Wat is er anders aan voorraadplanning voor onderhoud, reparatie en bewerkingen (MRO) vergeleken met voorraadplanning in productie- en distributieomgevingen? Kortom, het is de aard van de vraagpatronen in combinatie met het gebrek aan bruikbare bedrijfskennis.
Vraagpatronen
Fabrikanten en distributeurs hebben de neiging zich te concentreren op de topverkopers die het grootste deel van hun omzet genereren. Er is doorgaans een grote vraag naar deze artikelen, die relatief eenvoudig te voorspellen zijn met traditionele tijdreeksmodellen die inspelen op voorspelbare trends en/of seizoensinvloeden. Daarentegen hebben MRO-planners bijna altijd te maken met een intermitterende vraag, die schaarser, willekeuriger en moeilijker te voorspellen is. Bovendien zijn de fundamentele hoeveelheden van belang verschillend. MRO-planners geven uiteindelijk het meeste om de ‘wanneer’-vraag: wanneer gaat er iets kapot? Terwijl de anderen zich concentreren op de “hoeveel” vraag van verkochte eenheden.
Zakelijke kennis
Productie- en distributieplanners kunnen vaak rekenen op het verzamelen van klant- en verkoopfeedback, die kan worden gecombineerd met statistische methoden om de nauwkeurigheid van de prognoses te verbeteren. Aan de andere kant zijn lagers, tandwielen, verbruiksartikelen en repareerbare onderdelen zelden bereid hun mening te delen. Met MRO is bedrijfskennis over welke onderdelen nodig zijn en wanneer niet betrouwbaar (behalve gepland onderhoud wanneer verbruiksartikelen in grotere volumes worden vervangen). Het succes van de MRO-voorraadplanning gaat dus slechts zo ver als het vermogen van hun waarschijnlijkheidsmodellen om toekomstig gebruik te voorspellen. En omdat de vraag zo wisselend is, kunnen ze met traditionele benaderingen niet voorbij Go komen.
Methoden voor MRO
In de praktijk is het gebruikelijk dat MRO- en activa-intensieve bedrijven hun voorraden beheren door hun toevlucht te nemen tot statische Min/Max-niveaus op basis van subjectieve veelvouden van gemiddeld gebruik, aangevuld met incidentele handmatige aanpassingen op basis van onderbuikgevoelens. Het proces wordt een slechte mix van statisch en reactief, met als resultaat dat er veel tijd en geld wordt verspild aan het versnellen.
Er zijn alternatieve planningsmethoden die meer op wiskunde en data zijn gebaseerd, hoewel deze stijl van plannen bij MRO minder gebruikelijk is dan in de andere domeinen. Er zijn twee toonaangevende benaderingen voor het modelleren van defecten aan onderdelen en machines: modellen gebaseerd op de betrouwbaarheidstheorie en modellen voor ‘conditiegebaseerd onderhoud’ gebaseerd op realtime monitoring.
Betrouwbaarheidsmodellen
Betrouwbaarheidsmodellen zijn de eenvoudigste van de twee en vereisen minder gegevens. Ze gaan ervan uit dat alle artikelen van hetzelfde type, bijvoorbeeld een bepaald reserveonderdeel, statistisch gelijkwaardig zijn. Hun belangrijkste onderdeel is een ‘gevarenfunctie’, die het risico op falen in het volgende korte tijdsinterval beschrijft. De gevarenfunctie kan worden vertaald in iets dat beter geschikt is voor besluitvorming: de ‘overlevingsfunctie’, wat de waarschijnlijkheid is dat het item nog steeds werkt na X gebruiksduur (waarbij X kan worden uitgedrukt in dagen, maanden, kilometers, gebruik, enz.). Figuur 1 toont een constante gevaarfunctie en de bijbehorende overlevingsfunctie.
