Evenwichtsoefening
Bij voorraadbeheer gaat het, net als bij alles, om het balanceren van concurrerende prioriteiten. Wilt u een lean inventaris? Ja! Wil jij kunnen zeggen “Het is op voorraad” als een klant iets wil kopen? Ja!
Maar kun je het op beide manieren hebben? Slechts tot op zekere hoogte. Als u uw voorraad te agressief aanpast, riskeert u voorraadtekorten. Als je voorraadtekorten uitroeit, creëer je een opgeblazen voorraad. U wordt gedwongen een bevredigend evenwicht te vinden tussen de twee concurrerende doelen: een beperkte voorraad en een hoge beschikbaarheid van artikelen.
Een balans bereiken
Hoe breng je dat evenwicht tot stand? Te veel voorraadplanners 'schatten' hun weg naar een of ander antwoord. Of ze bedenken een keer een slim antwoord en hopen dat het een verre houdbaarheidsdatum heeft en blijven het gebruiken terwijl ze zich op andere problemen concentreren. Helaas zullen verschuivingen in de vraag en/of veranderingen in de prestaties van leveranciers en/of verschuivingen in de prioriteiten van uw eigen bedrijf oude voorraadplannen overbodig maken en u weer terugbrengen waar u begon.
Het is onvermijdelijk dat elk plan een houdbaarheidsdatum heeft en moet worden bijgewerkt. Het is echter zeker niet de beste praktijk om de ene gok door de andere te vervangen. In plaats daarvan zou elke planningscyclus gebruik moeten maken van moderne supply chain-software om giswerk te vervangen door op feiten gebaseerde analyses met behulp van waarschijnlijkheidsberekeningen.
Ken jezelf
Het enige dat software niet kan, is een beste antwoord berekenen zonder uw prioriteiten te kennen. Hoeveel prioriteit geeft u aan lean inventory boven artikelbeschikbaarheid? Software voorspelt de voorraad- en beschikbaarheidsniveaus die worden veroorzaakt door de beslissingen die u neemt over het beheer van elk item in uw inventaris, maar alleen u kunt beslissen of een bepaalde reeks belangrijke prestatie-indicatoren consistent is met wat u wilt.
Weten wat je wilt in algemene zin is gemakkelijk: je wilt alles. Maar weten wat je voorkeur heeft bij het vergelijken van specifieke scenario's is moeilijker. Het helpt om een scala aan realiseerbare mogelijkheden te kunnen zien en na te denken over wat het beste lijkt als ze naast elkaar worden gelegd.
Zie wat het volgende is
Supply chain-software kan u inzicht geven in de afwegingscurve. Over het algemeen weet u dat een beperkte voorraad en een hoge beschikbaarheid van artikelen elkaar tegenwerken, maar het zien van artikelspecifieke afwegingscurven verscherpt uw focus.
Waarom is er een bocht? Omdat u keuzes heeft over hoe u elk item beheert. Als u bijvoorbeeld voortdurend de voorraadstatus controleert, welke waarden wijst u dan toe aan de Min en Max waarden die bepalen wanneer aanvullingen moeten worden besteld en hoeveel er moet worden besteld. De afwegingscurve ontstaat omdat het kiezen van verschillende Min- en Max-waarden leidt tot verschillende niveaus van bij de hand inventaris en verschillende niveaus van artikelbeschikbaarheid, bijvoorbeeld zoals gemeten door vulpercentage.
