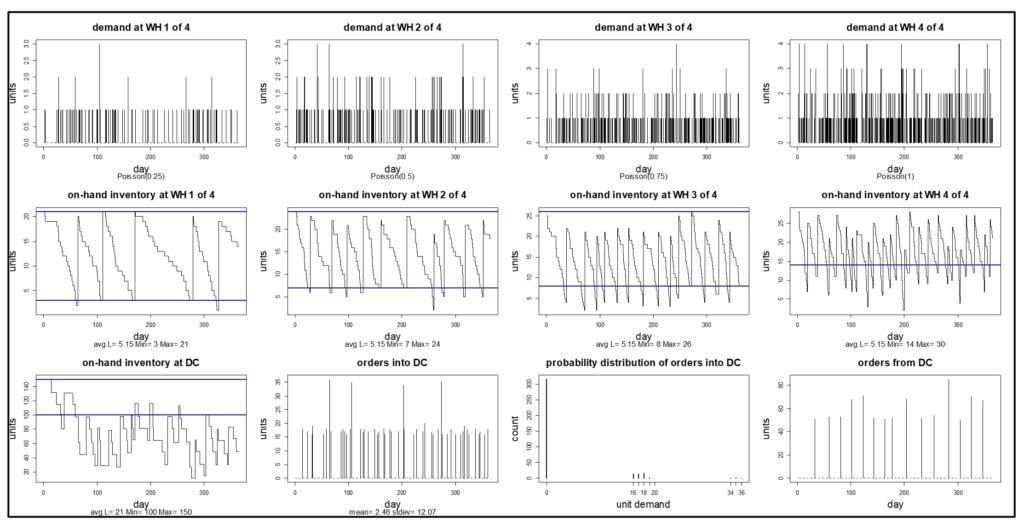
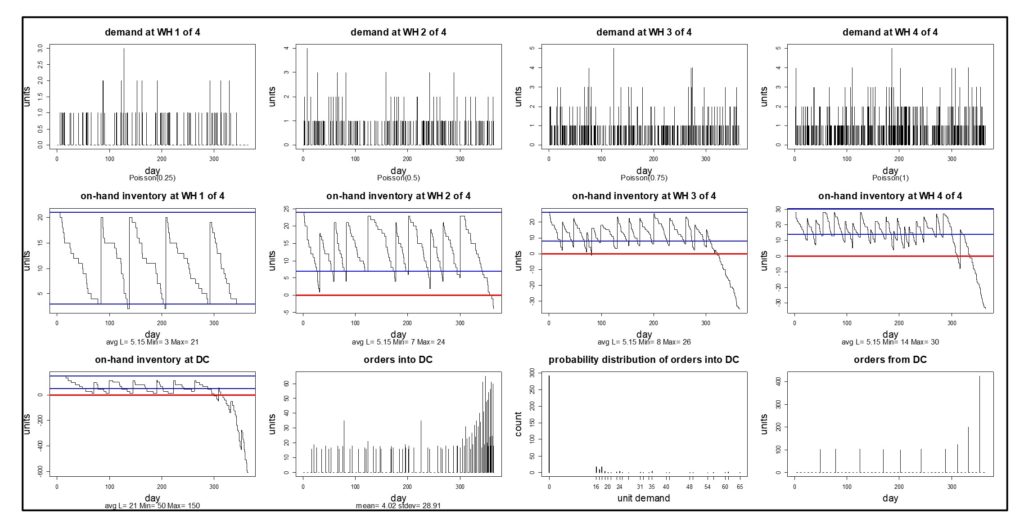
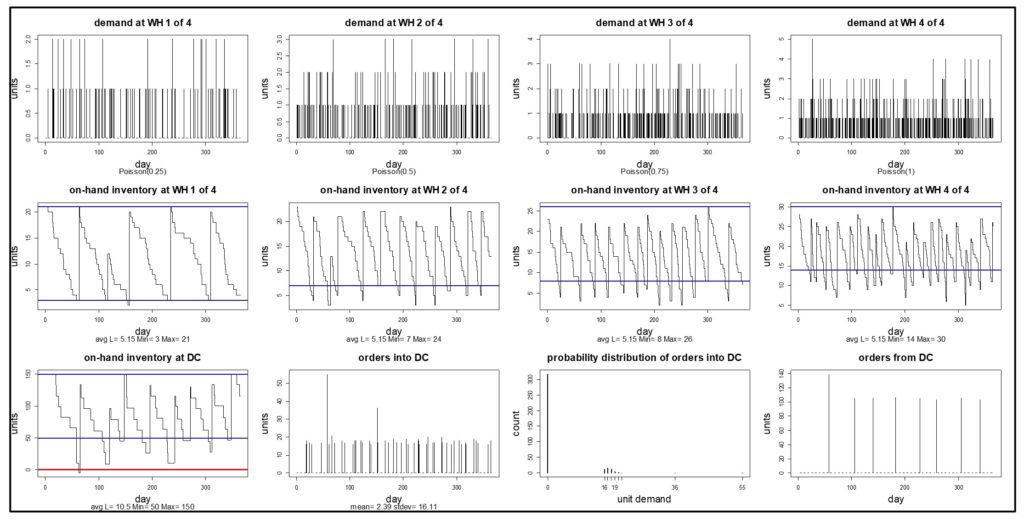
Este blog proporciona una descripción general de este tema escrito para no expertos. Eso
- explica por qué es posible que desee leer este blog.
- enumera los diversos tipos de "mantenimiento de la máquina".
- explica qué es el “modelado probabilístico”.
- describe modelos para predecir el tiempo de inactividad.
- explica lo que estos modelos pueden hacer por usted.
Importancia del tiempo de inactividad
Si fabrica cosas para la venta, necesita máquinas para hacer esas cosas. Si sus máquinas están en funcionamiento, tiene una gran oportunidad de ganar dinero. Si sus máquinas no funcionan, pierde oportunidades de ganar dinero. Dado que el tiempo de inactividad es tan fundamental, vale la pena invertir dinero y pensar en minimizar el tiempo de inactividad. Por pensamiento me refiero a matemáticas de probabilidad, ya que tiempo de inactividad de la máquina es inherentemente un fenómeno aleatorio. Modelos de probabilidad puede orientar las políticas de mantenimiento.
Políticas de mantenimiento de máquinas
El mantenimiento es su defensa contra el tiempo de inactividad. Existen varios tipos de políticas de mantenimiento, que van desde "No hacer nada y esperar a que falle" hasta enfoques analíticos sofisticados que involucran sensores y modelos de probabilidad de falla.
Una lista útil de políticas de mantenimiento es:
- Sentarse y esperar problemas, luego sentarse un poco más preguntándose qué hacer cuando los problemas inevitablemente suceden. Esto es tan tonto como suena.
- Igual que el anterior, excepto que se prepara para el fracaso de minimizar el tiempo de inactividad, por ejemplo, el almacenamiento de piezas de repuesto.
- Comprobación periódica de problemas inminentes junto con intervenciones como la lubricación de piezas móviles o la sustitución de piezas desgastadas.
- Basar la programación del mantenimiento en datos sobre el estado de la máquina en lugar de depender de un programa fijo; requiere la recopilación y el análisis continuos de datos. Esto se llama mantenimiento basado en la condición.
- Usar los datos sobre el estado de la máquina de forma más agresiva al convertirlos en predicciones de tiempo de falla y sugerencias de pasos a seguir para retrasar la falla. Esto se llama mantenimiento predictivo.
Los últimos tres tipos de mantenimiento se basan en matemáticas de probabilidad para establecer un programa de mantenimiento, o determinar cuándo los datos sobre el estado de la máquina requieren intervención, o calcular cuándo podría ocurrir una falla y cuál es la mejor manera de posponerla.
