In bijna elk bedrijf en elke sector hebben besluitvormers betrouwbare voorspellingen nodig van kritische variabelen, zoals omzet, inkomsten, vraag naar producten, voorraadniveaus, marktaandeel, kosten en trends in de sector.
Er zijn veel soorten mensen die deze voorspellingen doen. Sommigen zijn geavanceerde technische analisten, zoals bedrijfseconomen en statistici. Vele anderen beschouwen forecasting als een belangrijk onderdeel van hun totale werk: algemeen managers, productieplanners, voorraadbeheerspecialisten, financiële analisten, strategische planners, marktonderzoekers en product- en verkoopmanagers. Toch beschouwen anderen zichzelf zelden als voorspellers, maar moeten ze vaak voorspellingen doen op een intuïtieve, oordelende basis.
Door de manier waarop we Smart Demand Planner hebben ontworpen, heeft het alle soorten voorspellers iets te bieden. Dit ontwerp komt voort uit verschillende observaties over het voorspellingsproces. Omdat we Smart Demand Planner met deze observaties in gedachten hebben ontworpen, zijn we van mening dat de stijl en inhoud ervan uniek geschikt zijn om van uw browser een effectief prognose- en planningshulpmiddel te maken:
Voorspellen is een kunst die een mix van professioneel oordeel en objectieve, statistische analyse vereist.
