Overzicht
De geavanceerde supply chain-analyse van Smart Software maakt gebruik van meerdere geavanceerde methoden. Twee van de belangrijkste zijn "statistische bootstrapping" en "Monte Carlo-simulatie". Omdat er bij beide veel willekeurige getallen rondvliegen, raken mensen soms in de war over wat wat is en waar ze goed voor zijn. Vandaar deze notitie. Waar het op neerkomt: statistische bootstrapping genereert vraagscenario's voor prognoses. Monte Carlo-simulatie gebruikt de scenario's voor voorraadoptimalisatie.
Opstarten
Bootstrapping, ook wel "resampling" genoemd, is een methode van computationele statistieken die we gebruiken om vraagscenario's voor prognoses te creëren. De essentie van het prognoseprobleem is het blootleggen van mogelijke toekomsten waarmee uw bedrijf te maken kan krijgen, zodat u kunt uitzoeken hoe u bedrijfsrisico's kunt beheersen. Traditionele prognosemethoden richten zich op het berekenen van de "meest waarschijnlijke" toekomst, maar ze geven niet het volledige risicobeeld weer. Bootstrapping biedt een onbeperkt aantal realistische wat-als-scenario's.
Bootstrapping doet dit zonder onrealistische aannames te doen over de vraag, dwz dat deze niet intermitterend is, of dat deze een klokvormige verdeling van groottes heeft. Die aannames zijn krukken om de wiskunde eenvoudiger te maken, maar de bootstrap is een procedure, geen vergelijking, dus dergelijke vereenvoudigingen zijn niet nodig.
