Natuurkundigen zoals mijn mede-oprichter van Smart Software, Dr. Nelson Hartunian, vertellen ons burgers dat alles anders is als we doordringen tot op het kleinste niveau van de wereld. Fysica op kwantumniveau is nogal raar - helemaal niet zoals wat we ervaren in ons gebruikelijke macroscopische leven. Tot de eigenaardigheden behoren "superpositie", "verstrengeling" en "kwantumschuim". Hoe vreemd deze verschijnselen ook zijn, ik kan het niet laten om analogen te zien in de zogenaamd andere wereld van supply chain management.
Overweeg kwantumsuperpositie. In het kort betekent superpositie dat elke kwantumentiteit in twee toestanden tegelijk kan zijn. De kat van Schrödinger is de beroemdste illustratie van dit idee. Maar hoeveel van jullie lezers bevinden zich ook in een staat van superpositie? Ben je niet een manager van een team maar een lid van het team van je supervisor, een probleemoplosser maar ook een prognose-expert of een voorraadoptimizer en...? En geeft dit alles je niet soms het gevoel, net als die kat, dat je tegelijkertijd dood en levend bent? Moderne software kan een deel van deze last verlichten door de taken van vraagplanning en voorraadoptimalisatie te automatiseren. De rest is aan jou.
Een tweede kwantumanaloog is verstrengeling. Kort gezegd is verstrengeling de koppeling tussen twee elementen van een systeem. Ze kunnen lichtjaren van elkaar verwijderd zijn, maar het veranderen van een deel van een verstrengeld systeem zal onmiddellijk het andere deel veranderen. Dit irriteerde Albert Einstein, die het bespotte als 'spookachtige actie als een afstand'. In onze normale wereld zijn vraagplanning en voorraadoptimalisatie met elkaar verweven, aangezien het proces van voorraadoptimalisatie bovenop het proces van vraagvoorspelling zit. Moderne software koppelt de twee in een efficiënte interface.
Eindelijk het kwantumschuim - een van mijn favoriete ideeën. Zoals ik het begrijp, is kwantumschuim een vervanging voor lege ruimte: er is geen lege ruimte, maar een constant borrelen van "vacuümenergie" vergezeld van een stroom van "virtuele deeltjes" die uit het niets worden geboren en vervolgens weer in het niets verdwijnen. In de supply chain-wereld zijn de analogen van virtuele deeltjes klantorders. Vaak lijkt het alsof ze zonder waarschuwing uit het niets opduiken, en soms verdwijnen ze door annulering in een al even willekeurig en mysterieus proces. Dit soort vraagfluctuatie is de basis voor alle theorie van voorraadbeheer. Moderne software begint daarom met waarschijnlijkheidsmodellen van de klantvraag. Die modellen hebben vervolgens implicaties voor tastbare grootheden als veiligheidsvoorraden, bestelpunten en bestelhoeveelheden.
Helpt het vraagplanners en voorraadbeheerders echt om na te denken over deze ideeën uit de kwantumfysica? Nou, het is een beetje leuk om de analogieën te zien met onze reguliere wereld van werk. En ze doen ons denken aan meer macroscopische zaken: de basisconcepten van de noodzaak om meer dan één taak tegelijk uit te voeren, de koppeling tussen prognoses en voorraadbeheer, en willekeur als het fundamentele kenmerk van de toeleveringsketen.

gerelateerde berichten

Hoe gaat het met ons? KPI's en KPP's
Het dagelijkse voorraadbeheer kan u bezig houden. Maar je weet dat je af en toe je hoofd omhoog moet brengen om te zien waar je naartoe gaat. Daarvoor moet uw inventarissoftware u statistieken tonen – en niet slechts één, maar een volledige set statistieken of KPI's – Key Performance Indicators.

Wat is voorraadplanning? Een kort woordenboek met voorraadgerelateerde termen
Mensen die betrokken zijn bij de toeleveringsketen hebben waarschijnlijk vragen over de verschillende voorraadtermen en -methoden die in hun werk worden gebruikt. Deze notitie kan helpen door deze termen uit te leggen en te laten zien hoe ze verband houden.

Verward over AI en Machine Learning?