Het is vaak effectief om te beginnen met een objectieve statistische voorspelling die automatisch rekening houdt met trends, seizoensinvloeden en andere patronen. Pas vervolgens aanpassingen of prognoseoverschrijvingen toe op basis van uw zakelijke oordeel. Smart Demand Planner maakt het eenvoudig om grafische en tabelvormige aanpassingen aan statistische prognoses uit te voeren.
Het prognoseproces is doorgaans iteratief.
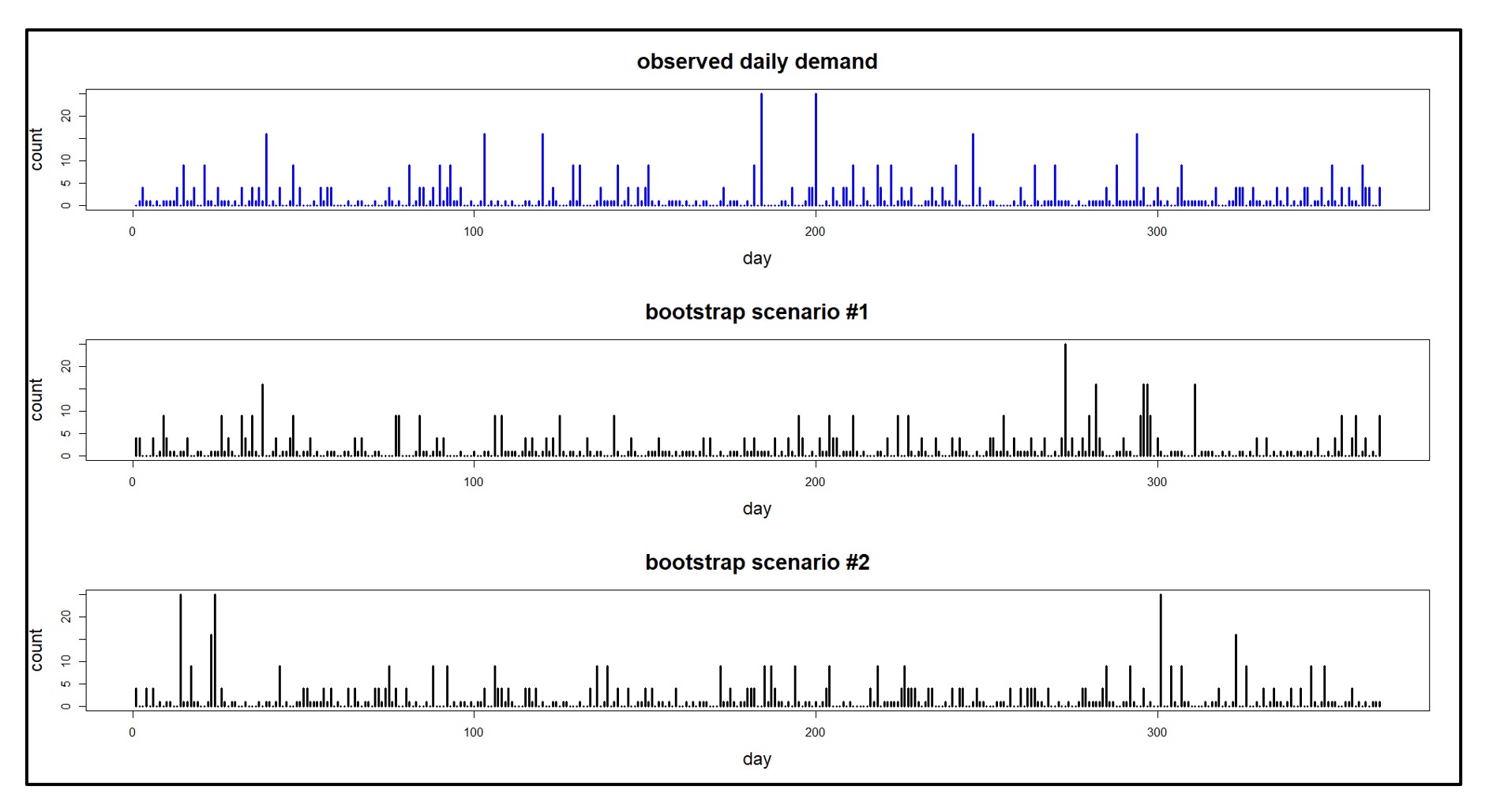
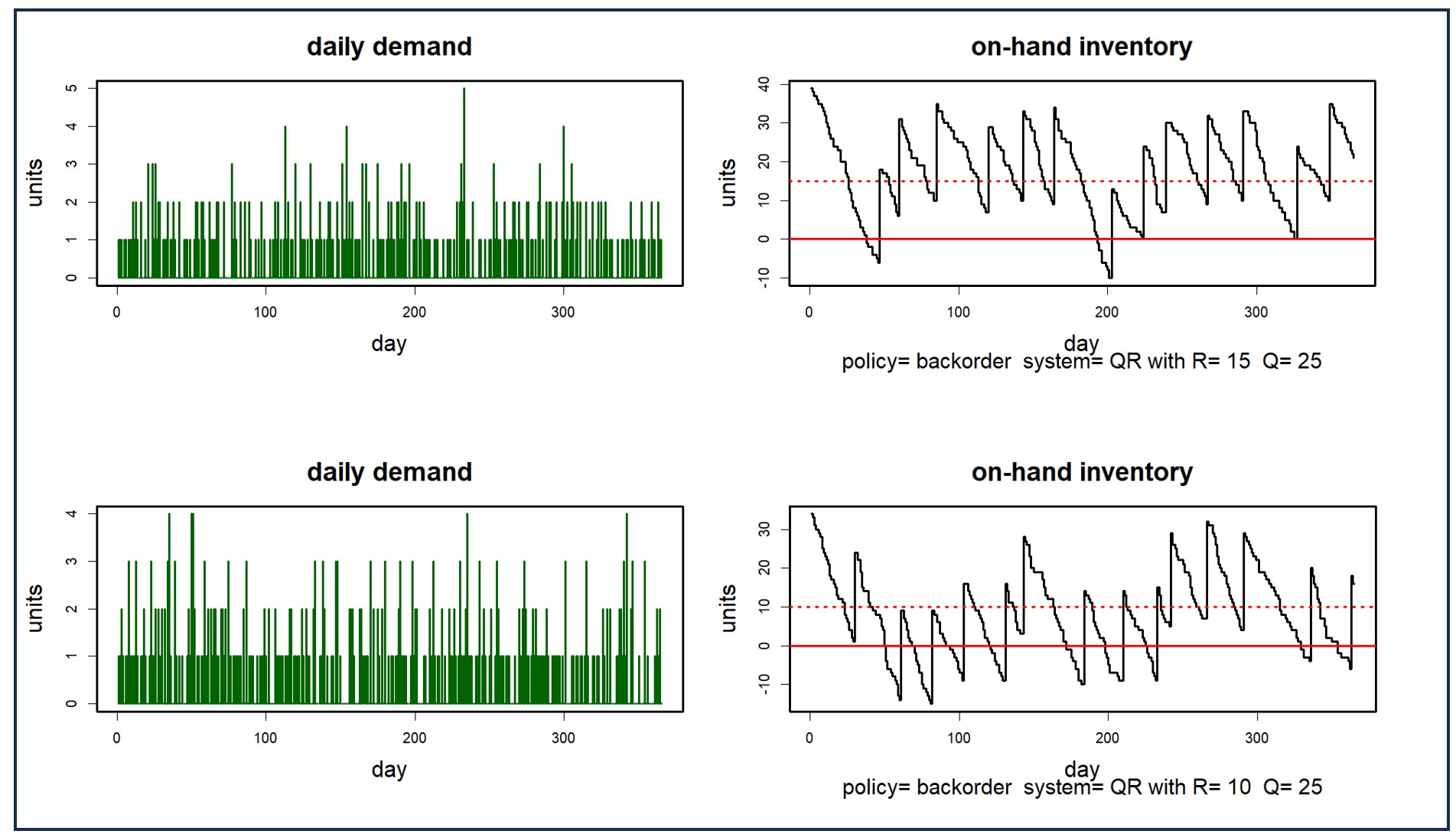
U zult waarschijnlijk besluiten uw oorspronkelijke prognose een aantal malen te verfijnen voordat u tevreden bent. Mogelijk wilt u oudere historische gegevens uitsluiten die u niet langer relevant vindt. U kunt verschillende gewichten op het voorspellingsmodel toepassen, waarbij verschillende accenten op de meest recente gegevens worden gelegd. U kunt trenddemping toepassen om agressief trendmatige statistische voorspellingen te verhogen of te verlagen. U kunt de Machine Learning-modellen de prognoseselectie voor u laten verfijnen en automatisch het winnende model selecteren. De verwerkingssnelheid van Smart Demand Planner geeft u voldoende tijd om meerdere keren te passen en slaat meerdere versies van de prognoses op als 'momentopnamen', zodat u de nauwkeurigheid van de prognoses later kunt vergelijken.
