Als je de laatste tijd je hoofd omhoog hebt gehouden, heb je misschien wat extra waanzin opgemerkt op het basketbalveld: het falen van Silicon Valley Bank. Degenen onder ons in de supply chain-wereld hebben het bankfalen misschien afgedaan als het probleem van iemand anders, maar die spijtige episode bevat ook een grote les voor ons: het belang van stresstesten die goed worden uitgevoerd.
De Washington Post onlangs verscheen een opiniestuk van Natasha Sarin met de titel “Regulators misten de problemen van Silicon Valley Bank maandenlang. Dit is waarom." Sarin schetste de tekortkomingen in het stresstestregime dat de Federal Reserve aan de bank heeft opgelegd. Een probleem is dat de stresstesten te statisch zijn. De stressfactor van de Fed voor de nominale bbp-groei was één enkel scenario met de veronderstelde waarden voor de komende 13 kwartalen (zie figuur 1). Die 13 driemaandelijkse projecties zijn misschien iemands consensus over hoe een bad hair day eruit zou zien, maar dat is niet de enige manier waarop dingen zouden kunnen verlopen. Als samenleving wordt ons geleerd een betere manier te waarderen om onvoorziene omstandigheden weer te geven telkens wanneer de National Weather Service ons geprojecteerde orkaansporen laat zien (zie figuur 2). Elk scenario, weergegeven door een lijn met een andere kleur, toont een mogelijk stormpad, waarbij de geconcentreerde lijnen het meest waarschijnlijke pad vertegenwoordigen. Door de lagere waarschijnlijkheidspaden bloot te leggen, wordt de risicoplanning verbeterd.