Bent u in de war over wat AI is en wat machine learning is? Weet u niet zeker waarom meer weten u zal helpen bij uw werk in voorraadplanning? Wanhoop niet. Het komt wel goed met je, en we laten je zien hoe iets van wat het ook is, nuttig kan zijn.
recente berichten
 Het beheren van de voorraad reserveonderdelen: beste praktijkenIn this blog, we’ll explore several effective strategies for managing spare parts inventory, emphasizing the importance of optimizing stock levels, maintaining service levels, and using smart tools to aid in decision-making. Managing spare parts inventory is a critical component for businesses that depend on equipment uptime and service reliability. Unlike regular inventory items, spare parts often have unpredictable demand patterns, making them more challenging to manage effectively. An efficient spare parts inventory management system helps prevent stockouts that can lead to operational downtime and costly delays while also avoiding overstocking that unnecessarily ties up capital and increases holding costs. […]
Het beheren van de voorraad reserveonderdelen: beste praktijkenIn this blog, we’ll explore several effective strategies for managing spare parts inventory, emphasizing the importance of optimizing stock levels, maintaining service levels, and using smart tools to aid in decision-making. Managing spare parts inventory is a critical component for businesses that depend on equipment uptime and service reliability. Unlike regular inventory items, spare parts often have unpredictable demand patterns, making them more challenging to manage effectively. An efficient spare parts inventory management system helps prevent stockouts that can lead to operational downtime and costly delays while also avoiding overstocking that unnecessarily ties up capital and increases holding costs. […] 5 manieren om de snelheid van beslissingen in de toeleveringsketen te verbeterenDe belofte van een digitale supply chain heeft de manier waarop bedrijven opereren getransformeerd. In de kern kan het snelle, datagestuurde beslissingen nemen en tegelijkertijd kwaliteit en efficiëntie in de hele bedrijfsvoering garanderen. Het gaat echter niet alleen om toegang tot meer data. Organisaties hebben de juiste tools en platforms nodig om die data om te zetten in bruikbare inzichten. Dit is waar besluitvorming cruciaal wordt, vooral in een landschap waar nieuwe digitale supply chain-oplossingen en AI-gestuurde platforms u kunnen ondersteunen bij het stroomlijnen van veel processen binnen de beslissingsmatrix. […]
5 manieren om de snelheid van beslissingen in de toeleveringsketen te verbeterenDe belofte van een digitale supply chain heeft de manier waarop bedrijven opereren getransformeerd. In de kern kan het snelle, datagestuurde beslissingen nemen en tegelijkertijd kwaliteit en efficiëntie in de hele bedrijfsvoering garanderen. Het gaat echter niet alleen om toegang tot meer data. Organisaties hebben de juiste tools en platforms nodig om die data om te zetten in bruikbare inzichten. Dit is waar besluitvorming cruciaal wordt, vooral in een landschap waar nieuwe digitale supply chain-oplossingen en AI-gestuurde platforms u kunnen ondersteunen bij het stroomlijnen van veel processen binnen de beslissingsmatrix. […] 12 Oorzaken van Overstocking en Praktische OplossingenEffectief voorraadbeheer is cruciaal voor het behouden van een gezonde balans en het verzekeren dat middelen optimaal worden toegewezen. Hier is een diepgaande verkenning van de belangrijkste oorzaken van overstocking, hun implicaties en mogelijke oplossingen. […]
12 Oorzaken van Overstocking en Praktische OplossingenEffectief voorraadbeheer is cruciaal voor het behouden van een gezonde balans en het verzekeren dat middelen optimaal worden toegewezen. Hier is een diepgaande verkenning van de belangrijkste oorzaken van overstocking, hun implicaties en mogelijke oplossingen. […] FAQ: Slimme IP&O voor beter voorraadbeheer.Effectief supply chain- en voorraadbeheer zijn essentieel voor het bereiken van operationele efficiëntie en klanttevredenheid. Deze blog biedt duidelijke en beknopte antwoorden op enkele basisvragen en andere veelvoorkomende vragen van onze Smart IP&O-klanten, en biedt praktische inzichten om typische uitdagingen te overwinnen en uw voorraadbeheerpraktijken te verbeteren. Met de focus op deze belangrijke gebieden helpen we u complexe voorraadproblemen om te zetten in strategische, beheersbare acties die kosten verlagen en de algehele prestaties verbeteren met Smart IP&O. […]
