Het dagelijkse voorraadbeheer kan u bezig houden. Er is het gebruikelijke ritme van bestellen, ontvangen, voorspellen en plannen, en dingen verplaatsen in het magazijn. Dan zijn er de hectische tijden – tekorten, spoedgevallen, last-minute telefoontjes om nieuwe leveranciers te vinden.
Al deze activiteiten werken tegen dat je even de tijd neemt om te kijken hoe het met je gaat. Maar je weet dat je af en toe je hoofd omhoog moet brengen om te zien waar je naartoe gaat. Daarvoor moet uw inventarissoftware u statistieken tonen – en niet slechts één, maar een volledige set statistieken of KPI's – Key Performance Indicators.
Meerdere statistieken
Afhankelijk van uw rol in uw organisatie zullen verschillende statistieken een verschillende saillantie hebben. Als u zich bezighoudt met de financiële kant van het huis, kan het investeren in inventaris van cruciaal belang zijn: hoeveel geld zit er vast in de inventaris? Als u aan de verkoopkant werkt, kan de beschikbaarheid van artikelen een prioriteit zijn: hoe groot is de kans dat ik 'ja' kan zeggen tegen een bestelling? Als u verantwoordelijk bent voor de bevoorrading, hoeveel inkooporders moeten uw mensen dan het volgende kwartaal schrappen?
Beschikbaarheidsstatistieken
Laten we teruggaan naar de beschikbaarheid van artikelen. Hoe plak je daar een getal op? De twee meest gebruikte beschikbaarheidsstatistieken zijn ‘serviceniveau’ en ‘opvullingspercentage’. Wat is het verschil? Het is het verschil tussen zeggen: “We hebben gisteren een aardbeving gehad” en zeggen: “We hebben gisteren een aardbeving gehad, en die had een kracht van 6,4 op de schaal van Richter.” Serviceniveau registreert de frequentie van stockouts, ongeacht de omvang ervan; het opvullingspercentage weerspiegelt de ernst ervan. De