Voor het eenvoudigste vraagtype, dat een stabiele willekeur is zonder seizoensgebondenheid of trend, is bootstrapping doodeenvoudig. Om een redelijk idee te krijgen van wat een enkele toekomstige vraagwaarde zou kunnen zijn, kiest u willekeurig een van de historische eisen. Om een vraagscenario te creëren, maakt u meerdere willekeurige selecties uit het verleden en rijgt u ze aan elkaar. Klaar. Het is mogelijk om wat meer realisme toe te voegen door de gevraagde waarden te "jitteren", dwz een beetje extra willekeur aan elke waarde toe te voegen of af te trekken, maar zelfs dat is eenvoudig.
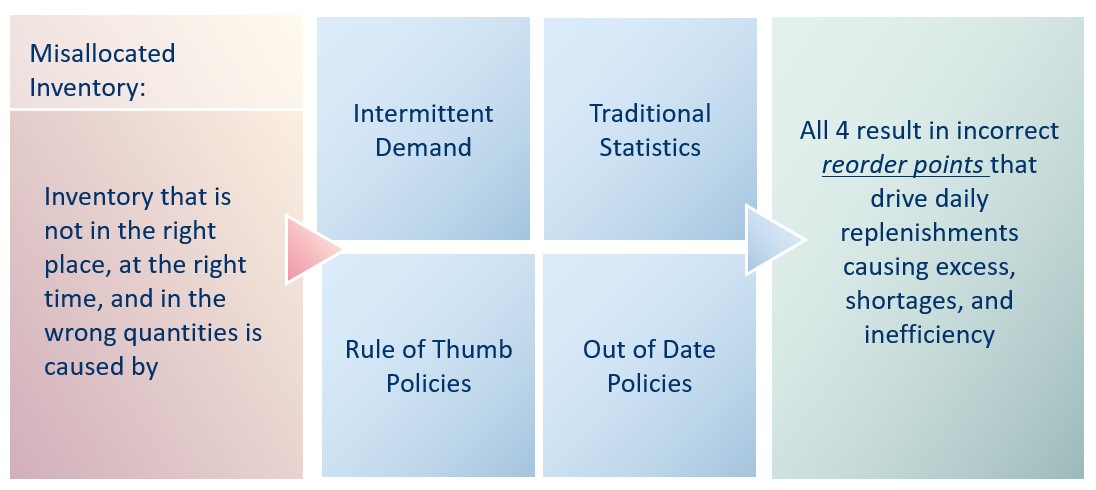
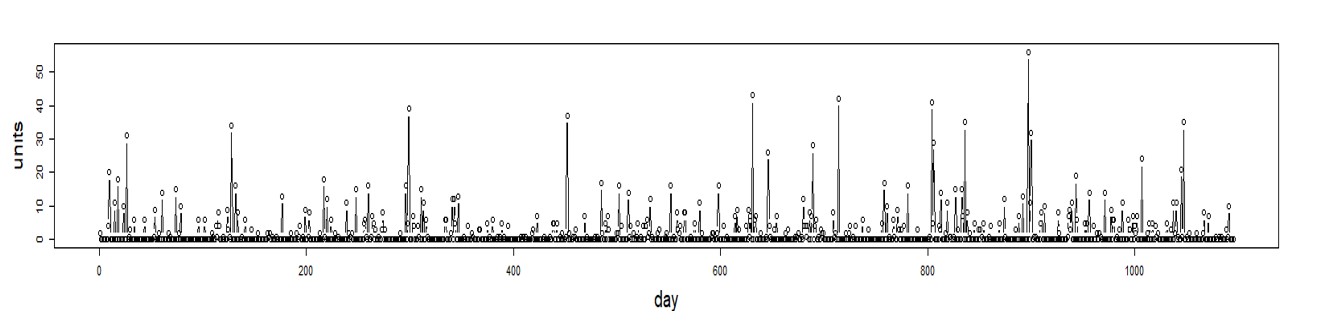
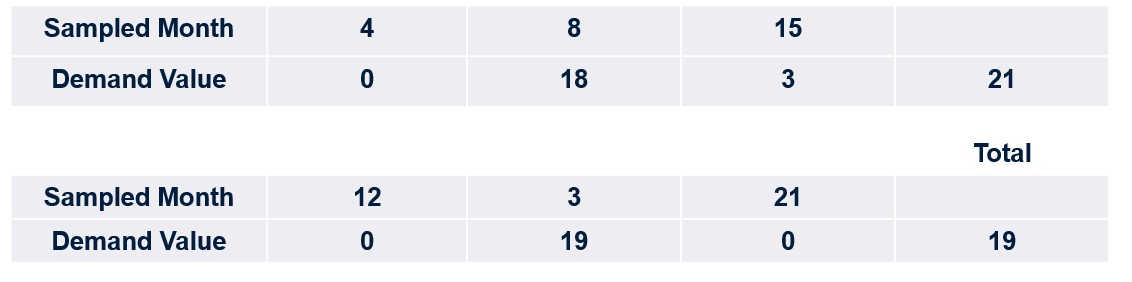
Figuur 1 toont een eenvoudige bootstrap. De eerste regel is een korte reeks historische vraag naar een SKU. De volgende regels tonen scenario's van toekomstige vraag die zijn gemaakt door willekeurig waarden uit de vraaggeschiedenis te selecteren. De volgende drie eisen kunnen bijvoorbeeld zijn (0, 14, 6), of (2, 3, 5), enz.

Afbeelding 1: voorbeeld van vraagscenario's gegenereerd door een eenvoudige bootstrap
Bewerkingen met een hogere frequentie, zoals dagelijkse prognoses, brengen complexere vraagpatronen met zich mee, zoals dubbele seizoensgebondenheid (bijv. dag van de week en maand van het jaar) en/of trend. Dit daagde ons uit om een nieuwe generatie bootstrapping-algoritmen uit te vinden. We hebben onlangs een Amerikaans patent gewonnen voor deze doorbraak, maar de essentie is zoals hierboven beschreven.
Monte Carlo simulatie
Monte Carlo staat bekend om zijn casino's, die net als bootstrapping het idee van willekeur oproepen. Monte Carlo-methoden gaan ver terug, maar de moderne impuls kwam met de noodzaak om wat harige berekeningen te maken over waar neutronen zouden vliegen als een A-bom ontploft.