FAQ: Slimme IP&O voor beter voorraadbeheer.Effectief supply chain- en voorraadbeheer zijn essentieel voor het bereiken van operationele efficiëntie en klanttevredenheid. Deze blog biedt duidelijke en beknopte antwoorden op enkele basisvragen en andere veelvoorkomende vragen van onze Smart IP&O-klanten, en biedt praktische inzichten om typische uitdagingen te overwinnen en uw voorraadbeheerpraktijken te verbeteren. Met de focus op deze belangrijke gebieden helpen we u complexe voorraadproblemen om te zetten in strategische, beheersbare acties die kosten verlagen en de algehele prestaties verbeteren met Smart IP&O. […] 7 belangrijke trends in vraagplanning die de toekomst vormgevenVraagplanning gaat verder dan alleen het voorspellen van productbehoeften; het gaat erom ervoor te zorgen dat uw bedrijf nauwkeurig, efficiënt en kosteneffectief aan de vraag van klanten voldoet. De nieuwste technologie voor vraagplanning pakt belangrijke uitdagingen aan, zoals nauwkeurigheid van voorspellingen, voorraadbeheer en marktresponsiviteit. In deze blog introduceren we kritieke trends voor vraagplanning, waaronder datagestuurde inzichten, probabilistische voorspellingen, consensusplanning, voorspellende analyses, scenariomodellering, realtime zichtbaarheid en multilevel voorspellingen. Deze trends helpen u om voorop te blijven lopen, uw toeleveringsketen te optimaliseren, kosten te verlagen en de klanttevredenheid te verbeteren, waardoor uw bedrijf op de lange termijn succesvol wordt. […]
7 belangrijke trends in vraagplanning die de toekomst vormgevenVraagplanning gaat verder dan alleen het voorspellen van productbehoeften; het gaat erom ervoor te zorgen dat uw bedrijf nauwkeurig, efficiënt en kosteneffectief aan de vraag van klanten voldoet. De nieuwste technologie voor vraagplanning pakt belangrijke uitdagingen aan, zoals nauwkeurigheid van voorspellingen, voorraadbeheer en marktresponsiviteit. In deze blog introduceren we kritieke trends voor vraagplanning, waaronder datagestuurde inzichten, probabilistische voorspellingen, consensusplanning, voorspellende analyses, scenariomodellering, realtime zichtbaarheid en multilevel voorspellingen. Deze trends helpen u om voorop te blijven lopen, uw toeleveringsketen te optimaliseren, kosten te verlagen en de klanttevredenheid te verbeteren, waardoor uw bedrijf op de lange termijn succesvol wordt. […]

Voorraadoptimalisatie voor fabrikanten, distributeurs en MRO
- Het beheren van de voorraad reserveonderdelen: beste praktijkenIn this blog, we’ll explore several effective strategies for managing spare parts inventory, emphasizing the importance of optimizing stock levels, maintaining service levels, and using smart tools to aid in decision-making. Managing spare parts inventory is a critical component for businesses that depend on equipment uptime and service reliability. Unlike regular inventory items, spare parts often have unpredictable demand patterns, making them more challenging to manage effectively. An efficient spare parts inventory management system helps prevent stockouts that can lead to operational downtime and costly delays while also avoiding overstocking that unnecessarily ties up capital and increases holding costs. […]
 Innovatie van de OEM-aftermarket met AI-gestuurde voorraadoptimalisatieDe aftermarketsector biedt OEM's een beslissend voordeel door een stabiele inkomstenstroom te bieden en de loyaliteit van klanten te bevorderen door de betrouwbare en tijdige levering van serviceonderdelen. Het beheren van inventaris en het voorspellen van de vraag in de aftermarket gaat echter gepaard met uitdagingen, waaronder onvoorspelbare vraagpatronen, enorme productassortimenten en de noodzaak van snelle doorlooptijden. Traditionele methoden schieten vaak tekort vanwege de complexiteit en variabiliteit van de vraag in de aftermarket. De nieuwste technologieën kunnen grote datasets analyseren om de toekomstige vraag nauwkeuriger te voorspellen en voorraadniveaus te optimaliseren, wat leidt tot betere service en lagere kosten. […]
