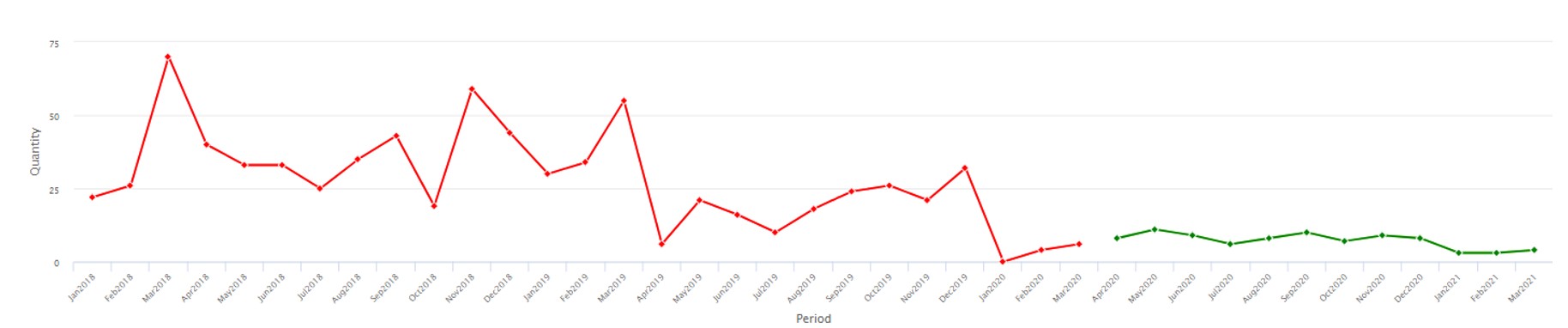
La verificación y validación de datos son esenciales para el éxito de la implementación de software que realiza análisis estadísticos de datos, como Smart IP&O. Este artículo describe el problema y sirve como una guía práctica para hacer el trabajo correctamente, especialmente para el usuario de la nueva aplicación.
Cuanta menos experiencia tenga su organización en la validación de transacciones históricas o atributos maestros de artículos, más probable es que haya problemas o errores con la entrada de datos en el ERP que hasta ahora han pasado desapercibidos. La regla de basura que entra, basura que sale significa que debe priorizar este paso del proceso de incorporación del software o correr el riesgo de demoras y posibles fallas en la generación de retorno de la inversión.
En última instancia, la mejor persona para confirmar que los datos en su ERP se ingresan correctamente es la persona que conoce el negocio y puede afirmar, por ejemplo, "esta parte no pertenece a ese grupo de productos". Esa suele ser la misma persona que abrirá y usará Smart. Aunque un administrador de base de datos o soporte de TI también puede desempeñar un papel clave al poder decir: "Esta parte fue asignada a ese grupo de productos en diciembre pasado por Jane Smith". Asegurarse de que los datos sean correctos puede no ser una parte habitual de su trabajo diario, pero se puede dividir en pequeñas tareas manejables para las que un buen director de proyectos asignará el tiempo y los recursos para completar.
El proveedor del software de planificación de la demanda que recibe los datos también tiene una función. Confirmarán que los datos sin procesar se ingirieron sin problemas. El proveedor también puede identificar anomalías en los archivos de datos sin procesar que apuntan a la necesidad de validación. Pero confiar en el proveedor de software para asegurarle que los datos se ven bien no es suficiente. No desea descubrir, después de la puesta en marcha, que no puede confiar en la salida porque algunos de los datos "no tienen sentido".
Cada paso en el flujo de datos necesita verificación y validación. La verificación significa que los datos en un paso siguen siendo los mismos después de pasar al siguiente paso. La validación significa que los datos son correctos y utilizables para el análisis.