De essentie van Monte Carlo-analyse is deze: “Ons probleem is te ingewikkeld om te analyseren met vergelijkingen van papier en potlood. Dus, laten we een computerprogramma schrijven dat de individuele stappen van het proces codeert, de willekeurige elementen erin stoppen (bijvoorbeeld welke kant een neutron op schiet), het opwinden en kijken hoe het gaat. Aangezien er veel willekeur is, laten we het programma een ontelbaar aantal keren uitvoeren en het gemiddelde van de resultaten nemen.”
Als we deze benadering toepassen op voorraadbeheer, hebben we een andere reeks willekeurig voorkomende gebeurtenissen: een vraag van een bepaalde omvang komt bijvoorbeeld op een willekeurige dag binnen, een aanvulling van een bepaalde omvang arriveert na een willekeurige doorlooptijd, we snijden een aanvullings-PO van een bepaalde maat wanneer de voorraad daalt tot of onder een bepaald bestelpunt. We coderen de logica die deze gebeurtenissen met elkaar in verband brengt in een programma. We voeden het met een willekeurige vraagvolgorde (zie bootstrapping hierboven), voeren het programma een tijdje uit, laten we zeggen een jaar dagelijkse bewerkingen, berekenen prestatiestatistieken zoals Fill Rate en Average On Hand-inventaris, en "gooi de dobbelstenen" door het opnieuw uit te voeren het programma vele malen en het gemiddelde van de resultaten van vele gesimuleerde jaren. Het resultaat is een goede inschatting van wat er gebeurt als we belangrijke managementbeslissingen nemen: “Als we het bestelpunt op 10 eenheden zetten en de bestelhoeveelheid op 15 eenheden, kunnen we een serviceniveau verwachten van 89% en een gemiddelde beschikbaarheid van 21 eenheden.” Wat de simulatie voor ons doet, is het blootleggen van de gevolgen van managementbeslissingen op basis van realistische vraagscenario's en solide wiskunde. Het giswerk is weg.
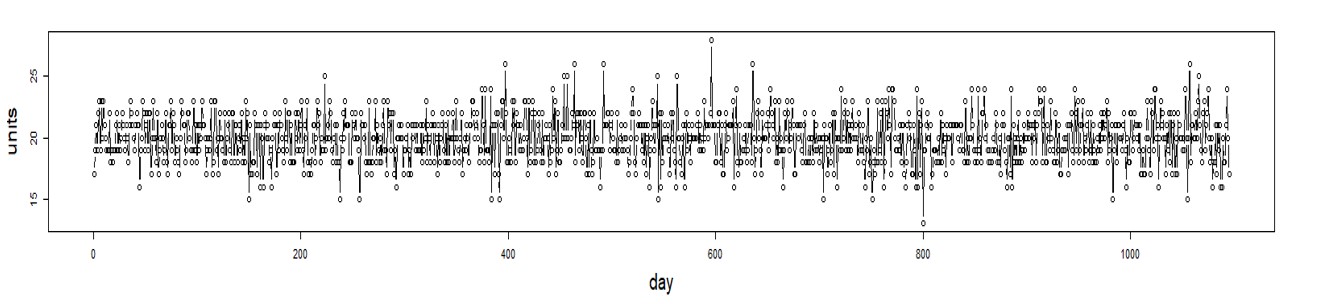
Figuur 2 toont enkele van de innerlijke werkingen van een Monte Carlo-simulatie van een voorraadsysteem in vier panelen. Het systeem gebruikt een Min/Max voorraadbeheerbeleid met Min=10 en Max=25. Nabestellingen zijn niet toegestaan: u heeft het goed of u verliest het bedrijf. Doorlooptijden voor aanvulling zijn meestal 7 dagen, maar soms ook 14. Deze simulatie duurde een jaar.