Een scenario voor analyse
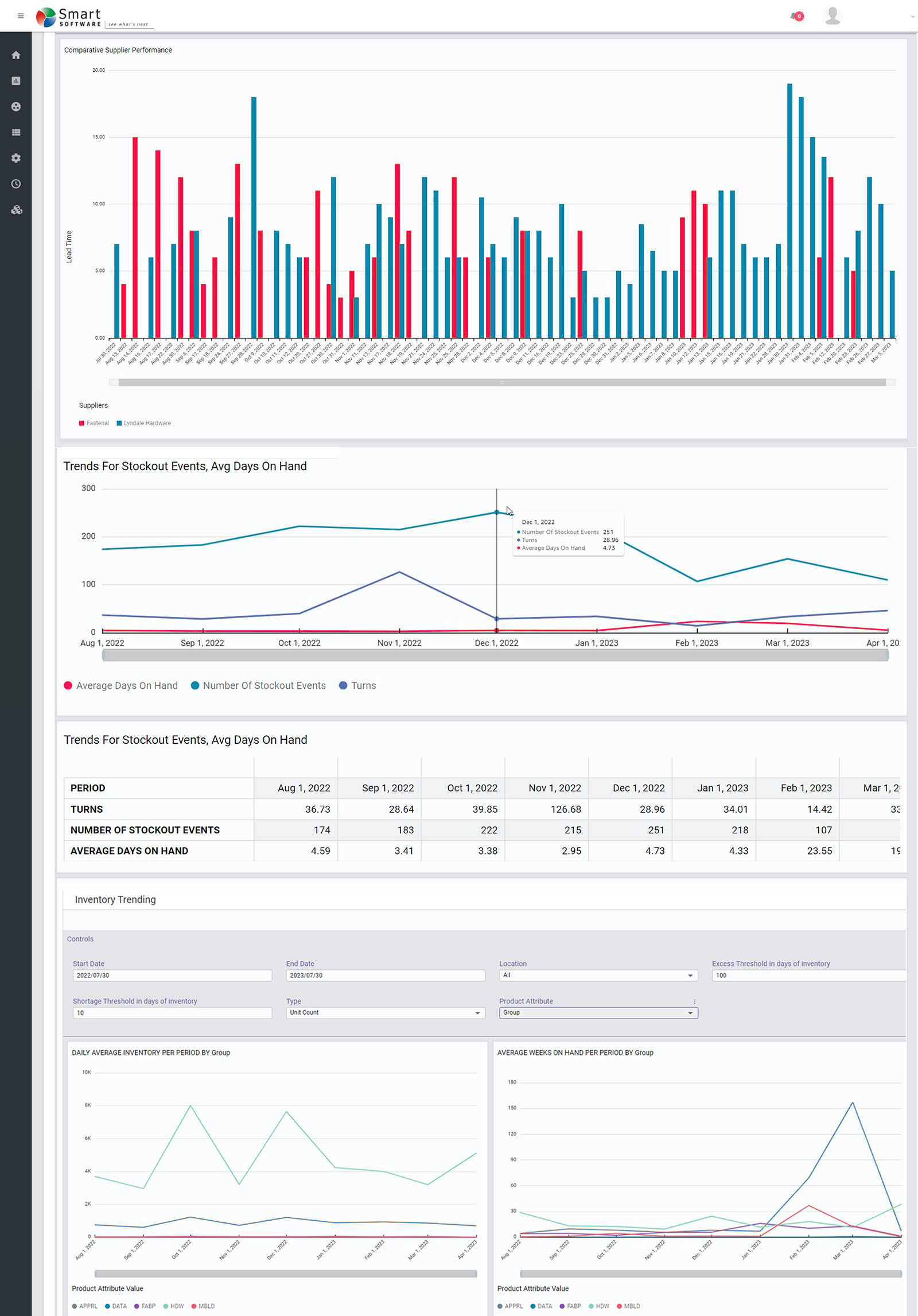
Om deze ideeën te illustreren, gebruikte ik a digitale tweeling om in te schatten hoe verschillende waarden van Min en Max in een bepaald scenario zouden presteren. Het scenario concentreerde zich op een fictief reserveonderdeel met een puur willekeurige vraag met een redelijk hoog niveau onderbreking (37% aan dagen zonder vraag). De doorlooptijden voor het aanvullen waren een fluitje van een cent tussen 7 en 14 dagen. De Min- en Max-waarden werden systematisch gevarieerd: Min van 20 tot 40 eenheden, Max van Min+1 eenheden tot 2xMin eenheden. Elk (Min,Max) paar werd in totaal 1000 keer gesimuleerd gedurende 365 dagen gebruik. Vervolgens werden de resultaten gemiddeld om zowel het gemiddelde aantal beschikbare eenheden als het vulpercentage te schatten, dat wil zeggen het percentage van de dagelijkse behoeften waaraan onmiddellijk werd voldaan vanaf voorraad. Als de voorraad niet beschikbaar was, werd deze nabesteld.
Resultaten
Het experiment leverde twee soorten resultaten op:
- Grafieken die de relatie tonen tussen de min- en max-waarden en twee belangrijke prestatie-indicatoren: opvullingspercentage en gemiddelde beschikbare eenheden.
- Een afwegingscurve die laat zien hoe het opvullingspercentage en de beschikbare eenheden met elkaar in evenwicht zijn.
Figuur 1 toont de beschikbare inventaris als functie van de waarden van Min en Max. Het experiment leverde handniveaus op variërend van bijna 0 tot ongeveer 40 eenheden. Over het algemeen resulteert het constant houden van Min en het verhogen van Max in meer beschikbare eenheden. De relatie met Min is complexer: Max constant houden, Min verhogen voegt eerst de voorraad toe, maar vermindert deze op een gegeven moment.
Figuur 2 toont het vulpercentage als functie van de waarden Min en Max. Het experiment leverde opvullingspercentages op variërend van bijna 0% tot 100%. Over het algemeen weerspiegelden de functionele relaties tussen het opvullingspercentage en de waarden van Min en Max die in Figuur 1.
Figuur 3 maakt het belangrijkste punt duidelijk en laat zien hoe het variëren van Min en Max tot een perverse combinatie van de belangrijkste prestatie-indicatoren leidt. Over het algemeen zijn de waarden Min en Max die de beschikbaarheid van artikelen maximaliseren (opvullingspercentage) dezelfde waarden die de voorraadkosten maximaliseren (gemiddelde beschikbare eenheden). Dit algemene patroon wordt weergegeven door de blauwe curve. De experimenten leverden ook enkele uitlopers van de blauwe curve op die verband houden met slechte keuzes voor Min en Max, in de zin dat andere keuzes deze domineren door hetzelfde opvullingspercentage te produceren met een lagere voorraad.