El flujo de datos más común se ve así:
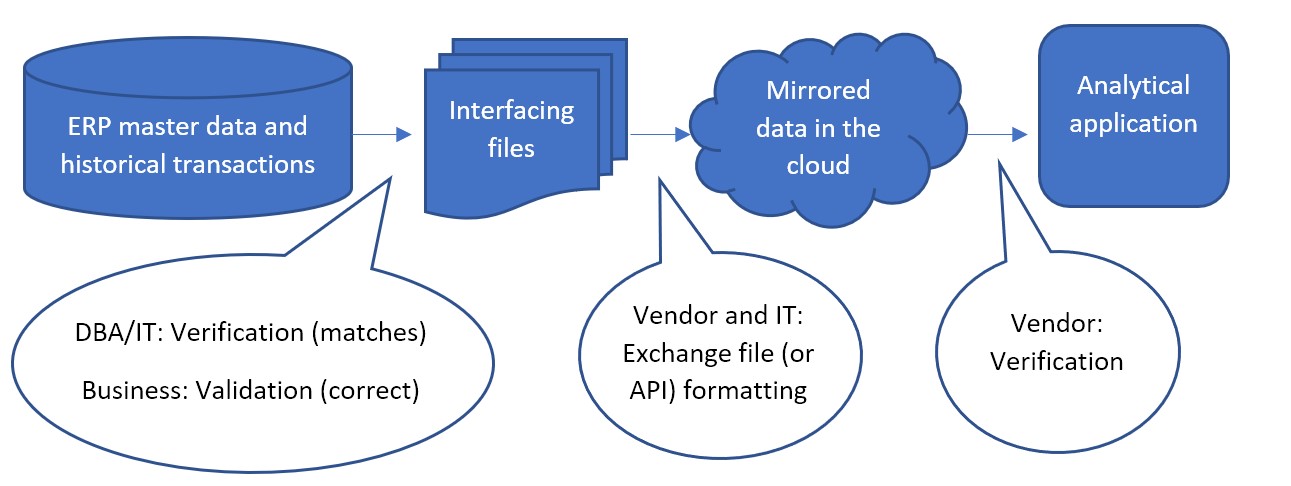
Con menos frecuencia, el primer paso entre los datos maestros de ERP y los archivos de interfaz a veces se puede omitir, donde los archivos no se utilizan como interfaz. En cambio, una API creada por TI o el proveedor de software de optimización de inventario es responsable de que los datos se escriban directamente desde el ERP a la base de datos reflejada en la nube. El proveedor trabajaría con TI para confirmar que la API funciona como se esperaba. Pero el primer paso de validación, incluso en ese caso, todavía se puede realizar. Después de ingerir los datos, el proveedor puede hacer que los datos reflejados estén disponibles en archivos para la verificación de DBA/TI y la validación comercial.
La confirmación de que los datos duplicados en la nube completan el flujo hacia la aplicación es responsabilidad del proveedor del software como servicio. Los proveedores de SaaS prueban continuamente que el software funcione correctamente entre la aplicación de front-end que ven sus suscriptores y los datos de back-end en la base de datos en la nube. Si los suscriptores todavía piensan que los datos no tienen sentido en la aplicación incluso después de validar los archivos de interfaz antes de ponerlos en marcha, ese es un problema que se debe plantear con el servicio de atención al cliente del proveedor.
Independientemente de cómo se obtengan los archivos de interfaz, la mayor parte de la verificación y validación recae en el director del proyecto y su equipo. Deben realizar una prueba de los archivos de interfaz para confirmar:
- Coinciden con los datos del ERP. Y que se extrajeron todos y solo los datos del ERP que era necesario extraer para su uso en la aplicación.
- Nada “salta” a la empresa como incorrecto para cada uno de los tipos de información en los datos
- Están formateados como se esperaba.
Tareas de verificación de DBA/TI
- Probar el extracto:
El paso de verificación de TI se puede realizar con varias herramientas, comparando archivos o importando archivos a la base de datos como tablas temporales y uniéndolos con los datos originales para confirmar una coincidencia. TI puede depender de una consulta para extraer los datos solicitados en un archivo, pero ese archivo puede no coincidir. La existencia de delimitadores o retornos de línea dentro de los valores de datos puede hacer que un archivo sea diferente de su tabla de base de datos original. Esto se debe a que el archivo se basa en gran medida en delimitadores y retornos de línea para identificar campos y registros, mientras que la tabla no se basa en esos caracteres para definir su estructura.
- Sin malos personajes:
Los campos de entrada de datos de forma libre en el ERP, como las descripciones de productos, a veces pueden contener retornos de línea, tabuladores, comas y/o comillas dobles que pueden afectar la estructura del archivo de salida. No se deben permitir retornos de línea en valores que se extraerán a un archivo. Los caracteres iguales al delimitador se deben eliminar durante la extracción o, de lo contrario, se debe usar un delimitador diferente.