Het eerste paneel toont een complex willekeurig vraagscenario waarin er geen vraag is in het weekend, maar de vraag over het algemeen elke dag toeneemt van maandag tot en met vrijdag. Het tweede paneel toont het willekeurige aantal beschikbare eenheden, dat ebt en vloeit met elke aanvullingscyclus. Het derde paneel toont de willekeurige groottes en tijdstippen van aanvullingsorders die binnenkomen van de leverancier. Het laatste paneel toont de onbevredigde vraag die de klantrelaties in gevaar brengt. Dit soort detail kan erg handig zijn om inzicht te krijgen in de dynamiek van een voorraadsysteem.
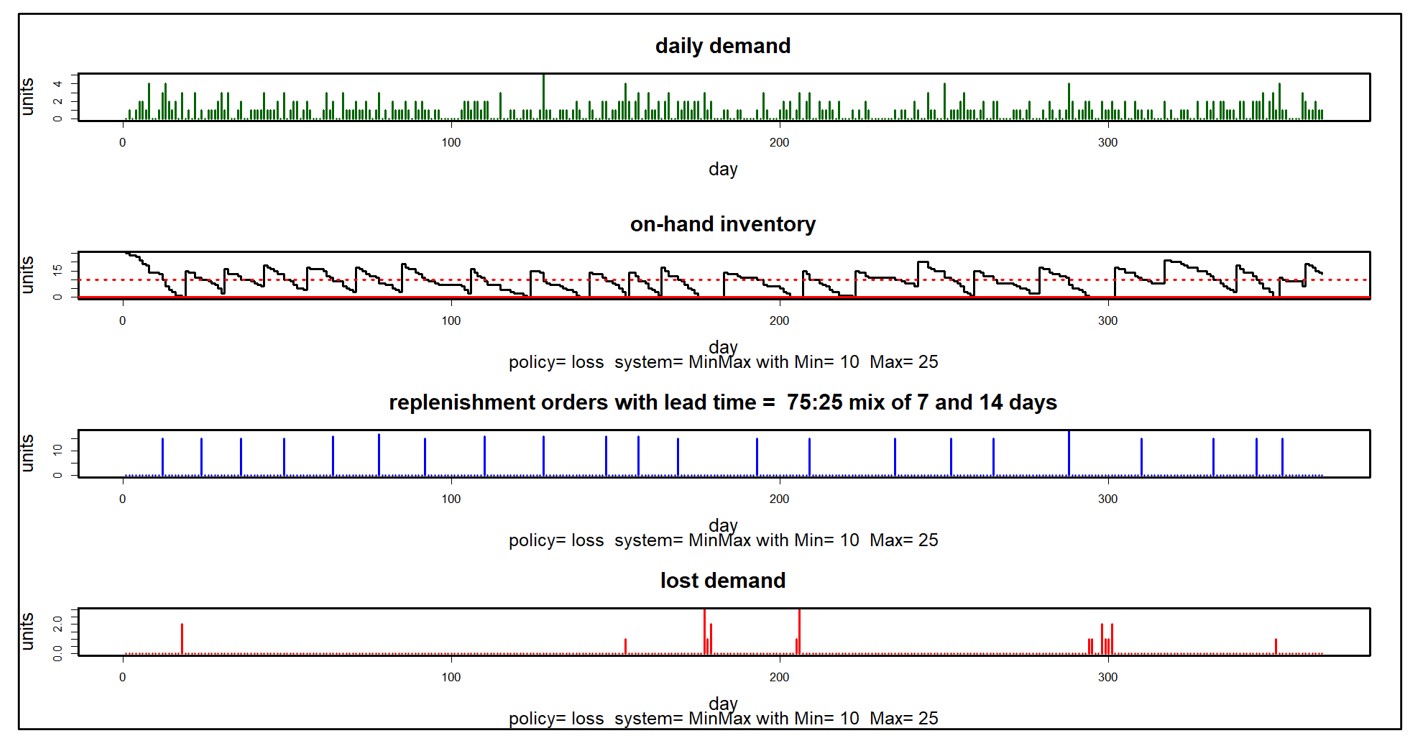
Figuur 2: Details van een Monte Carlo-simulatie
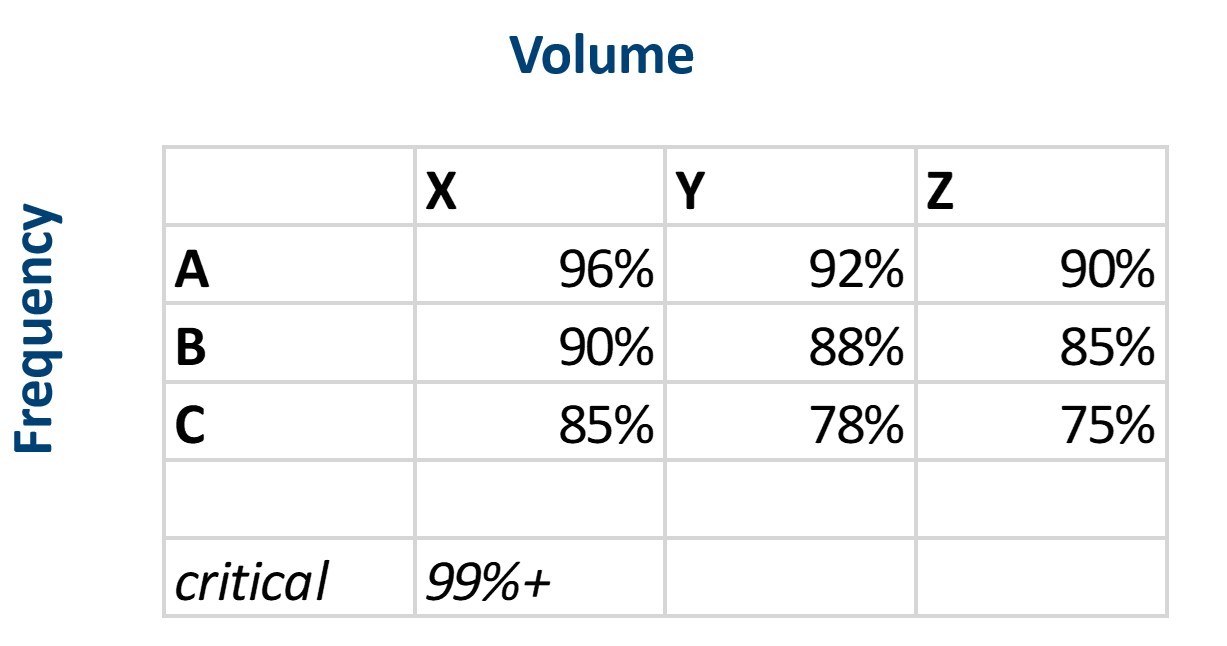