Conclusies
Figuur 3 maakt duidelijk dat uw keuze voor het beheer van een voorraadartikel u dwingt om voorraadkosten af te wegen tegen de beschikbaarheid van artikelen. Je kunt enkele inefficiënte combinaties van Min- en Max-waarden vermijden, maar je kunt niet aan de afweging ontsnappen.
De goede kant van deze realiteit is dat je niet hoeft te raden wat er zal gebeuren als je je huidige waarden van Min en Max naar iets anders verandert. De software vertelt u wat de verhuizing u oplevert en wat het u gaat kosten. U kunt uw Guestimator-hoed afzetten en met vertrouwen uw ding doen.
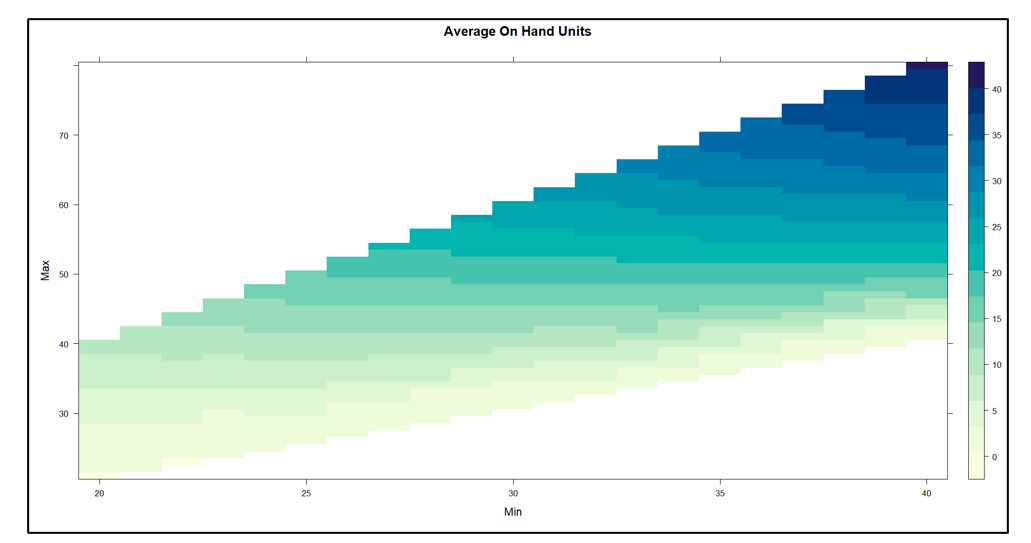
Figuur 1 Voorhanden inventaris als functie van de min- en max-waarden
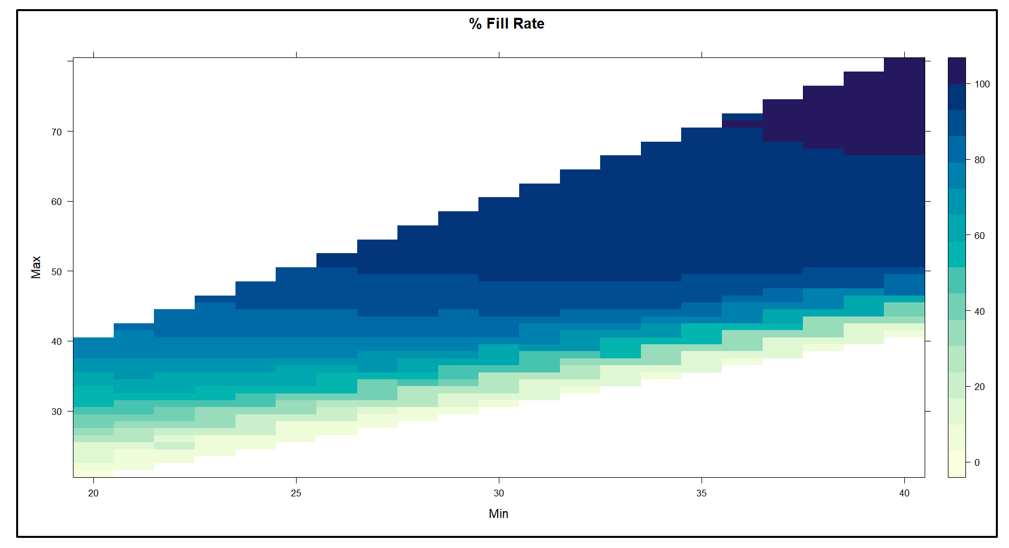
Figuur 2 Vulsnelheid als functie van Min- en Max-waarden

Figuur 3 Afwegingscurve tussen opvullingspercentage en voorhanden voorraad