Modelos de probabilidad de falla de la máquina
El tiempo que una máquina funcionará antes de que falle es una variable aleatoria. Así es el tiempo que pasará abajo. La teoría de la probabilidad es la parte de las matemáticas que trata con variables aleatorias. Las variables aleatorias se describen por sus distribuciones de probabilidad, por ejemplo, ¿cuál es la probabilidad de que la máquina funcione durante 100 horas antes de que se apague? 200 horas? O, de manera equivalente, ¿cuál es la probabilidad de que la máquina siga funcionando después de 100 o 200 horas?
Un subcampo llamado "teoría de la confiabilidad" responde a este tipo de preguntas y aborda conceptos relacionados como el tiempo medio antes de la falla (MTBF), que es un resumen abreviado de la información codificada en la distribución de probabilidad del tiempo antes de la falla.
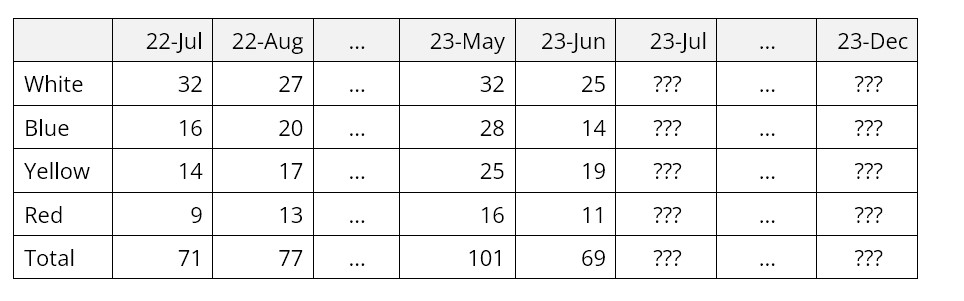
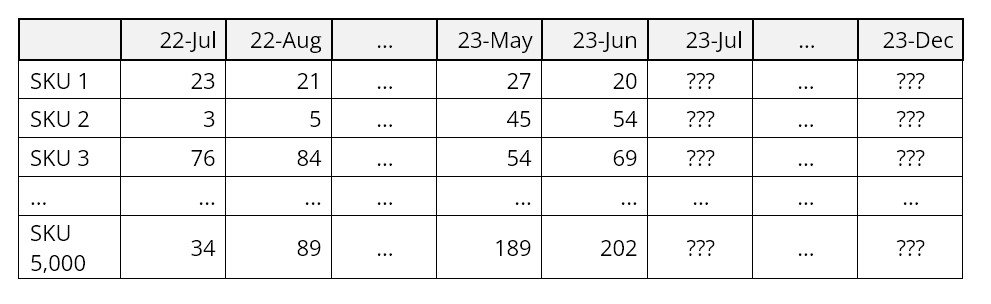
La Figura 1 muestra datos sobre el tiempo antes de la falla de las unidades de aire acondicionado. Este tipo de trama representa la distribución de probabilidad acumulada y muestra la posibilidad de que una unidad haya fallado después de que haya transcurrido cierto tiempo. La Figura 2 muestra un función de confiabilidad, trazando el mismo tipo de información en un formato inverso, es decir, representando la posibilidad de que una unidad siga funcionando después de que haya transcurrido cierto tiempo.
En la Figura 1, las marcas azules junto al eje x muestran los momentos en los que se observaron fallas en los acondicionadores de aire individuales; Estos son los datos básicos. La curva negra muestra la proporción acumulada de unidades que fallaron a lo largo del tiempo. La curva roja es una aproximación matemática a la curva negra, en este caso una distribución exponencial. Los gráficos muestran que alrededor del 80 por ciento de las unidades fallarán antes de las 100 horas de funcionamiento.