Figuur 2 toont slechts een van de talloze manieren waarop het jaar zou kunnen verlopen. Over het algemeen willen we de resultaten van vele gesimuleerde jaren middelen. Niemand zou tenslotte een munt opgooien om te beslissen of het een eerlijke munt was. Figuur 3 laat zien hoe vier key performance metrics (KPI's) van jaar tot jaar variëren voor dit systeem. Sommige statistieken zijn relatief stabiel in simulaties (Fill Rate), maar andere laten meer relatieve variabiliteit zien (Operating Cost = Holding Cost + Ordering Cost + Shortage Cost). Als we de grafieken bekijken, kunnen we schatten dat de keuzes van Min=10, Max=25 leiden tot gemiddelde bedrijfskosten van ongeveer $3.000 per jaar, een opvullingspercentage van ongeveer 90%, een serviceniveau van ongeveer 75% en een gemiddelde aan Hand van ongeveer 10
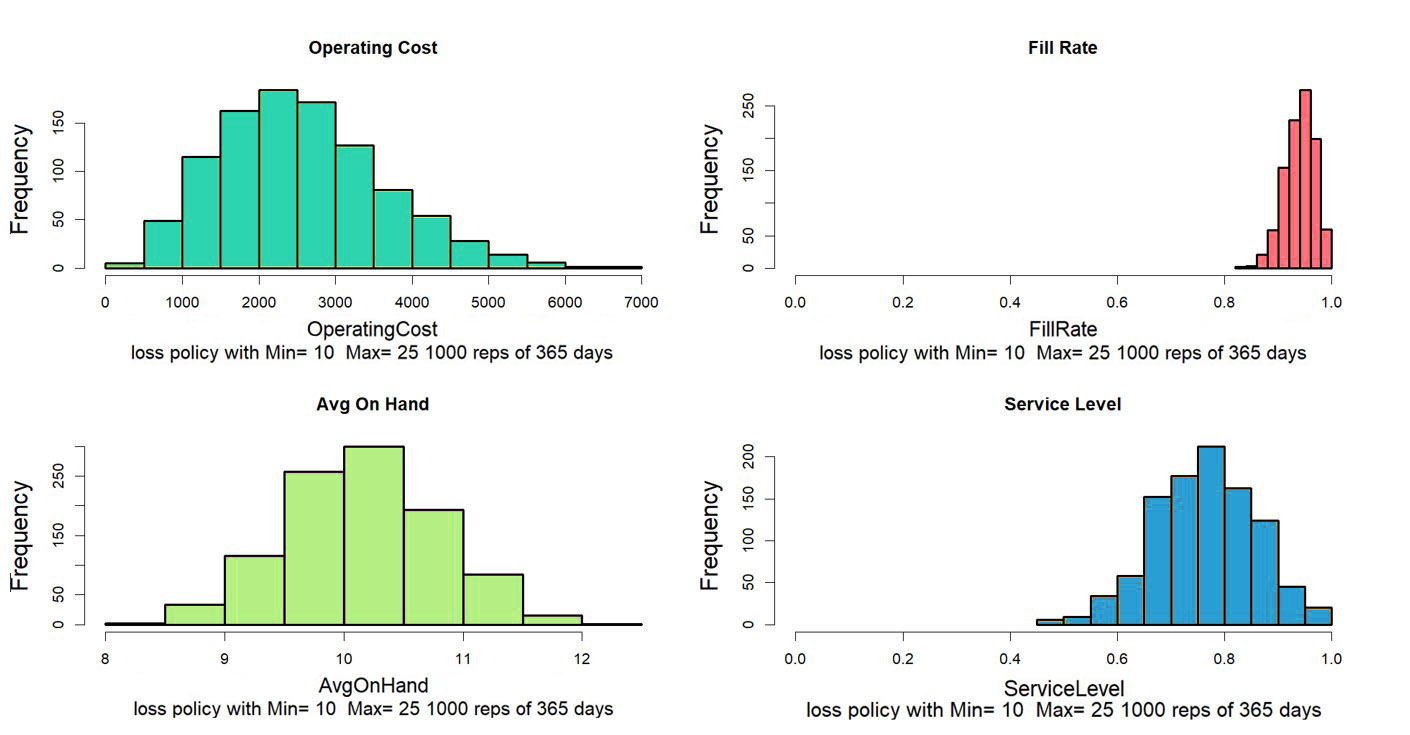
Figuur 3: Variatie in KPI's berekend over 1000 gesimuleerde jaren
Het is nu zelfs mogelijk om een managementvraag van een hoger niveau te beantwoorden. We kunnen verder gaan dan "Wat gebeurt er als ik zus-en-zo doe?" naar “Wat is de best wat ik kan doen om een opvullingspercentage van ten minste 90% voor dit item te bereiken tegen de laagst mogelijke kosten?” De wiskundige achter deze sprong zit nog een andere sleuteltechnologie genaamd "stochastische optimalisatie", maar we stoppen hier voor nu. Het volstaat te zeggen dat de SIO&P-software van Smart de "ontwerpruimte" van min- en max-waarden kan doorzoeken om automatisch de beste keuze te vinden.