie commando, speciaal ontworpen om prognosetoepassingen te vergemakkelijken die oplossingen voor regressieanalyse vereisen. Regressiemodellen met een vrijwel onbeperkt aantal onafhankelijke/voorspellersvariabelen zijn mogelijk, hoewel de meeste bruikbare regressiemodellen slechts een handvol voorspellers gebruiken.
Gelijktijdig een aantal productitems en hun totaal voorspellen
Gegeven de volgende totale verkoop voor alle overhemden en de verdeling van de verkoop per kleur, wat zal de individuele en totale verkoop zijn in de komende zes maanden?
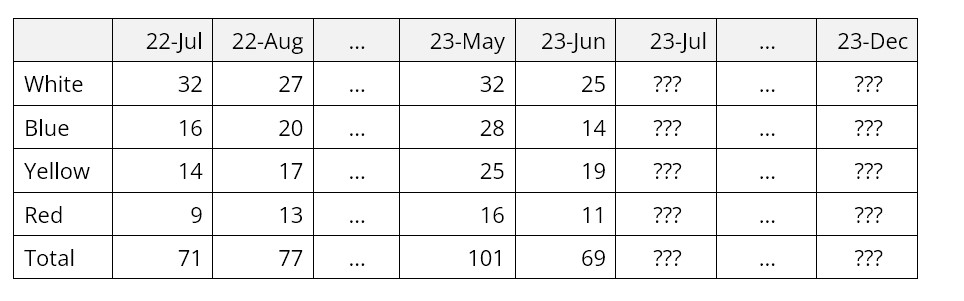
Maandelijkse verkoop van overhemden per kleur
De unieke Group Forecasting-functies van SmartForecasts voorspellen automatisch en gelijktijdig nauw verwante tijdreeksen, zoals deze artikelen in dezelfde productgroep. Dit bespaart veel tijd en levert prognoseresultaten op, niet alleen voor de afzonderlijke artikelen, maar ook voor het totaal. "Eyeball"-aanpassingen op zowel item- als groepsniveau zijn eenvoudig te maken. U kunt snel prognoses maken voor productgroepen met honderden of zelfs duizenden artikelen.
Automatisch duizenden items voorspellen
Wat kunt u verwachten van de vraag in de komende zes maanden voor elk van de 5.000 SKU's, gegeven het volgende record van productvraag op SKU-niveau?
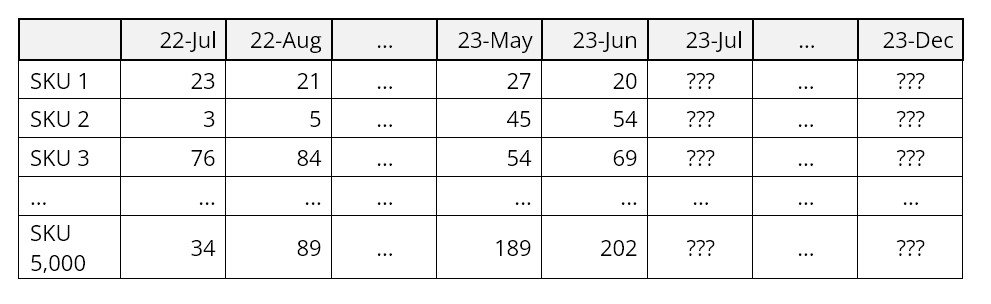
Maandelijkse productvraag per SKU (Stock Keeping Unit)
In slechts een paar minuten kan de krachtige automatische selectie van SmartForecasts een prognosetaak van deze omvang uitvoeren, de gegevens over de productvraag lezen, automatisch statistische prognoses voor elke SKU maken en het resultaat opslaan. De resultaten zijn vervolgens klaar voor export naar uw ERP-systeem met behulp van een van onze API-gebaseerde connectoren of via bestandsexport. Eenmaal ingesteld, worden er automatisch elke planningscyclus prognoses gemaakt zonder tussenkomst van de gebruiker.
Voorspelling van de vraag die meestal nul is
Een apart en vooral uitdagend type data om te voorspellen is periodieke vraag, die meestal nul is, maar op willekeurige tijdstippen omhoog springt naar willekeurige waarden die niet gelijk zijn aan nul. Dit patroon is typerend voor de vraag naar langzaam in beweging items, zoals service-onderdelen of groot ticket kapitaalgoederen.
Kijk bijvoorbeeld eens naar het volgende voorbeeld van de vraag naar serviceonderdelen voor vliegtuigen. Let op het overwicht van nulwaarden met niet-nulwaarden vermengd, vaak in bursts.