Consejo: si las comas son el delimitador de archivo, los números superiores a 999 no se pueden extraer con una coma. Use "1000" en lugar de "1,000".
- Confirmar los filtros:
La otra forma en que los extractos de consulta pueden arrojar resultados inesperados es si las condiciones de la consulta se ingresan incorrectamente. La forma más sencilla de evitar las cláusulas "where" erróneas es no usarlas. Extraiga todos los datos y permita que el proveedor filtre algunos registros de acuerdo con las reglas proporcionadas por la empresa. Si esto produce archivos de extracción tan grandes que se dedica demasiado tiempo informático al intercambio de datos, el equipo de DBA/TI debe reunirse con la empresa para confirmar exactamente qué filtros en los datos se pueden aplicar para evitar el intercambio de registros que no tienen sentido para el solicitud.
Consejo: Tenga en cuenta que la información de activo/inactivo o del ciclo de vida del elemento no debe utilizarse para filtrar registros. Esta información debe enviarse a la aplicación para que sepa cuándo un elemento se vuelve inactivo.
- Se consistente:
El proceso de extracción debe producir archivos de formato consistente cada vez que se ejecuta. Los nombres de archivo, los nombres de campo y la posición, el delimitador y el nombre de la hoja de Excel si se usa Excel, los formatos numéricos y los formatos de fecha, y el uso de comillas alrededor de los valores nunca deben diferir de una ejecución del extracto de un día a otro. Se debe preparar y utilizar un informe de no intervención o un procedimiento almacenado para cada ejecución del extracto.
Fondo de validación comercial
A continuación se desglosa cada paso de validación en consideraciones, específicamente en el caso en que el proveedor haya proporcionado un formato de plantilla para los archivos de interfaz donde cada tipo de información se proporciona en su propio archivo. Los archivos enviados desde su ERP a Smart están formateados para exportarlos fácilmente desde el ERP. Ese tipo de formato hace que la comparación con el ERP sea un trabajo relativamente simple para TI, pero puede ser más difícil de interpretar para el negocio. La mejor práctica es manipular los datos del ERP, ya sea mediante el uso de tablas dinámicas o similar en una hoja de cálculo. TI puede ayudar proporcionando archivos de datos reformateados para que la empresa los revise.
Para profundizar en los archivos de interfaz, deberá comprenderlos. El proveedor proporcionará una plantilla precisa, pero generalmente los archivos de interfaz consisten en tres tipos: datos de catálogo, atributos de artículos y datos transaccionales.
- Los datos del catálogo contienen identificadores y sus atributos. Los identificadores suelen ser para productos, ubicaciones (que podrían ser plantas o almacenes), sus clientes y sus proveedores.
- Los atributos de artículo contienen información sobre productos en ubicaciones que se necesitan para el análisis de la combinación de producto y ubicación. Tal como:
- Política de reabastecimiento actual en forma de mínimo y máximo, punto de reorden o período de revisión y orden hasta el valor o stock de seguridad
- Asignación de proveedor principal y tiempo de entrega nominal y costo por unidad de ese proveedor
- Requisitos de cantidad de pedido, como cantidad mínima de pedido, tamaño de lote de fabricación o múltiplos de pedido
- Estado activo/inactivo de la combinación de producto/ubicación o indicadores que identifican su estado en su ciclo de vida, como pre-obsoleto
- Atributos para agrupar o filtrar, como comprador/planificador asignado o categoría de producto
- Información de inventario actual, como cantidades disponibles, en pedido y en tránsito.
- Los datos transaccionales contienen referencias a identificadores junto con fechas y cantidades. Como la cantidad vendida en una orden de venta de un producto, en una ubicación, para un cliente, en una fecha. O la cantidad colocada en la orden de compra de un producto, en una ubicación, de un proveedor, en una fecha. O la cantidad utilizada en una orden de trabajo de un producto componente en una ubicación en una fecha.