Innovatie van de OEM-aftermarket met AI-gestuurde voorraadoptimalisatieDe aftermarketsector biedt OEM's een beslissend voordeel door een stabiele inkomstenstroom te bieden en de loyaliteit van klanten te bevorderen door de betrouwbare en tijdige levering van serviceonderdelen. Het beheren van inventaris en het voorspellen van de vraag in de aftermarket gaat echter gepaard met uitdagingen, waaronder onvoorspelbare vraagpatronen, enorme productassortimenten en de noodzaak van snelle doorlooptijden. Traditionele methoden schieten vaak tekort vanwege de complexiteit en variabiliteit van de vraag in de aftermarket. De nieuwste technologieën kunnen grote datasets analyseren om de toekomstige vraag nauwkeuriger te voorspellen en voorraadniveaus te optimaliseren, wat leidt tot betere service en lagere kosten. […] Toekomstbestendige hulpprogramma's: geavanceerde analyses voor optimalisatie van de supply chainNutsvoorzieningen op het gebied van elektriciteit, aardgas, stedelijk water en telecommunicatie zijn allemaal activa-intensief en afhankelijk van fysieke infrastructuur die in de loop van de tijd goed moet worden onderhouden, bijgewerkt en geüpgraded. Het maximaliseren van de uptime van bedrijfsmiddelen en de betrouwbaarheid van de fysieke infrastructuur vereist effectief voorraadbeheer, prognoses van reserveonderdelen en leveranciersbeheer. Een nutsbedrijf dat deze processen effectief uitvoert, presteert beter dan zijn concurrenten, levert een beter rendement op voor zijn investeerders en hogere serviceniveaus voor zijn klanten, terwijl het zijn impact op het milieu vermindert. […]
Toekomstbestendige hulpprogramma's: geavanceerde analyses voor optimalisatie van de supply chainNutsvoorzieningen op het gebied van elektriciteit, aardgas, stedelijk water en telecommunicatie zijn allemaal activa-intensief en afhankelijk van fysieke infrastructuur die in de loop van de tijd goed moet worden onderhouden, bijgewerkt en geüpgraded. Het maximaliseren van de uptime van bedrijfsmiddelen en de betrouwbaarheid van de fysieke infrastructuur vereist effectief voorraadbeheer, prognoses van reserveonderdelen en leveranciersbeheer. Een nutsbedrijf dat deze processen effectief uitvoert, presteert beter dan zijn concurrenten, levert een beter rendement op voor zijn investeerders en hogere serviceniveaus voor zijn klanten, terwijl het zijn impact op het milieu vermindert. […] Centreringswet: timing, prijzen en betrouwbaarheid van reserveonderdelenIn dit artikel begeleiden we u bij het opstellen van een voorraadplan voor reserveonderdelen, waarbij prioriteit wordt gegeven aan beschikbaarheidsstatistieken zoals serviceniveaus en vulpercentages, terwijl de kostenefficiëntie wordt gewaarborgd. We zullen ons concentreren op een benadering van voorraadplanning genaamd Service Level-Driven Inventory Optimization. Vervolgens bespreken we hoe u kunt bepalen welke onderdelen u in uw inventaris moet opnemen en welke onderdelen mogelijk niet nodig zijn. Ten slotte onderzoeken we manieren om uw op serviceniveau gebaseerde voorraadplan consistent te verbeteren. […]
Centreringswet: timing, prijzen en betrouwbaarheid van reserveonderdelenIn dit artikel begeleiden we u bij het opstellen van een voorraadplan voor reserveonderdelen, waarbij prioriteit wordt gegeven aan beschikbaarheidsstatistieken zoals serviceniveaus en vulpercentages, terwijl de kostenefficiëntie wordt gewaarborgd. We zullen ons concentreren op een benadering van voorraadplanning genaamd Service Level-Driven Inventory Optimization. Vervolgens bespreken we hoe u kunt bepalen welke onderdelen u in uw inventaris moet opnemen en welke onderdelen mogelijk niet nodig zijn. Ten slotte onderzoeken we manieren om uw op serviceniveau gebaseerde voorraadplan consistent te verbeteren. […]

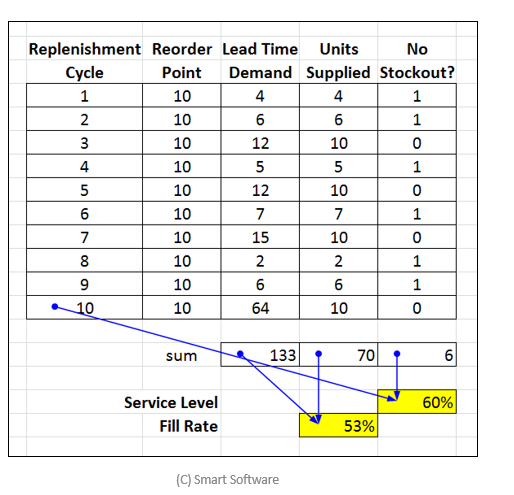 Prognoses zijn een middel om een doel te bereiken. Het doel is om voorraadniveaus te optimaliseren. Omdat de vraag onzeker is, moeten bedrijven die zelfs maar een matig serviceniveau moeten bieden, meer voorraad hebben dan de prognose, vaak veel meer. Maar betekent een lage voorspellingsfout niet een lagere veiligheidsvoorraad? Hoe beter mijn prognoses, hoe lager mijn voorraad? Ja waar. Maar waar het bij het bepalen van de benodigde voorraad om gaat, zijn zowel nauwkeurige prognoses van de meest waarschijnlijke vraag als nauwkeurige schattingen van de variabiliteit rond de meest waarschijnlijke vraag.
Prognoses zijn een middel om een doel te bereiken. Het doel is om voorraadniveaus te optimaliseren. Omdat de vraag onzeker is, moeten bedrijven die zelfs maar een matig serviceniveau moeten bieden, meer voorraad hebben dan de prognose, vaak veel meer. Maar betekent een lage voorspellingsfout niet een lagere veiligheidsvoorraad? Hoe beter mijn prognoses, hoe lager mijn voorraad? Ja waar. Maar waar het bij het bepalen van de benodigde voorraad om gaat, zijn zowel nauwkeurige prognoses van de meest waarschijnlijke vraag als nauwkeurige schattingen van de variabiliteit rond de meest waarschijnlijke vraag.