twee kunnen in tegengestelde richtingen lijken te wijzen, wat voor enige verwarring zorgt. U kunt een goed serviceniveau hebben, bijvoorbeeld 90%, maar een gênant opvullingspercentage, bijvoorbeeld 50%. Of vice versa. Wat hen anders maakt, is de verdeling van de vraaggroottes. Als de verdeling bijvoorbeeld erg scheef is, dus de meeste eisen zijn klein, maar sommige zijn enorm, dan kun je de hierboven genoemde 90%/50%-verdeling krijgen. Als uw focus ligt op hoe vaak u moet nabestellen, is het serviceniveau relevanter. Als u zich zorgen maakt over hoe groot een nachtelijke expedite kan worden, is het opvullingspercentage relevanter.
Eén grafiek om ze allemaal te regeren
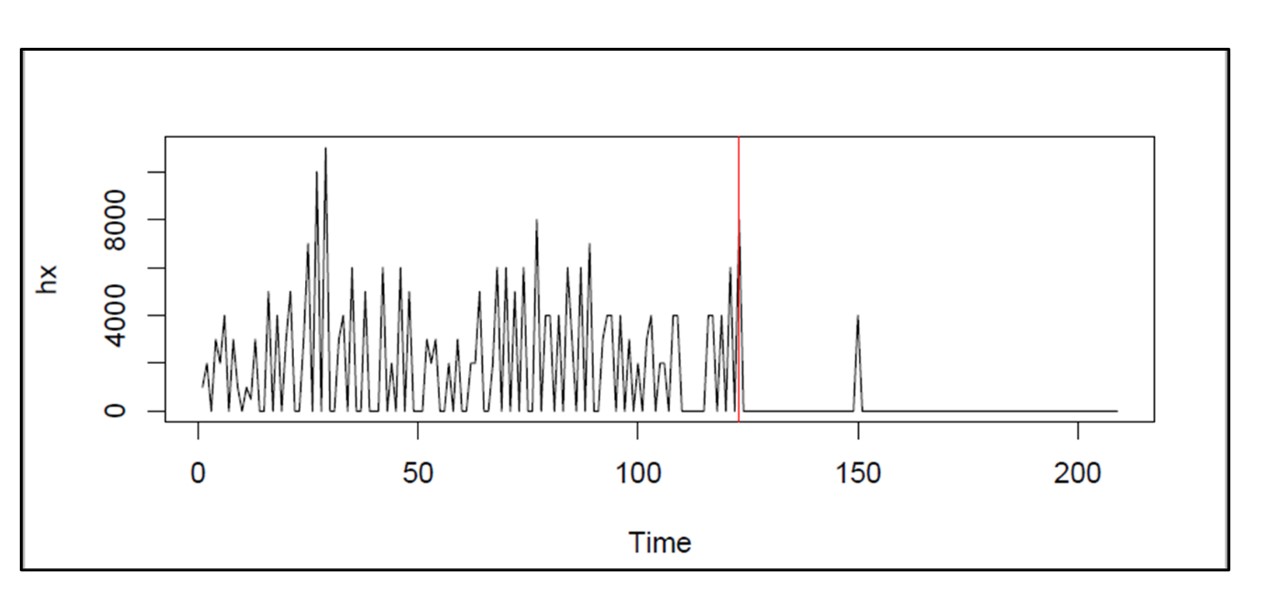
Een grafiek van de voorhanden voorraad kan de basis vormen voor het berekenen van meerdere KPI's. Kijk eens naar Figuur 1, waarin de grafieken een jaar lang elke dag bij de hand zijn. Dit diagram bevat informatie die nodig is om meerdere statistieken te berekenen: voorraadinvestering, serviceniveau, opvullingspercentage, bestelpercentage en andere statistieken.
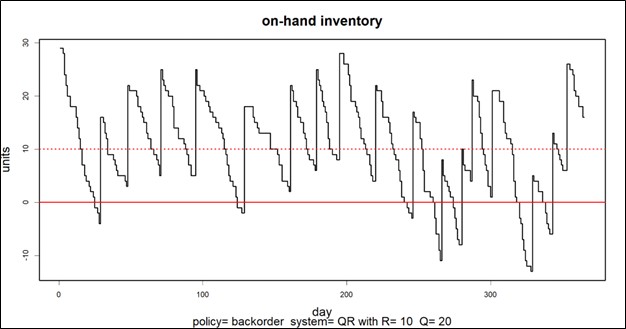
Voorraadinvestering: de gemiddelde hoogte van de grafiek boven nul, vermenigvuldigd met de eenheidskosten van het voorraaditem, geeft een kwartaalwaarde in dollar.
Serviceniveau: Het deel van de voorraadcycli dat boven nul eindigt, is het serviceniveau. Voorraadcycli worden gekenmerkt door de opwaartse bewegingen die worden veroorzaakt door de komst van aanvullingsorders.
Opvullingspercentage: De hoeveelheid waarmee de voorraad onder nul daalt en hoe lang de voorraad daar blijft, bepalen samen het opvullingspercentage.
In dit geval was het gemiddelde aantal beschikbare eenheden 10,74, het serviceniveau 54% en het opvullingspercentage 91%.