Validación de datos del catálogo
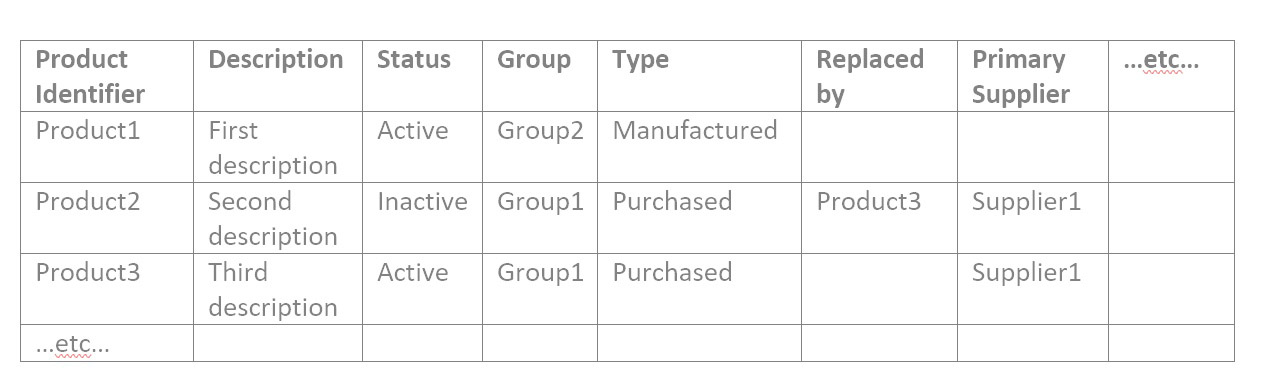
Teniendo en cuenta primero los datos del catálogo, es posible que tenga archivos de catálogo similares a estos ejemplos:
| Identificador de ubicación |
Descripción |
Región |
Ubicación de origen |
etc… |
| Ubicación1 |
Primera ubicación |
Norte |
|
|
| Ubicación2 |
Segunda ubicación |
Sur |
Ubicación1 |
|
| Ubicación3 |
Tercera ubicación |
Sur |
Ubicación1 |
|
| …etc… |
|
|
|
|
| Identificador de cliente |
Descripción |
Vendedor |
Enviar desde la ubicación |
etc… |
| Cliente1 |
primer cliente |
jane |
Ubicación1 |
|
| Cliente2 |
segundo cliente |
jane |
Ubicación3 |
|
| Cliente3 |
tercer cliente |
José |
Ubicación2 |
|
| …etc… |
|
|
|
|
| Identificador de proveedor |
Descripción |
Estado |
Días típicos de tiempo de entrega |
etc… |
| Proveedor1 |
primer proveedor |
Activo |
18 |
|
| Proveedor2 |
Segundo proveedor |
Activo |
60 |
|
| Proveedor3 |
Tercer Proveedor |
Activo |
5 |
|
| …etc… |
|
|
|
|
1: Comprobar un recuento razonable de registros de catálogo
Para cada archivo de datos del catálogo, ábralo en una herramienta de hoja de cálculo como Hojas de cálculo de Google o MS Excel. Responde estas preguntas:
- ¿Está el récord en el estadio de béisbol? Si tiene alrededor de 50 000 productos, no debería haber solo 10 000 filas en su archivo.
- Si es un archivo corto, tal vez el archivo de ubicación, puede confirmar exactamente que todos los Iidentificadores esperados están en él.
- Filtre por cada valor de atributo y confirme nuevamente que el recuento de registros con ese valor de atributo tenga sentido.
2: Comprobar la exactitud de los valores en cada campo de atributo
Alguien que sepa cuáles son los productos y qué significan los grupos necesita tomarse el tiempo para confirmar que realmente es correcto, para todos los atributos de todos los datos del catálogo.
Por lo tanto, si su archivo de producto contiene los atributos como en el ejemplo anterior, filtraría por Estado de activo y verificaría que todos los productos resultantes estén realmente activos. Luego filtre por Estado de Inactivo y verifique que todos los productos resultantes estén realmente inactivos. Luego filtre por el primer valor de Grupo y confirme que todos los productos resultantes estén en ese grupo. Repita para Group2 y Group3, etc. Luego repita para cada atributo en cada archivo.