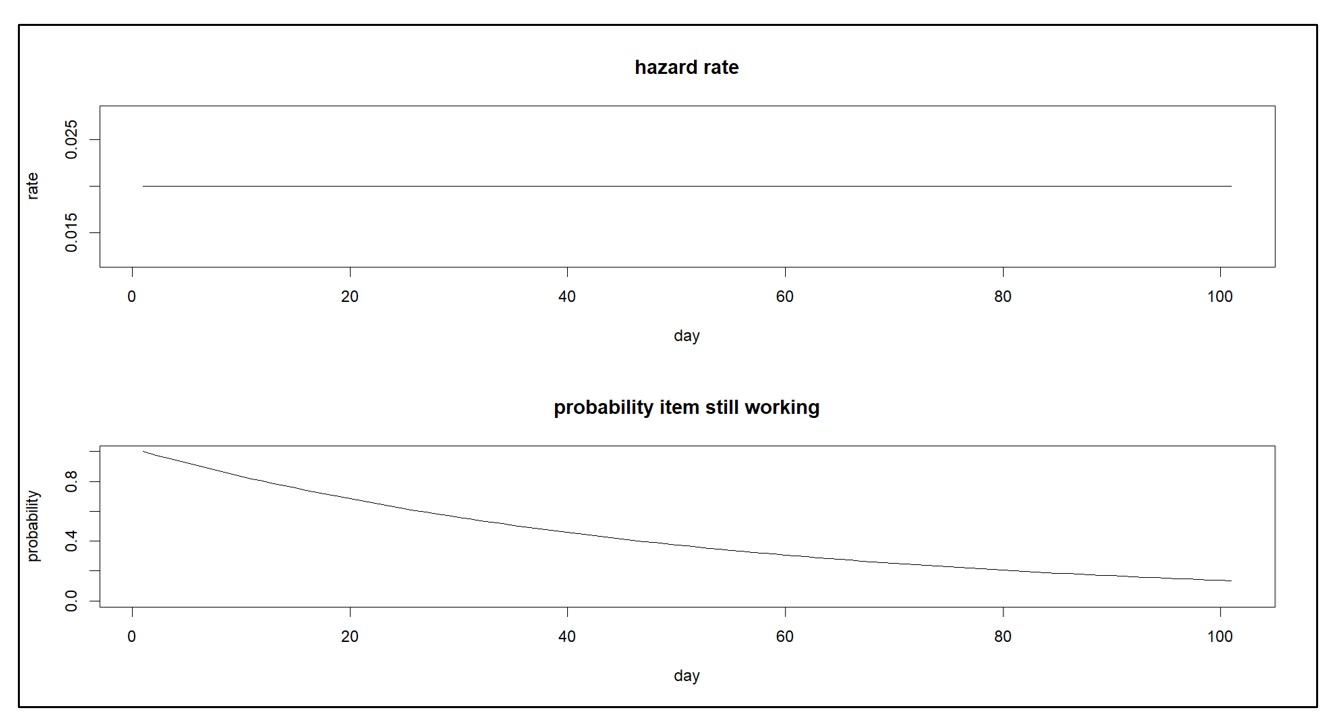
Figuur 1: Constante gevarenfunctie en zijn overlevingsfunctie
Een gevarenfunctie die niet verandert, houdt in dat alleen willekeurige ongelukken een storing veroorzaken. Een gevaarfunctie die in de loop van de tijd toeneemt, impliceert daarentegen dat het artikel versleten is. En een afnemende gevaarfunctie impliceert dat een item zich vestigt. Figuur 2 toont een toenemende gevaarfunctie en de bijbehorende overlevingsfunctie.