KPI's en KPP's
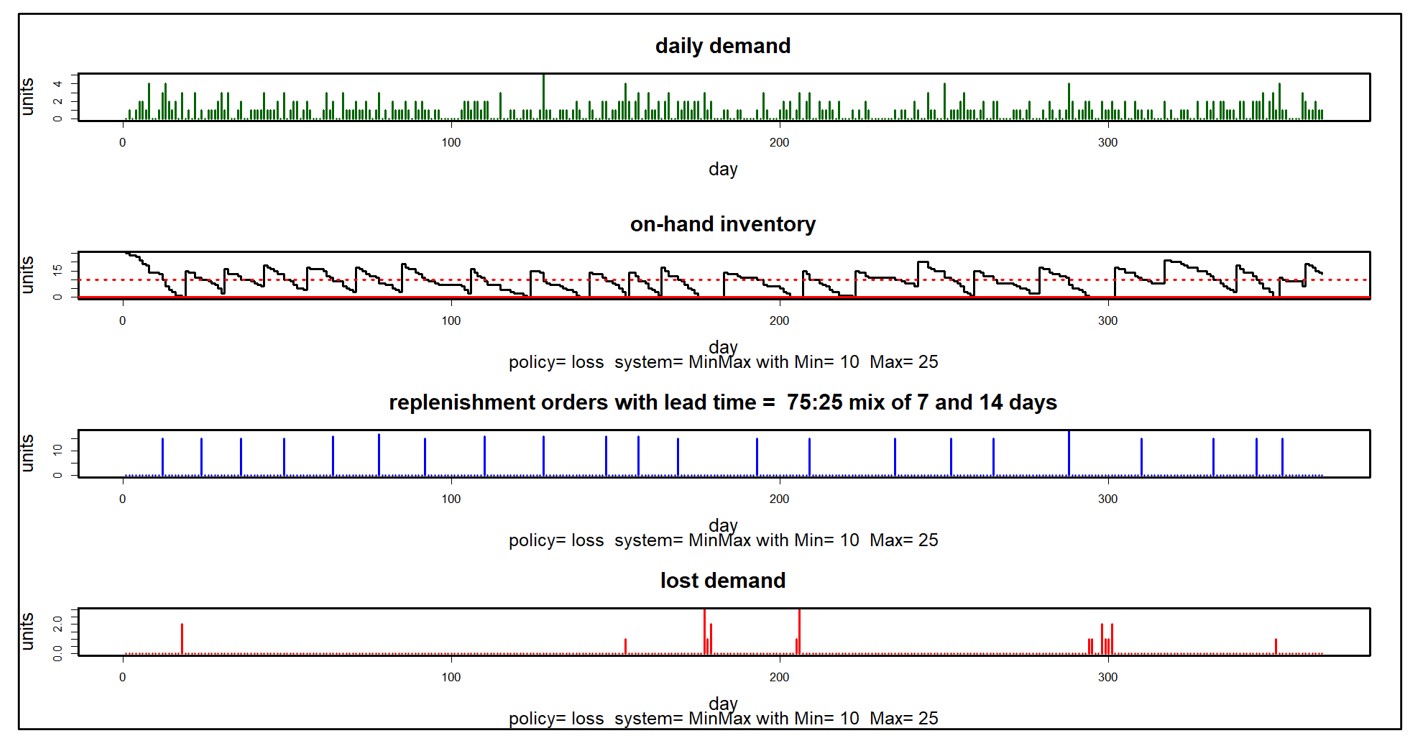
In de ruim veertig jaar sinds we Smart Software hebben opgericht, heb ik nog nooit een klant een plot als figuur 1 zien maken. Degenen die verder in hun ontwikkeling zijn, produceren en besteden aandacht aan rapporten waarin hun KPI's in tabelvorm worden vermeld, maar dat doen ze niet' Kijk niet naar zo'n grafiek. Niettemin heeft die grafiek waarde voor het ontwikkelen van inzicht in de willekeurige ritmes van de voorraad terwijl deze stijgt en daalt.
Waar het vooral nuttig is, is prospectief. Gezien de marktvolatiliteit verschuiven belangrijke variabelen zoals de doorlooptijden van leveranciers, de gemiddelde vraag en de variabiliteit van de vraag allemaal in de loop van de tijd. Dit impliceert dat belangrijke controleparameters zoals bestelpunten en bestelhoeveelheden zich aan deze verschuivingen moeten aanpassen. Als een leverancier bijvoorbeeld zegt dat hij zijn gemiddelde doorlooptijd met twee dagen moet verlengen, heeft dit een negatieve invloed op uw statistieken en moet u mogelijk uw bestelpunt verhogen om dit te compenseren. Maar met hoeveel verhogen?