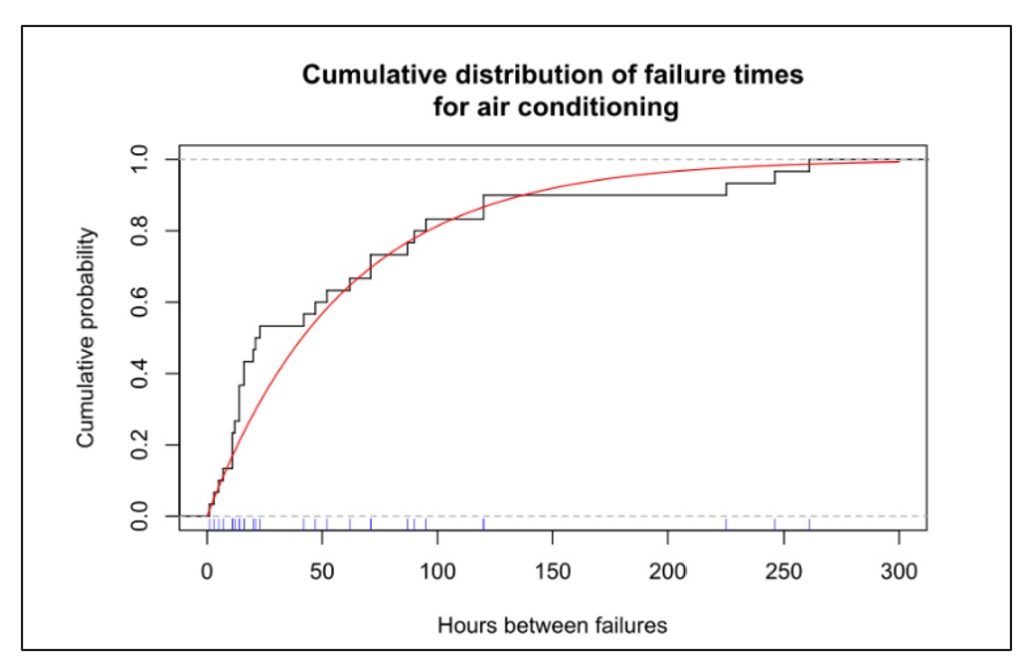
Figura 1 Función de distribución acumulativa del tiempo de actividad de los aires acondicionados
Los modelos de probabilidad se pueden aplicar a una pieza, componente o subsistema individual, a un conjunto de piezas relacionadas (p. ej., "el sistema hidráulico") oa una máquina completa. Cualquiera de estos puede describirse mediante la distribución de probabilidad del tiempo antes de que falle.
La Figura 2 muestra la función de confiabilidad de seis subsistemas en una máquina para excavar túneles. El gráfico muestra que el subsistema más fiable son los brazos de corte y el menos fiable es el subsistema de agua. La confiabilidad de todo el sistema podría aproximarse multiplicando las seis curvas (porque para que el sistema funcione como un todo, todos los subsistemas deben estar funcionando), lo que daría como resultado un intervalo muy corto antes de que algo salga mal.
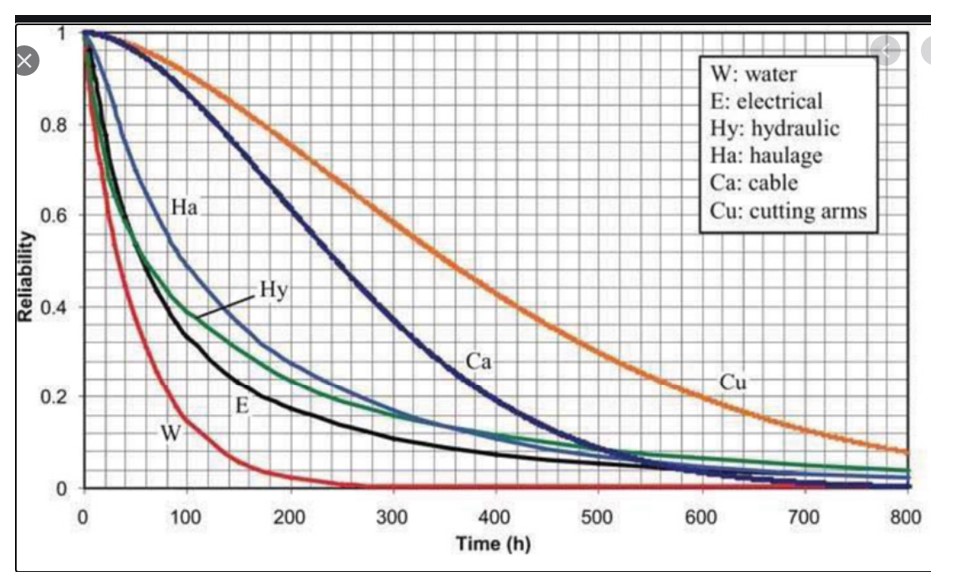
Figura 2 Ejemplos de distribuciones de probabilidad de subsistemas en una tuneladora
Varios factores influyen en la distribución del tiempo antes de la falla. Invertir en mejores piezas prolongará la vida útil del sistema. También lo hará la inversión en redundancia. Lo mismo ocurrirá con la sustitución de pars usados por nuevos.