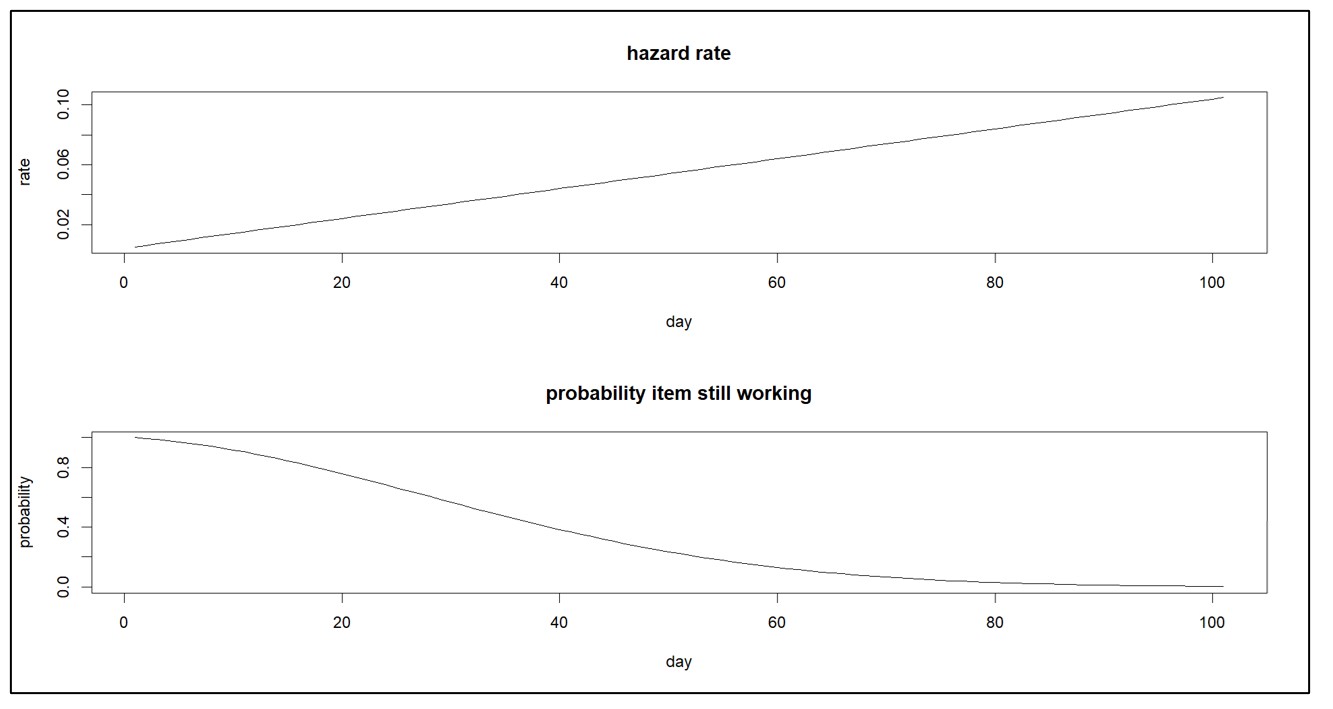
Figuur 2: Toenemende gevarenfunctie en zijn overlevingsfunctie
Betrouwbaarheidsmodellen worden vaak gebruikt voor goedkope onderdelen, zoals mechanische bevestigingsmiddelen, waarvan de vervanging misschien niet moeilijk of duur is (maar toch essentieel kan zijn).
Conditiegebaseerd onderhoud
Modellen gebaseerd op real-time monitoring worden gebruikt ter ondersteuning van condition-based onderhoud (CBM) voor dure zaken als straalmotoren. Deze modellen gebruiken gegevens van sensoren die in de items zelf zijn ingebed. Dergelijke gegevens zijn doorgaans complex en bedrijfseigen, evenals de waarschijnlijkheidsmodellen die door de gegevens worden ondersteund. Het voordeel van real-time monitoring is dat je problemen kunt zien aankomen, dat wil zeggen dat de verslechtering zichtbaar wordt gemaakt en dat voorspellingen kunnen voorspellen wanneer het item de rode lijn zal bereiken en daarom uit het speelveld moet worden gehaald. Dit maakt geïndividualiseerd, proactief onderhoud of vervanging van het artikel mogelijk.
Figuur 3 illustreert het soort gegevens dat in CBM wordt gebruikt. Elke keer dat het systeem wordt gebruikt, is er een bijdrage aan de cumulatieve slijtage ervan. (Houd er echter rekening mee dat gebruik soms de staat van het apparaat kan verbeteren, bijvoorbeeld wanneer regen een machine koel houdt). U kunt de algemene trend naar boven zien richting een rode lijn, waarna het apparaat onderhoud nodig heeft. U kunt de cumulatieve slijtage extrapoleren om in te schatten wanneer deze de rode lijn zal bereiken en dienovereenkomstig plannen.