Bij het stresstesten van de toeleveringsketen hebben we realistische scenario's nodig van mogelijke toekomstige eisen die zich kunnen voordoen, zelfs extreme eisen. Smart voorziet hierin in onze software (met aanzienlijke verbeteringen in onze Gen2 methodes). De software genereert een groot aantal geloofwaardige vraagscenario's, genoeg om de volledige omvang van de risico's bloot te leggen (zie figuur 3). Stresstesten hebben alles te maken met het genereren van enorme aantallen planningsscenario's, en de probabilistische methoden van Smart wijken radicaal af van eerdere deterministische S&OP-toepassingen, omdat ze volledig op scenario's zijn gebaseerd.
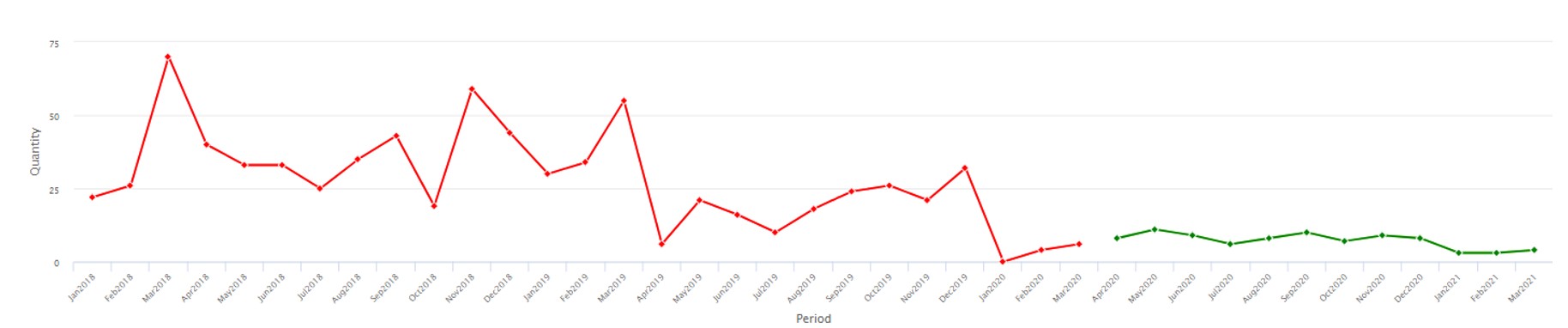
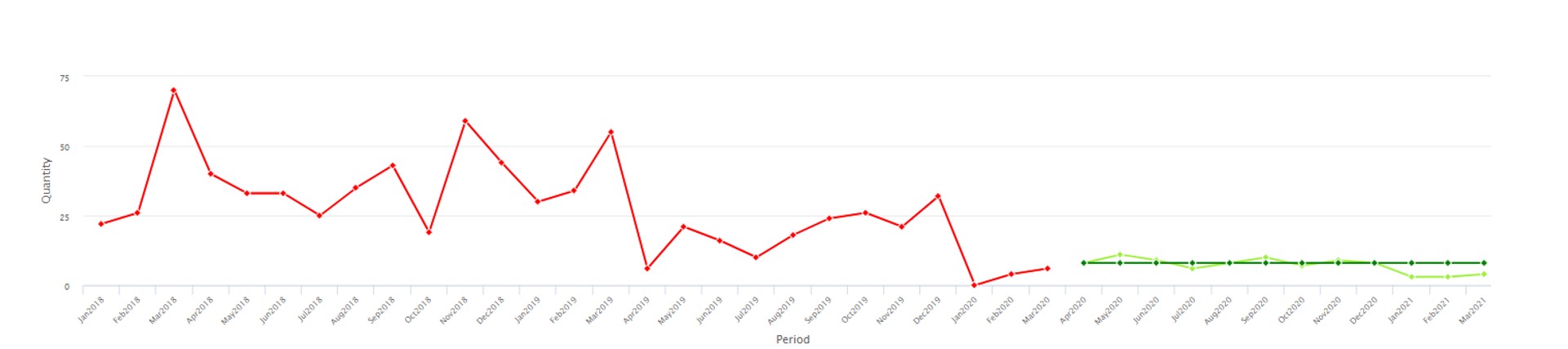
De andere fout in de stresstests van de Fed was dat ze maanden van tevoren waren ontworpen, maar nooit werden bijgewerkt voor veranderende omstandigheden. Vraagplanners en voorraadbeheerders begrijpen intuïtief dat sleutelvariabelen zoals de vraag naar artikelen en de doorlooptijd van leveranciers niet alleen zeer willekeurig zijn, zelfs wanneer de zaken stabiel zijn, maar ook onderhevig zijn aan abrupte verschuivingen die een snelle herschrijving van planningsscenario's vereisen (zie afbeelding 4, waar de gemiddelde vraag springt dramatisch omhoog tussen waarnemingen 19 en 20). Smart's Gen2-producten bevatten nieuwe technologie voor het detecteren van dergelijke "regime verandert' en dienovereenkomstig automatisch veranderende scenario's.
Banken worden gedwongen om stresstests te ondergaan, hoe gebrekkig ze ook mogen zijn, om hun spaarders te beschermen. Supply chain-professionals hebben nu een manier om hun supply chains te beschermen door moderne software te gebruiken om hun vraagplannen en voorraadbeheerbeslissingen aan een stresstest te onderwerpen.
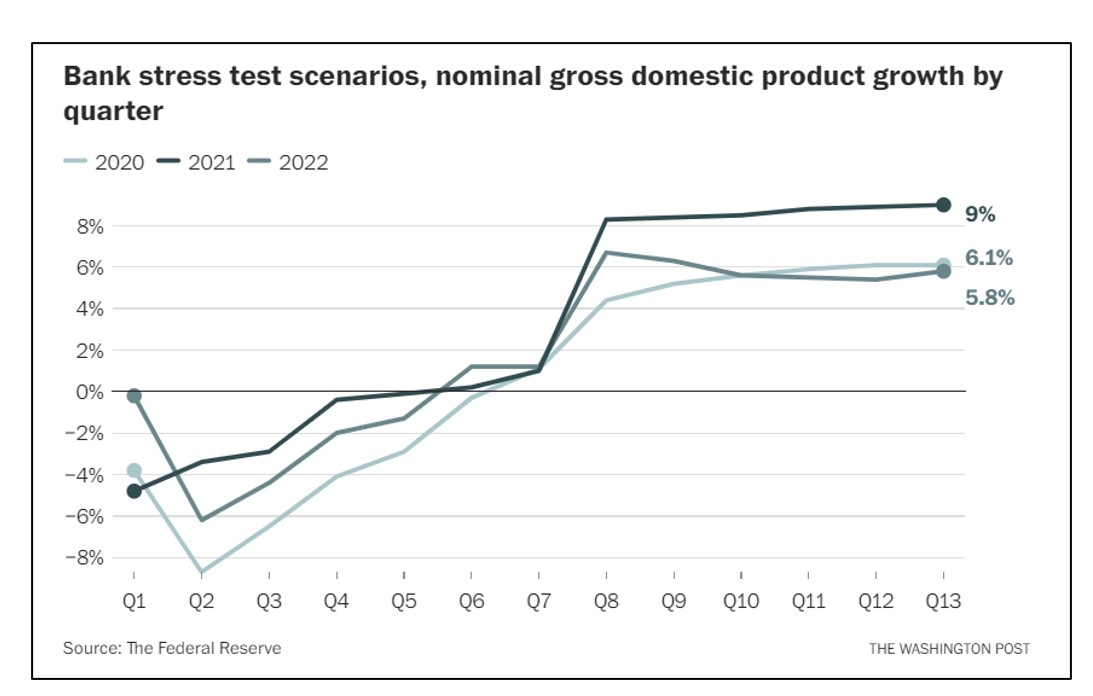
Figuur 1: Scenario's die de Fed gebruikte om banken te stresstesten.