Puede ayudar hacer esta validación con una comparación con un informe ya existente y confiable. Si tiene otra hoja de cálculo que muestra productos por grupo por cualquier motivo, puede comparar los archivos de interfaz con ella. Es posible que deba familiarizarse con la función BUSCARV que ayuda con la comparación de hojas de cálculo.
Validación de datos de atributos de artículos
1: Comprobar un recuento razonable de registros de artículos
La confirmación de los datos de los atributos del artículo es similar a los datos del catálogo. Confirme que el conteo de combinación de producto/ubicación tenga sentido en total y para cada uno de los atributos únicos del artículo, uno por uno. Este es un archivo de datos de elementos de ejemplo:
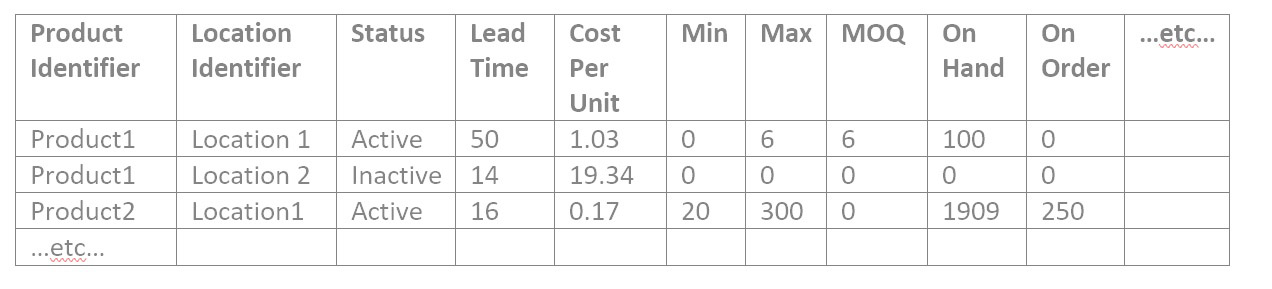
2: Encuentra y explica números raros en el archivo del artículo
Suele haber muchos valores numéricos en los atributos del artículo, por lo que los números "raros" merecen una revisión. Para validar los datos de un atributo numérico en cualquier archivo, busque dónde está el número:
- falta por completo
- igual a cero
- Menos que cero
- Más que la mayoría de los demás, o menos que la mayoría de los demás (ordenar por esa columna)
- No es un número en absoluto, cuando debería ser
Una consideración especial de los archivos que no son archivos de catálogo es que es posible que no muestren las descripciones de los productos y ubicaciones, solo sus identificadores, lo que puede no tener sentido para usted. Puede insertar columnas para contener los descriptores de productos y ubicaciones que está acostumbrado a ver y completarlos en la hoja de cálculo para ayudarlo en su trabajo. La función BUSCARV también funciona para esto. Ya sea que tenga o no otro informe para comparar el archivo de artículos, tiene los archivos de catálogo para productos y ubicación que muestran tanto el identificador como la descripción de cada fila.
3: Verificación al azar
Si le frustra descubrir que hay demasiados valores de atributo para verificar manualmente en un período de tiempo razonable, la verificación puntual es una solución. Se puede hacer de una manera que pueda detectar cualquier problema. Para cada atributo, obtenga una lista de los valores únicos en cada columna. Puede copiar una columna en una hoja nueva y luego usar la función Eliminar duplicados para ver la lista de valores posibles. Con eso:
- Confirme que no hay valores de atributos presentes que no deberían estar presentes.
- Puede ser más difícil recordar qué valores de atributo faltan que deberían estar allí, por lo que puede ser útil buscar otra fuente para recordarlo. Por ejemplo, si están presentes los grupos 1 a 12, puede consultar otra fuente para recordar si estos son todos los grupos posibles. Incluso si no se requiere para los archivos de interfaz para la aplicación, puede ser fácil para TI extraer una lista de todos los grupos posibles que están en su ERP que puede usar para el ejercicio de validación. Si encuentra valores adicionales o faltantes que no espera, lleve un ejemplo de cada uno a TI para investigar.
- Ordene alfabéticamente y explore hacia abajo para ver si dos valores son similares pero ligeramente diferentes, tal vez solo en la puntuación, lo que podría significar que un registro tenía los datos del atributo ingresados incorrectamente.