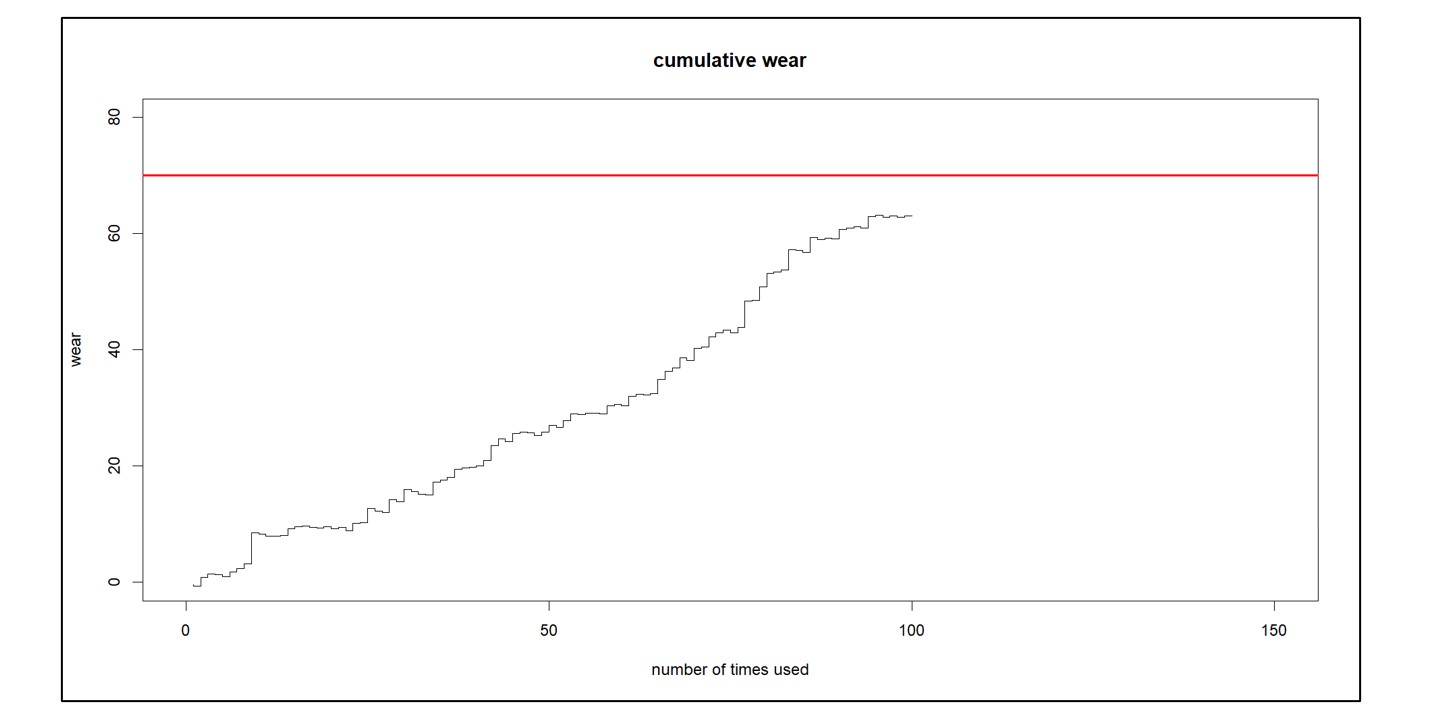
Figuur 3: Ter illustratie van real-time monitoring voor conditiegebaseerd onderhoud
Voor zover ik weet, maakt niemand zulke modellen van klanten met eindproducten om te voorspellen wanneer en hoeveel ze de volgende keer zullen bestellen, misschien omdat de klanten er bezwaar tegen zouden hebben om voortdurend hersenmonitors te dragen. Maar CBM, met zijn complexe monitoring en modellering, wint aan populariteit voor systemen die niet kunnen falen, zoals straalmotoren. Ondertussen hebben klassieke betrouwbaarheidsmodellen nog steeds veel waarde voor het beheer van grote vloten met goedkopere maar nog steeds essentiële artikelen.