Una vez que se dispone de una distribución de probabilidad, se puede utilizar para responder a cualquier cantidad de preguntas hipotéticas, como se ilustra a continuación en la sección Beneficios de los modelos.
Enfoques para modelar la confiabilidad de la máquina
Los modelos de probabilidad pueden describir las unidades más básicas, como componentes individuales del sistema (Figura 2), o conjuntos de unidades básicas, como máquinas completas (Figura 1). De hecho, una máquina completa se puede modelar como una sola unidad o como una colección de componentes. Si se trata una máquina completa como una sola unidad, la distribución de probabilidad de vida útil representa un resumen del efecto combinado de las distribuciones de vida útil de cada componente.
Si tenemos un modelo de una máquina completa, podemos saltar a modelos de colecciones de máquinas. Si, en cambio, comenzamos con modelos de la vida útil de los componentes individuales, de alguna manera debemos combinar esos modelos individuales en un modelo general de la máquina completa.
Aquí es donde las matemáticas pueden ponerse peludas. El modelado siempre requiere un equilibrio sabio entre la simplificación, para que algunos resultados sean posibles, y la complicación, para que cualquier resultado que surja sea realista. El truco habitual es asumir que las fallas de las piezas individuales del sistema ocurren de manera independiente.
Si podemos suponer que las fallas ocurren de manera independiente, generalmente es posible modelar colecciones de máquinas. Por ejemplo, suponga que una línea de producción tiene cuatro máquinas que producen el mismo producto. Tener un modelo de confiabilidad para una sola máquina (como en la Figura 1) nos permite predecir, por ejemplo, la posibilidad de que solo tres de las máquinas sigan funcionando dentro de una semana. Incluso aquí puede haber una complicación: la probabilidad de que una máquina que funciona hoy siga funcionando mañana a menudo depende de cuánto tiempo haya pasado desde su última falla. Si el tiempo entre fallas tiene una distribución exponencial como la de la Figura 1, resulta que el tiempo de la próxima falla no depende de cuánto tiempo ha pasado desde la última falla. Desafortunadamente, muchos o incluso la mayoría de los sistemas no tienen distribuciones exponenciales de tiempo de actividad, por lo que la complicación persiste.
Peor aún, si comenzamos con modelos de confiabilidad de muchos componentes individuales, avanzar hasta predecir los tiempos de falla para toda la máquina compleja puede ser casi imposible si tratamos de trabajar directamente con todas las ecuaciones relevantes. En tales casos, la única forma práctica de obtener resultados es utilizar otro estilo de modelado: la simulación Monte Carlo.
La simulación de Monte Carlo es una forma de sustituir la computación por el análisis cuando es posible crear escenarios aleatorios de operación del sistema. El uso de la simulación para extrapolar la confiabilidad de la máquina a partir de la confiabilidad de los componentes funciona de la siguiente manera.
- Comience con las funciones de distribución acumulativa (Figura 1) o funciones de confiabilidad (Figura 2) de cada componente de la máquina.
- Cree una muestra aleatoria de la vida útil de cada componente para obtener un conjunto de tiempos de falla de muestra consistentes con su función de confiabilidad.
- Utilizando la lógica de cómo se relacionan los componentes entre sí, calcule el tiempo de falla de toda la máquina.
- Repita los pasos 1 a 3 muchas veces para ver la gama completa de posibles vidas útiles de la máquina.