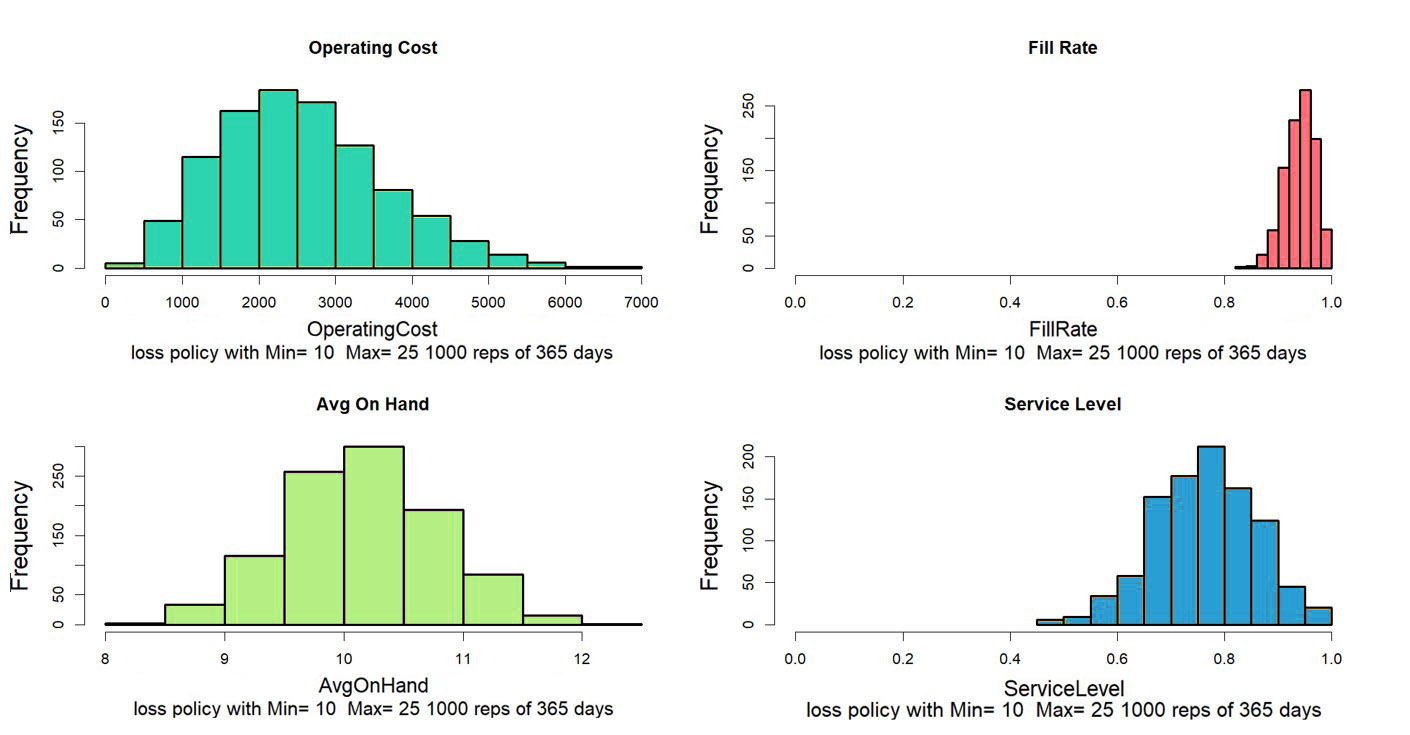
Hier komt moderne inventarisatiesoftware om de hoek kijken. Hiermee kunt u een aanpassing voorstellen en vervolgens zien hoe de zaken zullen verlopen. Percelen zoals Figuur 1 laten je het nieuwe regime zien en er een gevoel voor krijgen. En de grafieken kunnen worden geanalyseerd om KPP's te berekenen: Key Performance Predictions.
De hulp van KPP maakt het giswerk bij aanpassingen overbodig. U kunt simuleren wat er met uw KPI's zal gebeuren als u deze wijzigt als reactie op veranderingen in uw werkomgeving – en hoe slecht de situatie zal zijn als u geen wijzigingen aanbrengt.