Smart's aanpak
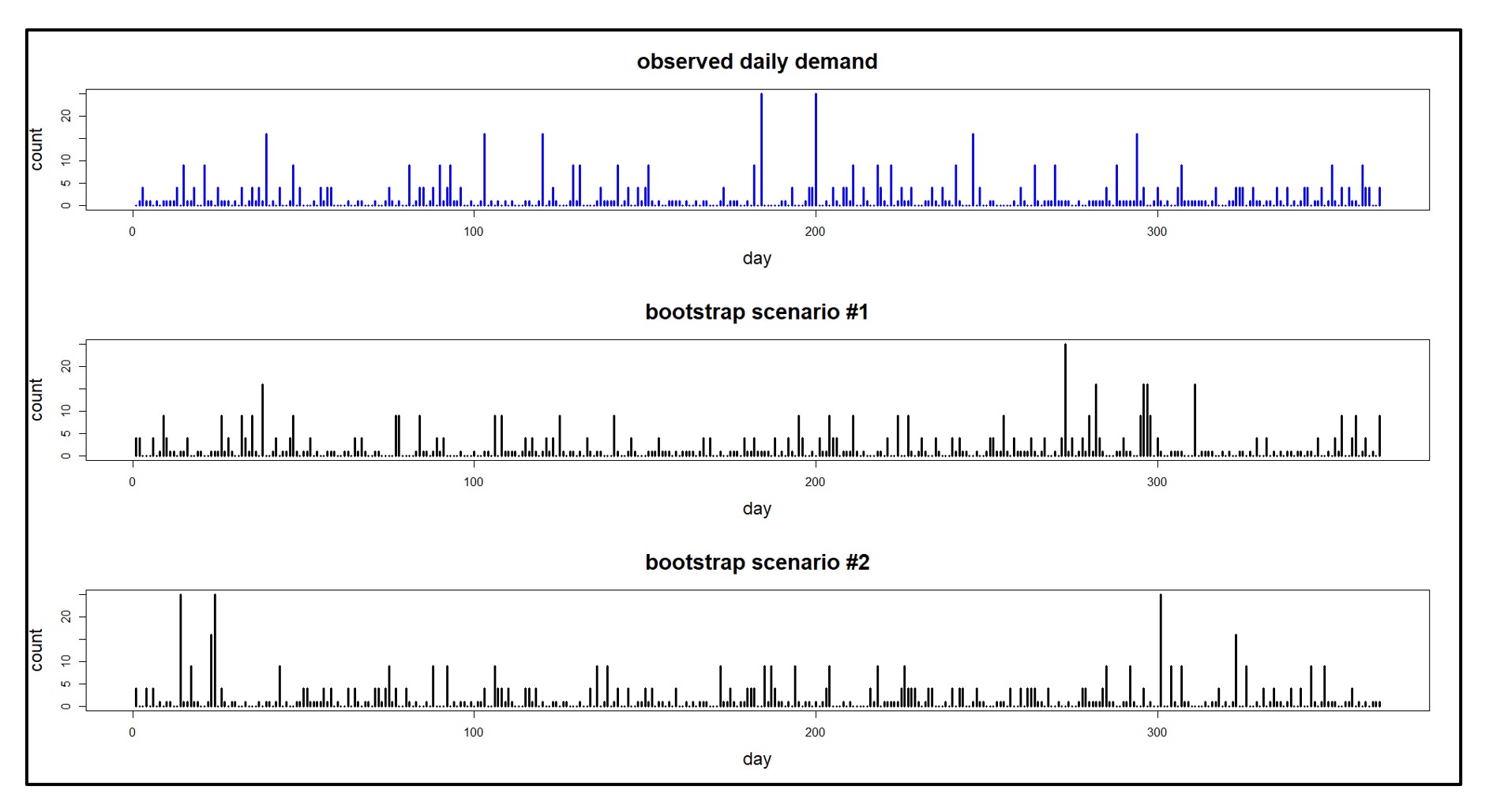
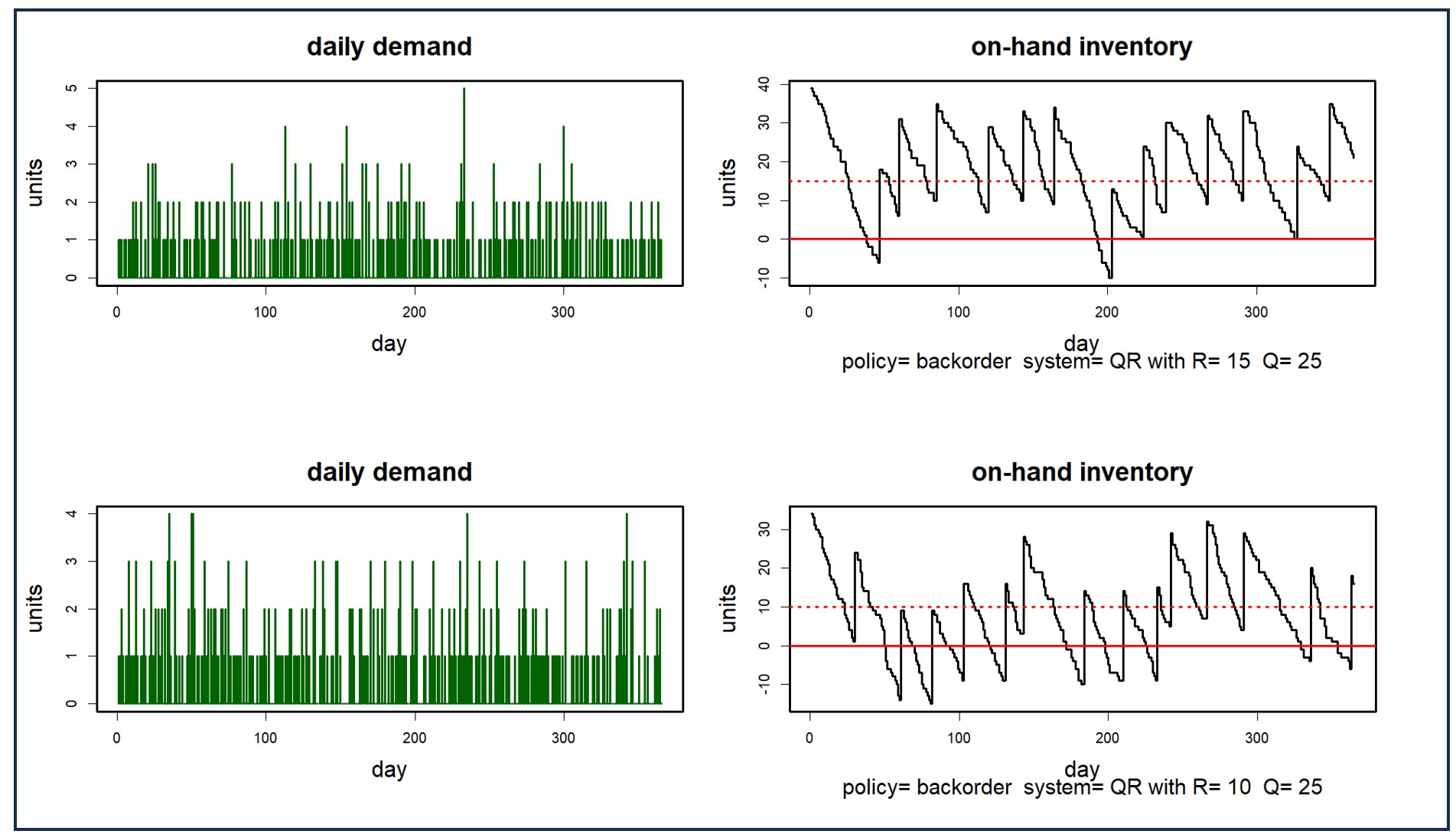
De bovengenoemde op condities gebaseerde onderhouds- en betrouwbaarheidsbenaderingen vereisen een buitensporige last voor het verzamelen en opschonen van gegevens die veel MRO-bedrijven niet aankunnen. Voor die bedrijven biedt Smart een aanpak waarbij geen betrouwbaarheidsmodellen hoeven te worden ontwikkeld. In plaats daarvan exploiteert het gebruiksgegevens op een andere manier. Het maakt gebruik van op waarschijnlijkheid gebaseerde modellen van zowel gebruik als doorlooptijden van leveranciers om duizenden mogelijke scenario's voor doorlooptijden van bevoorrading en vraag te simuleren. Het resultaat is een nauwkeurige verdeling van de vraag en de doorlooptijden voor elk verbruiksonderdeel, die kan worden benut om de optimale voorraadparameters te bepalen. Figuur 4 toont een simulatie die begint met een scenario voor de vraag naar reserveonderdelen (bovenste grafiek) en vervolgens een scenario oplevert van voorhanden aanbod voor bepaalde keuzes van Min/Max-waarden (onderste lijn). Key Performance Indicators (KPI's) kunnen worden geschat door de resultaten van veel van dergelijke simulaties te middelen.

Figuur 4: Een voorbeeld van een simulatie van de vraag naar reserveonderdelen en de voorhanden voorraad
U kunt hier lezen over de aanpak van Smart bij het voorspellen van reserveonderdelen: https://smartcorp.com/wp-content/uploads/2019/10/Probabilistic-Forecasting-for-Intermittent-Demand.pdf