Voorspellen vereist grafische ondersteuning.
De patronen die in de gegevens zichtbaar zijn, kunnen door een scherp oog worden gezien. De geloofwaardigheid van uw prognoses zal vaak sterk afhangen van grafische vergelijkingen die andere zakelijke belanghebbenden maken wanneer zij de historische gegevens en prognoses beoordelen. Smart Demand Planner biedt grafische weergaven van prognoses, geschiedenis en rapportage van prognoses versus werkelijke cijfers.
Voorspellingen kloppen nooit helemaal.
Omdat zelfs in het beste voorspellingsproces altijd een fout sluipt, is een van de nuttigste aanvullingen op een voorspelling een eerlijke schatting van de foutmarge.
Smart Demand Planner presenteert zowel grafische als tabelvormige samenvattingen van de nauwkeurigheid van de prognoses, gebaseerd op de zuurtest van het voorspellen van gegevens die zijn achtergehouden bij de ontwikkeling van het voorspellingsmodel.
Prognose-intervallen of betrouwbaarheidsintervallen zijn ook erg handig. Ze beschrijven het waarschijnlijke bereik van de mogelijke vraag die naar verwachting zal optreden. Als de werkelijke vraag bijvoorbeeld meer dan 10% van de tijd buiten het 90%-betrouwbaarheidsinterval valt, is er reden om verder onderzoek te doen.
Voorspellen vereist een match tussen methode en gegevens.
Een van de belangrijkste technische taken bij het voorspellen is het afstemmen van de keuze van de voorspellingstechniek op de aard van de gegevens. Kenmerken van een datareeks zoals trend, seizoensinvloeden of abrupte niveauverschuivingen suggereren bepaalde technieken in plaats van andere.
De automatische prognosefunctie van Smart Demand Planner maakt deze match snel, nauwkeurig en automatisch.
Prognoses maken vaak deel uit van een groter plannings- of controleproces.
Prognoses kunnen bijvoorbeeld een krachtige aanvulling zijn op op spreadsheets gebaseerde financiële analyses, waardoor rijen met cijfers naar de toekomst kunnen worden uitgebreid. Bovendien zijn nauwkeurige prognoses van de verkoop en de vraag naar producten fundamentele input voor de productieplanning en voorraadcontroleprocessen van een fabrikant. Een objectieve statistische voorspelling van toekomstige verkopen helpt altijd bij het identificeren wanneer het budget (of het verkoopplan) te onrealistisch is. Gap-analyse stelt het bedrijf in staat corrigerende maatregelen te nemen voor hun vraag- en marketingplannen om ervoor te zorgen dat ze het gebudgetteerde plan niet missen.
Prognoses moeten worden geïntegreerd in ERP-systemen
Smart Demand Planner kan zijn resultaten snel en eenvoudig overbrengen naar andere applicaties, zoals spreadsheets, databases en planningssystemen inclusief ERP-applicaties. Gebruikers kunnen voorspellingen in verschillende bestandsformaten exporteren, hetzij via download, hetzij via beveiligde FTP-bestandslocaties. Smart Demand Planner omvat API-gebaseerde integraties met een verscheidenheid aan ERP- en EAM-systemen, waaronder Epicor Kinetic en Epicor Prophet 21, Sage X3 en Sage 300, Oracle NetSuite en elk van de Dynamics 365 ERP-systemen van Microsoft. Dankzij API-gebaseerde integraties kunnen klanten prognoseresultaten op verzoek rechtstreeks terugsturen naar het ERP-systeem.
Het resultaat is een efficiëntere verkoopplanning, budgettering, productieplanning, bestellingen en voorraadplanning.