Para cada tipo de artículo, tal vez uno de cada grupo de productos y/o ubicación, verifique que todos sus atributos en cada archivo sean correctos o al menos pase una verificación de cordura. Cuanto más pueda verificar al azar de una amplia gama de elementos, es menos probable que tenga problemas después de la puesta en marcha.
Validación de datos transaccionales
Todos los archivos transaccionales pueden tener un formato similar a este:

1: Encuentra y explica números extraños en cada archivo transaccional
Estos deben verificarse en busca de números "raros" en el campo Cantidad. Luego puede proceder a:
- Filtre las fechas fuera del rango que espera o las que faltan por completo.
- Encuentre dónde faltan los identificadores de transacción y los números de línea. No deberían serlo.
- Si hay más de un registro para una determinada combinación de ID de transacción y número de línea de transacción, ¿es un error? Dicho de otra manera, ¿deberían sumarse las cantidades de los registros duplicados o se trata de una doble contabilización?
2: Cantidades sumadas de verificación de cordura
Realice una verificación de cordura filtrando a un producto en particular con el que esté familiarizado, y filtre a un rango de fechas relacionado, como el mes pasado o el año pasado, y sume las cantidades. ¿Es esa cantidad total lo que esperaba para ese producto en ese período de tiempo? Si tiene información sobre el uso total de una ubicación, puede dividir los datos de esa manera para sumar las cantidades y compararlas con lo que espera. Las tablas dinámicas son útiles para la verificación de datos transaccionales. Con ellos, puede ver los datos como:
| Producto |
Año |
Cantidad Total |
| prod1 |
2022 |
9,034 |
| prod1 |
2021 |
8,837 |
| etc. |
|
|
El total anual de los productos puede ser fácil de verificar si conoce bien los productos. O puede BUSCARV para agregar atributos, como un grupo de productos, y pivotar sobre eso para ver un nivel superior que le resulte más familiar:
| Grupo de productos |
Año |
Cantidad Total |
| Grupo 1 |
2022 |
22,091 |
| Grupo 2 |
2021 |
17,494 |
| etc. |
|
|
3: Conteo de verificación de cordura de los registros
Puede ser útil mostrar un recuento de transacciones en lugar de una suma de cantidades, especialmente para datos de órdenes de compra. Tal como:
| Producto |
Año |
Número de órdenes de compra |
| prod1 |
2022 |
4 |
| prod1 |
2021 |
1 |
| etc. |
|
|
Y/o el mismo resumen en un nivel superior, como:
| Grupo de productos |
Año |
Número de órdenes de compra |
| Grupo 1 |
2022 |
609 |
| Grupo 2 |
2021 |
40 |
| etc. |
|
|
4: Comprobación puntual
La verificación puntual de la corrección de una sola transacción, para cada tipo de artículo y cada tipo de transacción, completa la diligencia debida. Preste especial atención a qué fecha está vinculada a la transacción y si es adecuada para el análisis. Las fechas pueden ser una fecha de creación, como la fecha en que un cliente le hizo un pedido, o una fecha de promesa, como la fecha en que esperaba entregar el pedido del cliente en el momento de crearlo, o una fecha de cumplimiento, cuando realmente entregó en el orden. A veces, una fecha prometida se modifica días después de crear el pedido si no se puede cumplir. Asegúrese de que la fecha de uso refleje más fielmente la demanda real del producto por parte del cliente.
Qué hacer con los datos incorrectos
Si las entradas erróneas son pocas o únicas, puede editar los registros de ERP a mano a medida que se encuentran, limpiando los atributos de su catálogo, incluso después de la puesta en marcha de la aplicación. Pero si grandes franjas de atributos o cantidades de transacciones están desactivadas, esto puede impulsar un proyecto interno para volver a ingresar los datos correctamente y posiblemente cambiar o comenzar a documentar el proceso que debe seguirse cuando se ingresan nuevos registros en su ERP.
Se debe tener cuidado para evitar un retraso demasiado prolongado en la implementación de la aplicación SaaS mientras se esperan atributos limpios. Divida el trabajo en partes y use la aplicación para analizar primero los datos limpios, de modo que el proyecto de limpieza de datos ocurra en paralelo con la obtención de valor de la nueva aplicación.