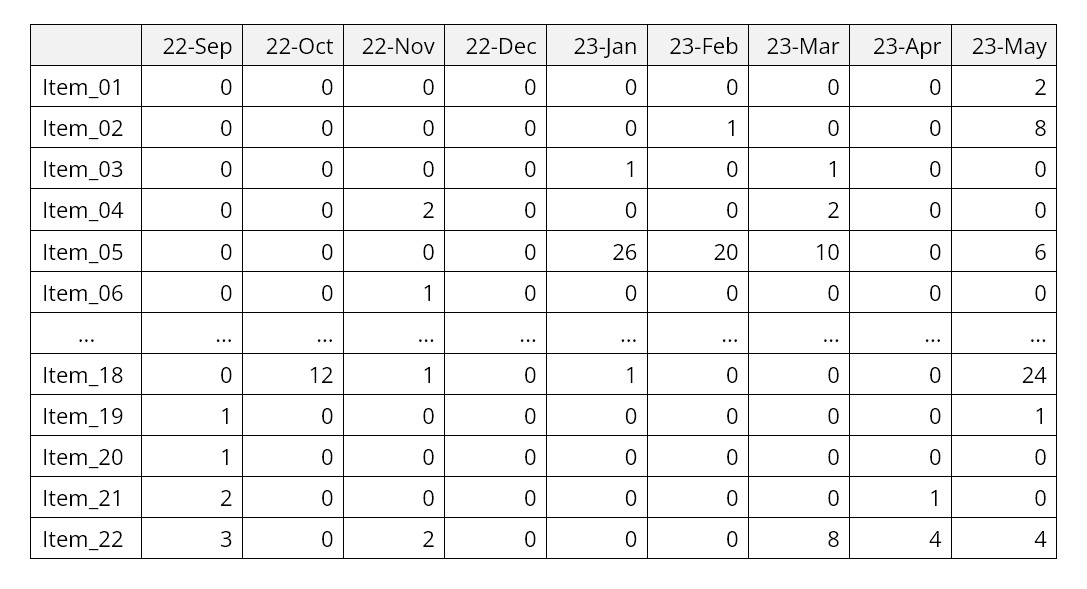
SmartForecasts heeft een unieke methode die speciaal is ontworpen voor dit soort data: de functie Intermittent Demand forecasting. Aangezien intermitterende vraag het vaakst ontstaat in de context van voorraadbeheer, richt deze functie zich op het voorspellen van het bereik van waarschijnlijke waarden voor de totale vraag gedurende een doorlooptijd, bijvoorbeeld de cumulatieve vraag over de periode van 23 juni tot 23 augustus in het bovenstaande voorbeeld .
Voorspellen van voorraadbehoeften
Het voorspellen van voorraadvereisten is een gespecialiseerde variant van prognoses die zich richt op de bovenkant van het bereik van mogelijke toekomstige waarden.
Overweeg voor de eenvoud het probleem van het voorspellen van voorraadbehoeften voor slechts één periode vooruit, bijvoorbeeld één dag vooruit. Gewoonlijk is de prognosetaak het schatten van het meest waarschijnlijke of gemiddelde niveau van de productvraag. Als de beschikbare voorraad echter gelijk is aan de gemiddelde vraag, is er een kans van ongeveer 50% dat de vraag de voorraad overtreft, wat resulteert in omzetverlies en/of goodwill. Het voorraadniveau instellen op bijvoorbeeld tien keer de gemiddelde vraag zal waarschijnlijk het probleem van stockouts elimineren, maar zal net zo zeker resulteren in opgeblazen voorraadkosten.
De truc van voorraadoptimalisatie is om een bevredigende balans te vinden tussen voldoende voorraad hebben om aan de meeste vraag te voldoen zonder al te veel middelen in het proces vast te leggen. Meestal is de oplossing een combinatie van zakelijk inzicht en statistieken. Het beoordelende deel is het definiëren van een acceptabel voorraadserviceniveau, zoals het direct uit voorraad voldoen aan 95% vraag. Het statistische deel is om het 95e percentiel van de vraag te schatten.
Wanneer niet omgaan met Intermittent demand, schat SmartForecasts het vereiste voorraadniveau door uit te gaan van een klokvormige (normale) vraagcurve, zowel het midden als de breedte van de klokcurve te schatten en vervolgens een standaard statistische formule te gebruiken om het gewenste percentiel te schatten. Het verschil tussen het gewenste voorraadniveau en het gemiddelde niveau van de vraag wordt de veiligheidsvoorraad genoemd omdat het beschermt tegen de mogelijkheid van stockouts.
Bij intermitterende vraag is de klokvormige curve een slechte benadering van de statistische verdeling van de vraag. In dit speciale geval gebruikt SmartForecasts gepatenteerde intermitterende vraagvoorspellingstechnologie om het vereiste voorraadserviceniveau te schatten.