- Opcionalmente, promedie los resultados del paso 4 para resumir la vida útil de la máquina con métricas como el MTBF o la posibilidad de que la máquina funcione más de 500 horas antes de fallar.
El paso 1 sería un poco complicado si no tenemos un buen modelo de probabilidad para la vida útil de un componente, por ejemplo, algo como la línea roja en la Figura 1.
El paso 2 puede requerir una contabilidad cuidadosa. A medida que avanza el tiempo en la simulación, algunos componentes fallarán y serán reemplazados, mientras que otros seguirán funcionando. A menos que la vida útil de un componente tenga una distribución exponencial, su vida útil restante dependerá de cuánto tiempo el componente haya estado en uso continuo. Así que este paso debe dar cuenta de los fenómenos de marcar a fuego o desgastar.
El paso 3 es diferente de los demás en que requiere algo de matemática básica, aunque de un tipo simple. Si la Máquina A solo funciona cuando los componentes 1 y 2 funcionan, entonces (suponiendo que la falla de un componente no influya en la falla del otro)
Probabilidad [A funciona] = Probabilidad [1 funciona] x Probabilidad [2 funciona].
Si, en cambio, la Máquina A funciona si el componente 1 funciona o el componente 2 funciona o ambos funcionan, entonces
Probabilidad [A falla] = Probabilidad [1 falla] x Probabilidad [2 fallas]
entonces Probabilidad [A funciona] = 1 – Probabilidad [A falla].
El paso 4 puede implicar la creación de miles de escenarios para mostrar la gama completa de resultados aleatorios. La computación es rápida y barata.
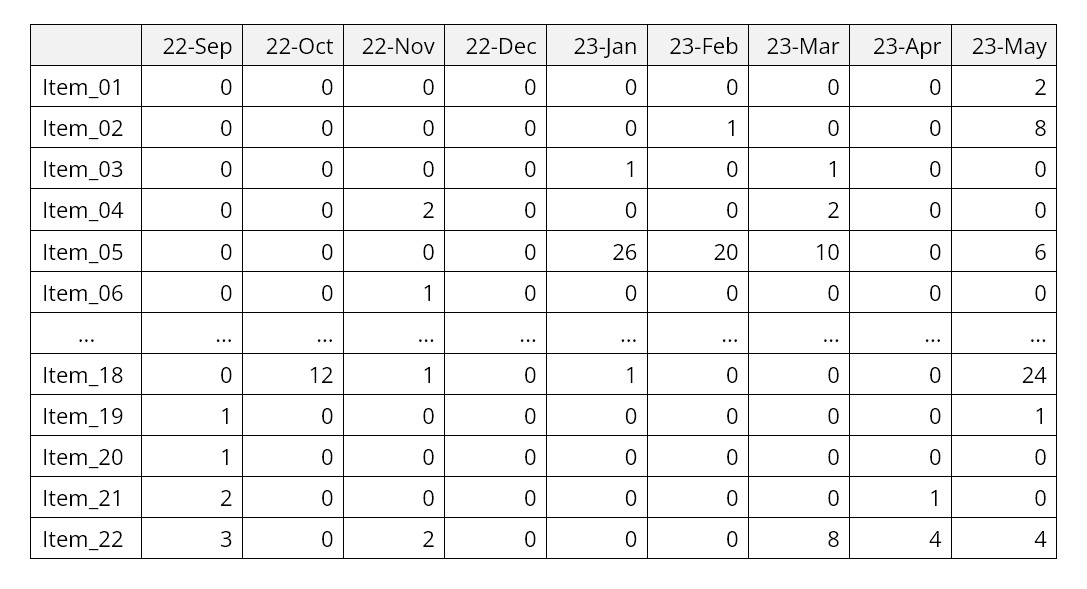
El paso 5 puede variar según los objetivos del usuario. Calcular el MTBF es estándar. Elija otros que se adapten al problema. Además de las estadísticas de resumen proporcionadas por el paso 5, se pueden trazar ejecuciones de simulación individuales para desarrollar la intuición sobre la dinámica aleatoria del tiempo de actividad y el tiempo de inactividad de la máquina. La Figura 3 muestra un ejemplo de una sola máquina que muestra ciclos alternos de tiempo de actividad y tiempo de inactividad que dan como resultado el tiempo de actividad del 85%.