Figuur 2: Scenario's die door de National Weather Service worden gebruikt om orkaansporen te voorspellen
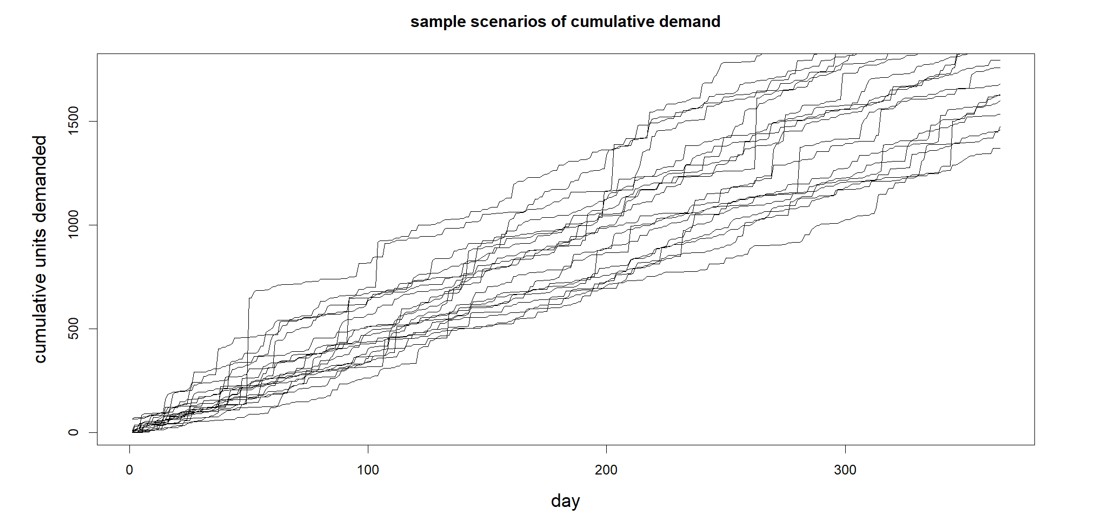
Afbeelding 3: Vraagscenario's van het type gegenereerd door Smart Demand Planner
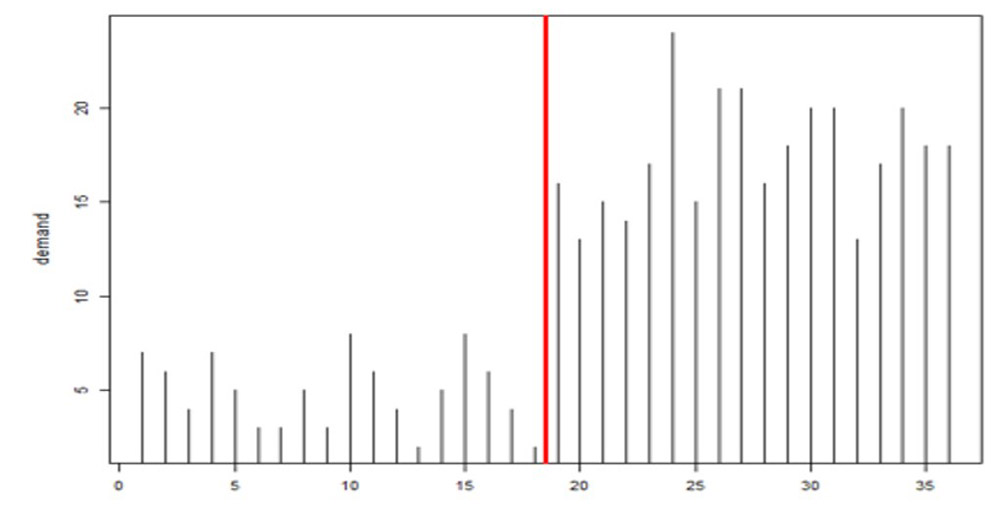
Figuur 4: Voorbeeld van regimeverandering in productvraag na observatie #19