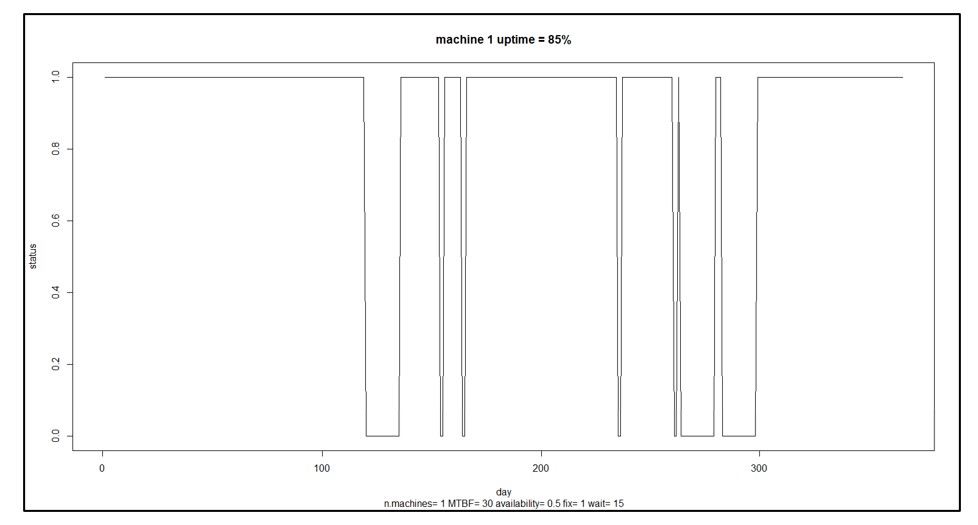
Figura 3 Un escenario de muestra para una sola máquina
Beneficios de los modelos de confiabilidad de la máquina
En la Figura 3, la máquina está funcionando 85% del tiempo. Eso puede no ser lo suficientemente bueno. Es posible que tenga algunas ideas sobre cómo mejorar la confiabilidad de la máquina, por ejemplo, tal vez pueda mejorar la confiabilidad del componente 3 comprando una versión mejor y más nueva de un proveedor diferente. ¿Cuánto ayudaría eso? Eso es difícil de adivinar: el componente 3 puede ser solo uno de varios y quizás no el eslabón más débil, y cuánto vale el cambio depende de qué tan mejor sea el nuevo. Tal vez debería desarrollar una especificación para el componente 3 que luego pueda comprar a proveedores potenciales, pero ¿cuánto tiempo tiene que durar el componente 3 para tener un impacto material en el MTBF de la máquina?
Aquí es donde vale la pena tener un modelo. Sin un modelo, estás confiando en conjeturas. Con un modelo, puede convertir la especulación sobre situaciones hipotéticas en estimaciones precisas. Por ejemplo, podría analizar cómo un aumento de 10% en MTBF para el componente 3 se traduciría en una mejora en MTBF para toda la máquina.
Como otro ejemplo, suponga que tiene siete máquinas que producen un producto importante. Calcula que debe dedicar seis de las siete para cumplir con un pedido importante de su gran cliente, dejando una máquina para manejar la demanda de una cantidad de clientes pequeños misceláneos y para servir como repuesto. Se podría usar un modelo de confiabilidad para cada máquina para estimar las probabilidades de varias contingencias: las siete máquinas funcionan y la vida es buena; seis máquinas funcionan para que al menos puedas mantener contento a tu cliente clave; solo funcionan cinco máquinas, así que tienes que negociar algo con tu cliente clave, etc.
En resumen, los modelos de probabilidad de fallas de máquinas o componentes pueden proporcionar la base para convertir los datos de tiempo de falla en decisiones comerciales inteligentes.
Leer más sobre Maximice el tiempo de actividad de la máquina con el modelado probabilístico
Leer más sobre Pronóstico probabilístico para demanda intermitente